Opencv计算机视觉的分类
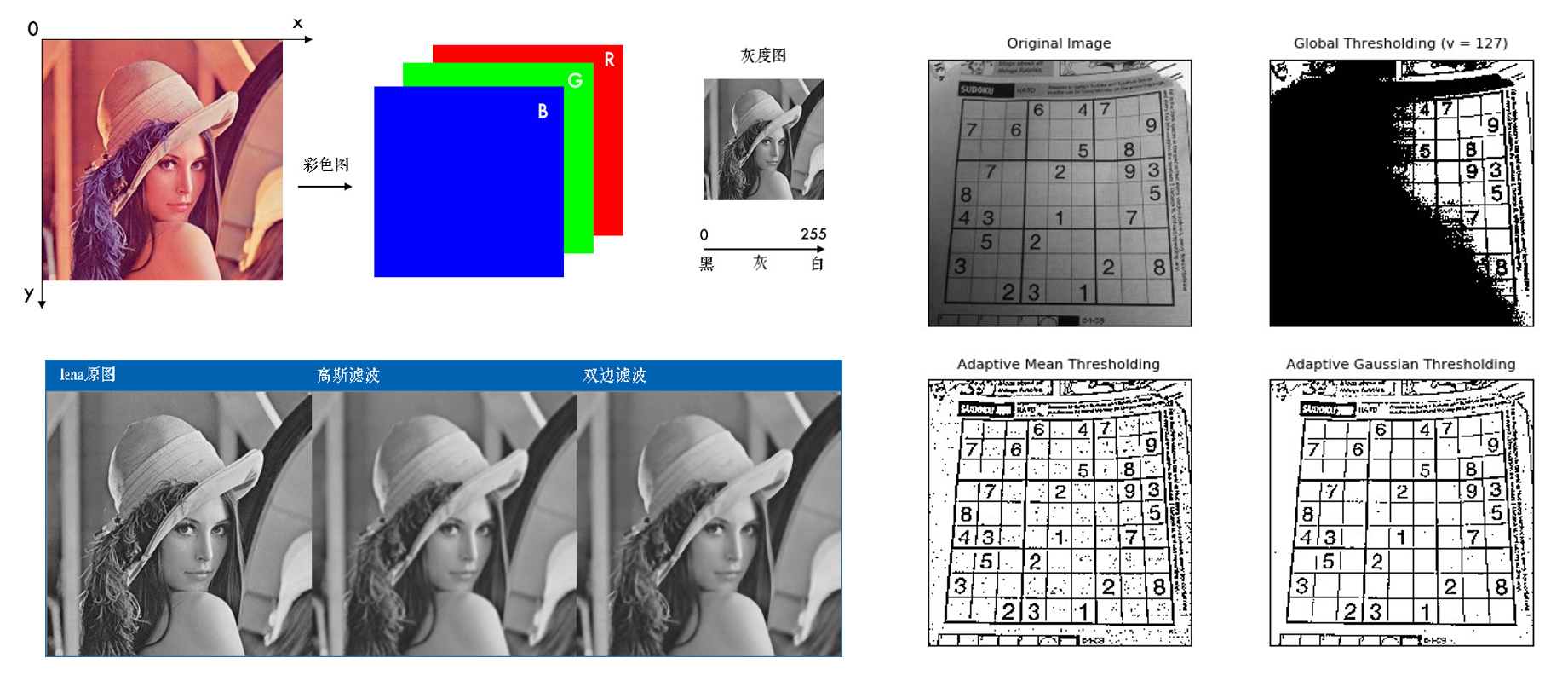
传统的计算机视觉可以使用Opencv等Python库,对图像进行简单的操作,例如对图像缩放、滤波、阈值分割等等。对于计算机来说,一张彩色图片就是一个三通道的矩阵,分别对应红绿蓝(RGB)三种颜色,通过改变颜色的数值(0-255)来显示出一张完整的彩色图片,传统的计算机视觉就是围绕这一个三维矩阵,比如设置一个颜色区间,进行过滤等等操作。
这一类视觉处理的方法,功能相对较弱一些,能够处理一些简单的应用场景,比如识别绿色物体,识别动态的物体等。但是对于背景复杂的实际场景中,很多问题都难以解决。
推荐Opencv教程地址:GitHub - CodecWang/opencv-python-tutorial: 📖 OpenCV-Python image processing tutorial for beginners
深度学习
通过人工智能对图像进行处理的算法有很多,其中最为经典的为卷积神经网络,对原始图像不停卷积运算,充分提取特征,最后输出想要的结果,这类方法经过实践的验证取得了非常不错的精度表现,在目前的很多硬件上,都能够跑出实时的效果。

当然,更多新型的视觉处理算法也涌现出来,比如最近比较火热的Transformer算法,最初应用于NLP(自然语言处理),最近科研者们发现它在视觉领域也展现出了非常不错的表现,很多领域下都取得了最佳的精度,突破了卷积神经网络的精度瓶颈。我们这期教程还是围绕卷积神经网络,这种经典的算法展开,仍然值得大家深入地学习。

计算机视觉任务的分类
分类(Classification)
分类任务是对整张图片进行分类,例如最为经典的猫狗分类。

猫狗分类就是让计算机对于我指定的图片进行归类,如果这张图片是猫,我把图片输入到模型后,我期望输出的就是猫这个类别。可以看到,分类任务是对整张图片的归类,如果一张图片里面既有猫,又有狗,那么显然分类无法完成,因为分类任务是不需要对物体定位的。分类任务是计算机视觉最简单的任务,实现的难度最低,当然功能也最为简单。
检测(Detection)

检测任务相对于分类任务,需要精确地对图像中的目标物体定位,一般用矩形框确定目标位置。如上图,一张图片中,有狗,有自行车,有汽车,对于检测任务,就需要精确地框出他们的位置,并判别类别。检测任务是对图像中的物体进行特征识别,相比分类任务难度有所提升,也是我们经常会有的需求,需要精确判定特征物体在画面中的位置,例如行人检测,人脸检测等等。
分割(Segmentation)

分割任务的难度再次增加,任务要求不仅需要确定位置,还需要勾勒出物体的轮廓,类似PS的抠图,过滤去背景。例如上图所示的工业读表,车道线分割等等,这类任务对于模型和算法的考验较大,在特定的场合中有一定的应用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 代码随想录算法训练营第五十三天| 1143.最长公共子序列、1035.不相交的线、53.最大子序和动态规划
- WinToUSB v8.5/WinToHDD v6.2
- 【C/C++】C语言的高级编程(内存分区,指针)
- 大数据开发之Hive(基本概念、安装、数据类型、DDL数据定义、DML数据操作)
- Codeforces Round 919 (Div. 2) | JorbanS
- 基数(Radix)排序
- 基于xgboost-LGBM-SVM的病人哮喘病识别检测 数据+代码
- PDF控件Spire.PDF for .NET【安全】演示:在 PDF 中添加或删除数字签名
- 分享一款超级无滴好用的eclipse代码自动提示补全插件
- Java Iterable和Iterator接口区别是什么?