python实现截图识别文字v2.0[脱离开发环境]
发布时间:2024年01月19日
目录
🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发、数据结构和算法,初步涉猎Python人工智能开发和前端开发。
🦅主页:@逐梦苍穹📕所属专栏:项目
🍔您的一键三连,是我创作的最大动力🌹
1、简介
这个程序创建了一个屏幕截图工具的GUI应用程序,允许用户选择区域截图并进行文字识别。
它解决了以下问题:
- 提供了一个GUI界面,让用户选择屏幕上的区域进行截图。
- 使用Tesseract OCR进行文字识别,将截取的文本复制到剪贴板。
- 根据配置文件中的设置,可以自动删除截图。
- 它比微信提取文字更精确
下面是对比情况:
 ?
?
2、如何使用
首先会得到一个初始的文件夹,各个文件的作用如下所示(未提及的文件均不可动):
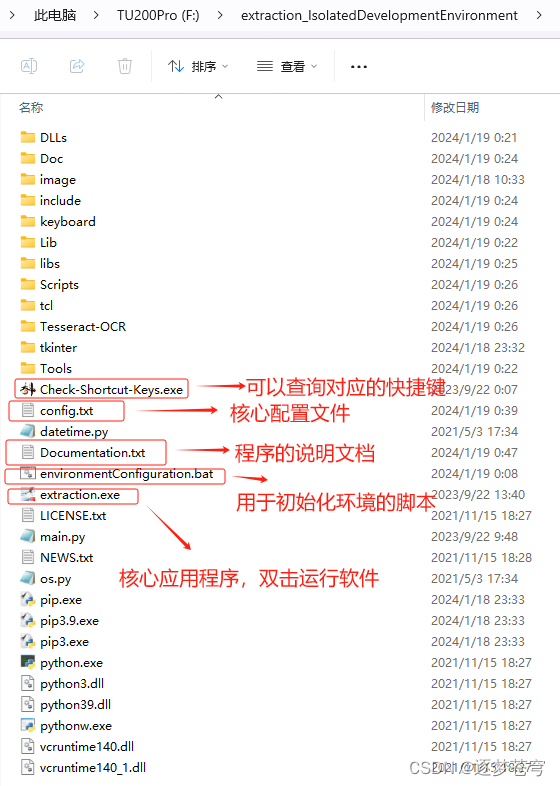 ?
?
切记:仔细查看说明文档!
执行初始化脚本的过程,当看见successfully则表示成功!
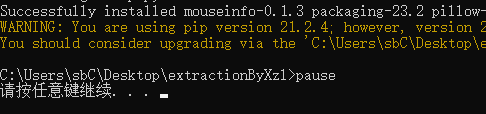
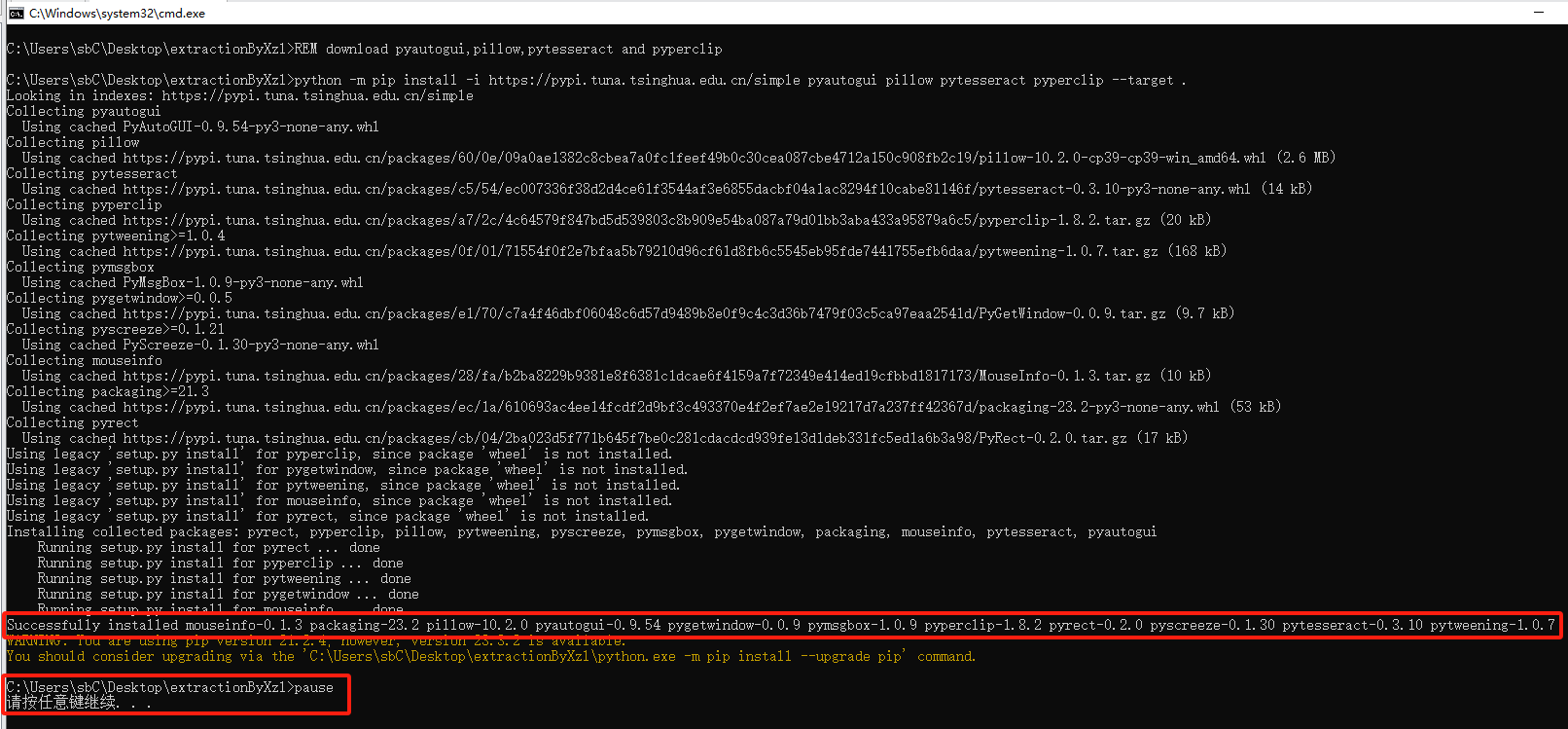
执行了初始化准备环境之后,得到的文件夹结果是:
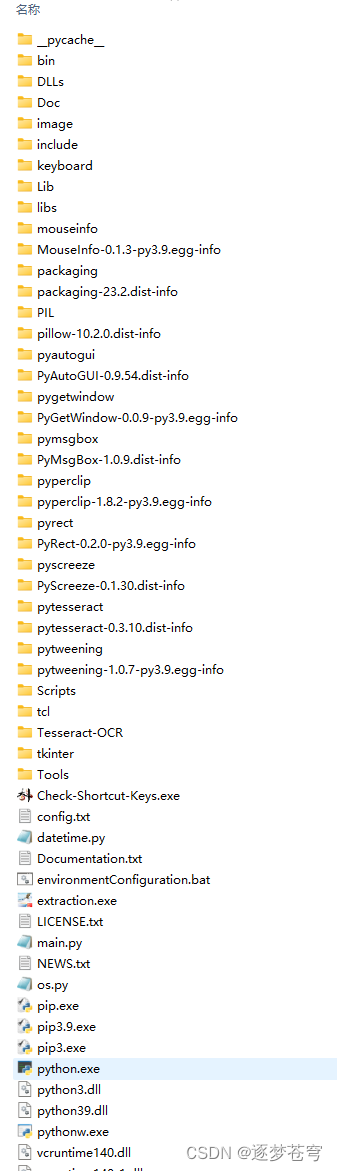 ?
?
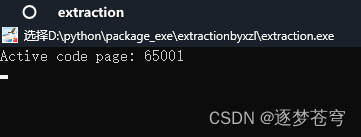
运行了extraction.exe之后会得到一个窗口(这个用处不大):
 ?
?
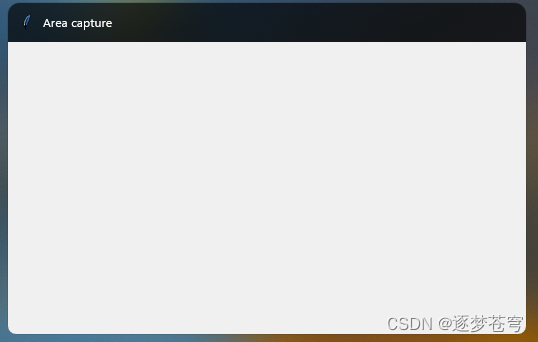
看到这个就证明运行成功了。接下来就可以双击设置好的快捷键,开始截图:
 ?
?
 ?
?
这个就是截图的应用程序。
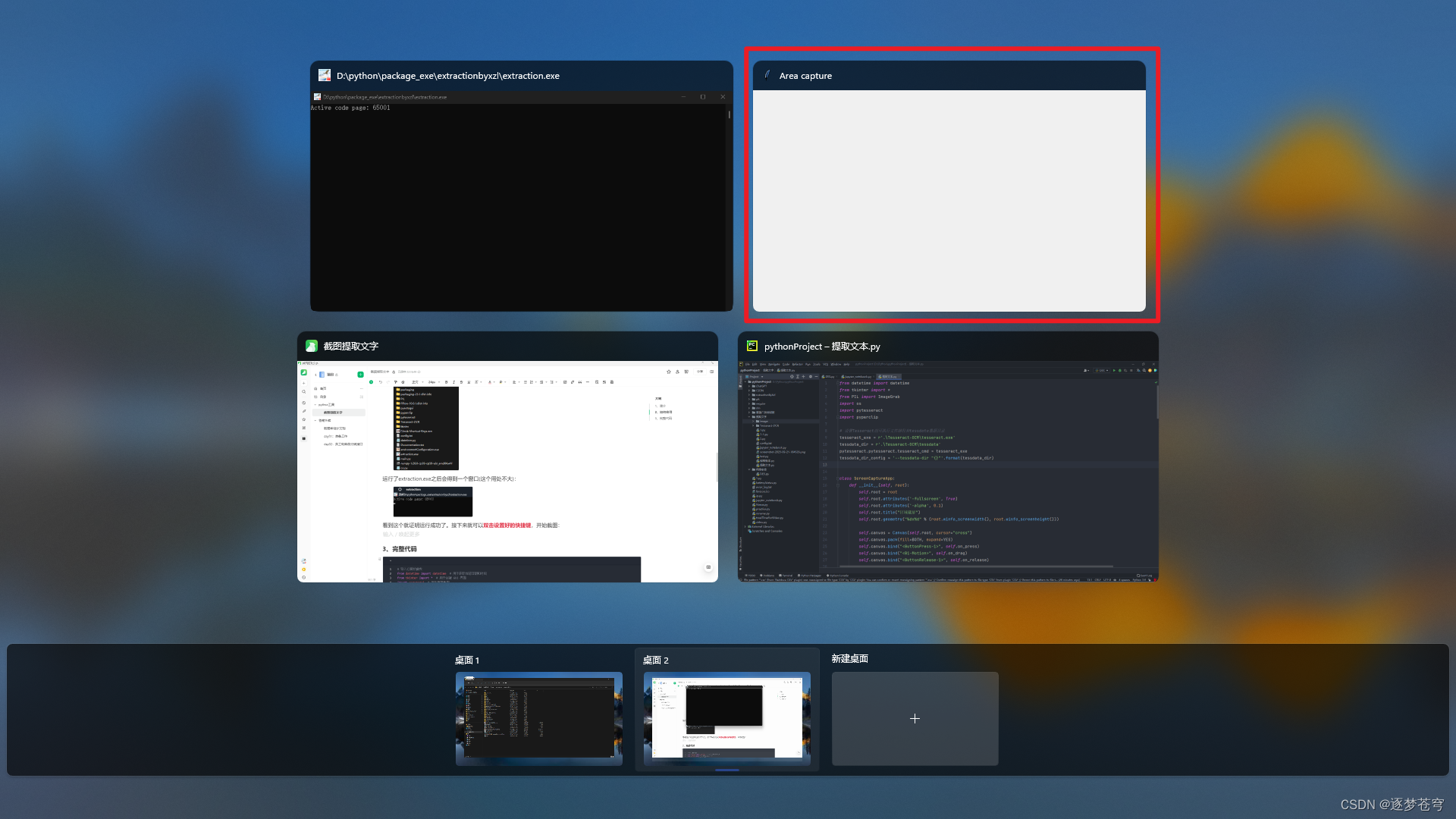
如果双击快捷键之后截图界面没有出来,则在自己电脑的状态栏点击一下打开即可(右边那个就是截图窗口):
 ?
?
3、完整代码
完整代码如下,代码即注释:
# 导入必要的模块
from datetime import datetime # 用于获取当前日期和时间
from tkinter import * # 用于创建 GUI 界面
import pyautogui # 用于屏幕截图
from PIL import ImageGrab # 用于处理图像数据
import os # 用于文件和目录操作
import pytesseract # 用于文字识别
import pyperclip # 用于剪贴板操作
# 设置 Tesseract OCR 的路径和配置
tesseract_exe = r'.\Tesseract-OCR\tesseract.exe'
tessdata_dir = r'.\Tesseract-OCR\tessdata'
pytesseract.pytesseract.tesseract_cmd = tesseract_exe
tessdata_dir_config = '--tessdata-dir "{}"'.format(tessdata_dir)
# 创建一个名为 ScreenCaptureApp 的类
class ScreenCaptureApp:
def __init__(self, root):
# 初始化应用程序的根窗口
self.root = root
self.root.attributes('-fullscreen', True) # 设置窗口全屏
self.root.attributes('-alpha', 0.1) # 设置窗口透明度
self.root.title("Area capture") # 设置窗口标题
# 获取屏幕的宽度和高度
self.screen_width, self.screen_height = pyautogui.size()
# 创建一个 Canvas 控件用于显示截图区域
self.canvas = Canvas(self.root, cursor="cross")
self.canvas.pack(fill=BOTH, expand=YES)
# 绑定鼠标事件处理函数
self.canvas.bind("<ButtonPress-1>", self.on_press)
self.canvas.bind("<B1-Motion>", self.on_drag)
self.canvas.bind("<ButtonRelease-1>", self.on_release)
# 初始化一些坐标和变量
self.start_x = None
self.start_y = None
self.end_x = None
self.end_y = None
self.rect = None
self.mask_rect = None
self.image_path = None
# 更新窗口大小
self.update_window_size()
# 更新窗口大小
def update_window_size(self):
screen_width = self.root.winfo_screenwidth()
screen_height = self.root.winfo_screenheight()
self.root.geometry("%dx%d" % (screen_width, screen_height))
# 鼠标按下事件处理函数
def on_press(self, event):
self.start_x = self.canvas.canvasx(event.x)
self.start_y = self.canvas.canvasy(event.y)
if self.rect:
self.canvas.delete(self.rect)
if self.mask_rect:
self.canvas.delete(self.mask_rect)
self.rect = self.canvas.create_rectangle(self.start_x, self.start_y, self.start_x, self.start_y, outline="blue", fill="blue",
stipple='gray25', width=3)
# 鼠标拖动事件处理函数
def on_drag(self, event):
cur_x = self.canvas.canvasx(event.x)
cur_y = self.canvas.canvasy(event.y)
self.canvas.coords(self.rect, self.start_x, self.start_y, cur_x, cur_y)
self.update_mask(cur_x, cur_y)
# 鼠标释放事件处理函数
def on_release(self, event):
self.end_x = self.canvas.canvasx(event.x)
self.end_y = self.canvas.canvasy(event.y)
# 计算截图区域的坐标
if self.start_x < self.end_x and self.start_y < self.end_y:
left = self.start_x
top = self.start_y
right = self.end_x
bottom = self.end_y
# ... (其他情况的计算省略)
# 使用 ImageGrab.grab 截取屏幕图像
screenshot = ImageGrab.grab(bbox=(left, top, right, bottom))
# 获取当前脚本的目录和当前日期时间
script_directory = os.path.dirname(os.path.abspath(__file__))
current_datetime = datetime.now().strftime("%Y-%m-%d-%H%M%S")
# 构建图像文件名
file_name = f"xzlScreenshot-{current_datetime}.png"
self.image_path = os.path.join(script_directory, "image/" + file_name)
# 保存截图到文件
screenshot.save(self.image_path)
# 配置 Tesseract OCR 参数
custom_config = r'--oem 3 --psm 6 -c preserve_interword_spaces=1'
# 使用 pytesseract 进行文字识别
text = pytesseract.image_to_string(screenshot, lang='+'.join(['eng', 'chi_sim']), config=f'--tessdata-dir "{tessdata_dir}" {custom_config}')
# 将识别结果复制到剪贴板
pyperclip.copy(text)
# 读取配置文件并检查是否需要自动删除截图
with open('config.txt', 'r', encoding="utf-8") as file:
content = file.read()
key_value_pairs = content.strip().split('\n')
for i in range(0, len(key_value_pairs)):
key = key_value_pairs[i].split('=')
value = key[1]
if str(key[0]) == "autoDeleteImg":
auto_delete_img_value = value
break
if int(auto_delete_img_value) == int(1):
if self.image_path:
os.remove(self.image_path)
# 关闭应用程序窗口
self.root.destroy()
# 更新遮罩效果
def update_mask(self, cur_x, cur_y):
if self.mask_rect:
self.canvas.delete(self.mask_rect)
self.mask_rect = self.canvas.create_rectangle(0, 0, self.root.winfo_screenwidth(), self.root.winfo_screenheight(), fill="black", )
self.canvas.tag_lower(self.mask_rect)
self.canvas.coords(self.mask_rect, self.start_x, self.start_y, cur_x, cur_y)
# 主函数,创建应用程序对象并运行
def main():
root = Tk()
app = ScreenCaptureApp(root)
root.mainloop()
# 检查脚本是否作为主程序运行
if __name__ == "__main__":
main()
4、免费下载
下载的安装包是不需要独立安装第三方模块以及环境的,都已经集成好了。
链接如下:
链接:https://pan.baidu.com/s/1X60c6Egl-CogSPOL2WTnbg?pwd=1234?
提取码:1234
5、说明文档
说明文档内容如下:
@Author: CSDN@逐梦苍穹
这是程序的说明文档。
条款和条件:
①这个应用程序是完全免费的,没有商业用途。
②本程序由"CSDN@逐梦苍穹"编写,CSDN博客账号:“https://blog.csdn.net/qq_60735796”
注意事项:
①程序存放的路径必须全是英文的
②所有级别的文件夹和目录名称之间不能有空格。
③各级文件夹和目录的字符中不允许使用汉字。
④最好不要在各级文件夹和目录中使用特殊字符。
使用说明:
①使用说明中未提及的文件夹,不得以任何方式删除或修改。
如果有任何更改,将影响程序的运行。
②如果您准备第一次运行这个程序,请先配置好config.txt文件的内容。
config.txt文件是这个应用程序的配置文件。存储为键值对。
(请记住,“=”左侧的内容不能修改)
原始参数信息如下:
autoDeleteImg=0
shortcutKeys=f2
LetterOfTheDriveWhereTheCurrentFileResides=D
CurrentFileAbsolutePath=D:\Python\package_exe\extractionByXzl
如果你在使用该程序识别文本并将其放入剪贴板之后,希望能够自动删除图像,请设置"autoDeleteImg = 1",否则将其设置为0。
如果您想修改使用的快捷键,需要设置"shortcutKeys"的值。
(如果您不知道如何设置快捷键"shortcutKeys"的值,请运行"Check-Shortcut-Keys.exe"程序。按下相应的键,控制台将向您展示如何编写快捷键的值!)
重要的是,你需要把"LetterOfTheDriveWhereTheCurrentFileResides"设置为当前文件夹存放的驱动器字母,并将"CurrentFileAbsolutePath"的值设置为当前文件夹的绝对路径!
③设置完以上参数后,双击"environmentConfiguration.bat"文件启动程序,执行程序环境的初始化操作。(该操作只需要第一次执行,以后不需要再次执行)
④初始化执行环境后,可以开始执行启动文件"extract.exe"
(这是应用程序的核心启动文件,相关功能由它启动)。
(出现“Active code page: 65001”表示成功)。
此时,双击您设置的快捷键,就可以开始截图和自动识别文本到剪切板。
⑤如果要识别的字符比较多,操作可能会比较慢。如果本地有python环境的,也可以看我之前这篇:
文章来源:https://blog.csdn.net/qq_60735796/article/details/135687196
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Qt弹框展示
- 华为机试真题实战应用【算法代码篇】-模拟消息队列(附python、C++和JAVA代码实现)
- Ubuntu系统环境搭建(九)——更新Ubuntu并同步网络时间
- 【持续学习系列(六)】《iCaRL》
- Linux基本命令
- 如何实现TAB切换时按钮变换样式
- 【MySQL】union (all) 后 order by 子查询排序不生效问题解决方案
- 【leetcode100-025】【链表/快慢指针】环形链表
- 【Java集合类篇】HashMap的数据结构是怎样的?
- 词嵌入位置编码的实现(基于pytorch)