【openwrt】【overlayfs】Openwrt系统overlayfs挂载流程
发布时间:2024年01月18日
overlayfs是一种叠加文件系统,在openwrt和安卓系统中都有很广泛的应用,overlayfs通常用于将只读根文件系统(rootfs)和可写文件系统(jffs2)进行叠加后形成一个新的文件系统,这个新的文件系统“看起来”是可读写的,这种做法的好处是:
- 对这个新文件系统的修改(删除也属于修改)都只保存在可写文件系统中,只读根文件系统不受任何影响
- 将可写文件系统格式化后,可以将整个文件系统恢复到初始状态(相当于只有只读根文件系统的状态)
- 减少flash擦写次数,延长设备使用寿命
下面就开始介绍openwrt系统中的overlayfs是如何挂载的,挂载过程可以分为2个部分:
- 只读根文件系统(rootfs)挂载过程
- overlayfs 挂载过程(包括可写文件系统(rootfs_data)挂载过程)
只读根文件系统(rootfs)挂载过程
kernel的启动流程大致如下:
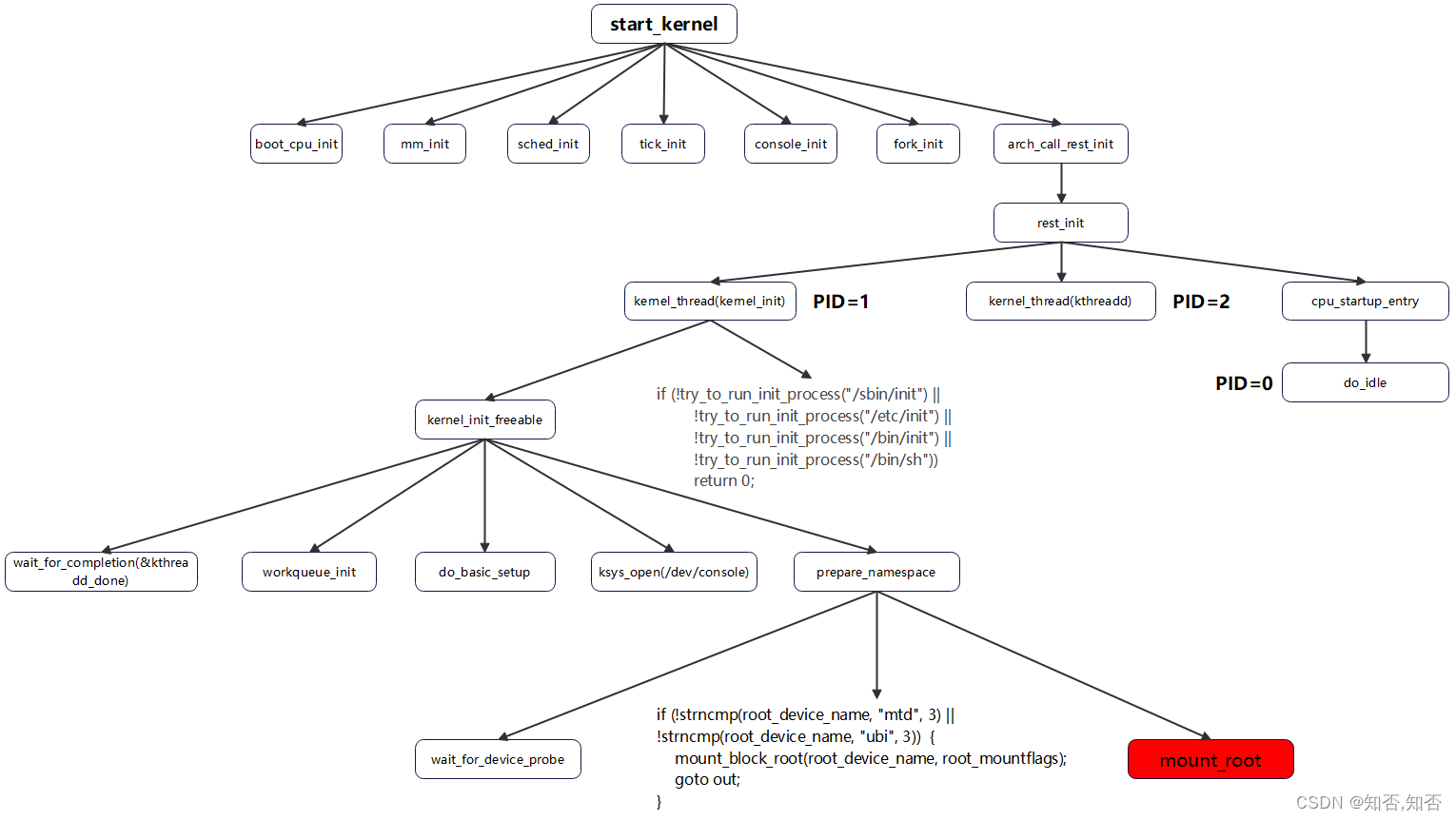
prepare_namespace
prepare_namespace负责根文件系统的挂载
void __init prepare_namespace(void)
{
int is_floppy;
if (root_delay) {
printk(KERN_INFO "Waiting %d sec before mounting root device...\n",
root_delay);
ssleep(root_delay);
}
wait_for_device_probe(); // 等待所有的设备初始化完成
md_run_setup();
if (saved_root_name[0]) {
root_device_name = saved_root_name;
if (!strncmp(root_device_name, "mtd", 3) ||
!strncmp(root_device_name, "ubi", 3)) {
mount_block_root(root_device_name, root_mountflags);
goto out;
}
ROOT_DEV = name_to_dev_t(root_device_name);
if (strncmp(root_device_name, "/dev/", 5) == 0)
root_device_name += 5;
}
if (initrd_load())
goto out;
/* wait for any asynchronous scanning to complete */
if ((ROOT_DEV == 0) && root_wait) {
printk(KERN_INFO "Waiting for root device %s...\n",
saved_root_name);
while (driver_probe_done() != 0 ||
(ROOT_DEV = name_to_dev_t(saved_root_name)) == 0)
msleep(5);
async_synchronize_full();
}
is_floppy = MAJOR(ROOT_DEV) == FLOPPY_MAJOR;
if (is_floppy && rd_doload && rd_load_disk(0))
ROOT_DEV = Root_RAM0;
mount_root();
out:
devtmpfs_mount("dev");
ksys_mount(".", "/", NULL, MS_MOVE, NULL);
ksys_chroot(".");
}
- root_delay:如果cmdline中有“rootdelay=xxx”,则调用ssleep延迟xxx秒,例如“rootdelay=10”,则延时10s
- wait_for_device_probe()是等待所有的设备probe完成,
- saved_root_name:如果cmdline中有“root=xxx”,则saved_root_name=xxx。在我当前的系统中
root=/dev/mmcblk1p65,所以saved_root_name=/dev/mmcblk1p65 - mount_block_root: 如果
root_device_name前三个字符是“ubi”或者“mtd”,则调用mount_block_root进行挂载根文件系统,这里主要是针对ubifs这一种文件系统进行特殊处理,因为ubifs根文件系统对应cmdline的参数一般是:ubi.mtd=1 root=ubi0:rootfs rootfstype=ubifs,而其他文件系统一般是root=/dev/xxx.saved_root_name会被赋值给root_device_name。 - ROOT_DEV:root_device_name设备对应的设备号(/dev/mmcblk1p65设备对应主设备号是259,次设备号是0)
- while (driver_probe_done() != 0): 等待所有
saved_root_name设备probe完成(dev/xxx节点被创建) - mount_root:开始挂载根文件系统
mount_root(内核层)
void __init mount_root(void)
{
#ifdef CONFIG_ROOT_NFS
if (ROOT_DEV == Root_NFS) {
if (!mount_nfs_root())
printk(KERN_ERR "VFS: Unable to mount root fs via NFS.\n");
return;
}
#endif
#ifdef CONFIG_CIFS_ROOT
if (ROOT_DEV == Root_CIFS) {
if (!mount_cifs_root())
printk(KERN_ERR "VFS: Unable to mount root fs via SMB.\n");
return;
}
#endif
#ifdef CONFIG_MTD_ROOTFS_ROOT_DEV
if (!mount_ubi_rootfs())
return;
#endif
#ifdef CONFIG_BLOCK
{
int err = create_dev("/dev/root", ROOT_DEV);
if (err < 0)
pr_emerg("Failed to create /dev/root: %d\n", err);
mount_block_root("/dev/root", root_mountflags);
}
#endif
}
- CONFIG_MTD_ROOTFS_ROOT_DEV 的作用是告诉 Linux 内核在引导过程中从哪个 MTD 设备加载根文件系统,一般支持NANDFlash的设备都会开启这个选项
- mount_ubi_rootfs() 尝试挂载
ubifs,如果挂载成功,则不再继续后续的挂载步骤。 - CONFIG_BLOCK是开启块设备子系统,对于绝大多数文件系统(EXT4、yaffs2、XFS、FAT等)都需要块设备子系统的支持。
- create_dev(“/dev/root”, ROOT_DEV) 创建了一个设备节点
/dev/root,/dev/root是根文件系统设备的抽象,因为它的设备号也是ROOT_DEV,前面有提到ROOT_DEV就是实际的根文件系统设备节点。这样做的好处是不用关心实际的根文件系统设备是什么,直接对/dev/root进行mount就可以实现根文件系统的挂载。 - mount_block_root(“/dev/root”, root_mountflags) 挂载
/dev/root
void __init mount_block_root(char *name, int flags)
{
struct page *page = alloc_page(GFP_KERNEL);
char *fs_names = page_address(page);
char *p;
char b[BDEVNAME_SIZE];
scnprintf(b, BDEVNAME_SIZE, "unknown-block(%u,%u)",
MAJOR(ROOT_DEV), MINOR(ROOT_DEV));
get_fs_names(fs_names);
retry:
for (p = fs_names; *p; p += strlen(p)+1) {
int err = do_mount_root(name, p, flags, root_mount_data);
switch (err) {
case 0:
goto out;
case -EACCES:
case -EINVAL:
continue;
}
/*
* Allow the user to distinguish between failed sys_open
* and bad superblock on root device.
* and give them a list of the available devices
*/
printk("VFS: Cannot open root device \"%s\" or %s: error %d\n",
root_device_name, b, err);
printk("Please append a correct \"root=\" boot option; here are the available partitions:\n");
printk_all_partitions();
#ifdef CONFIG_DEBUG_BLOCK_EXT_DEVT
printk("DEBUG_BLOCK_EXT_DEVT is enabled, you need to specify "
"explicit textual name for \"root=\" boot option.\n");
#endif
panic("VFS: Unable to mount root fs on %s", b);
}
if (!(flags & SB_RDONLY)) {
flags |= SB_RDONLY;
goto retry;
}
printk("List of all partitions:\n");
printk_all_partitions();
printk("No filesystem could mount root, tried: ");
for (p = fs_names; *p; p += strlen(p)+1)
printk(" %s", p);
printk("\n");
panic("VFS: Unable to mount root fs on %s", b);
out:
put_page(page);
}
- get_fs_names(fs_names) 获取根文件系统类型并存入变量 fs_names,fs_names中可能保存了很多个文件系统类型,他们是用
,隔开的。 - for (p = fs_names; *p; p += strlen§+1) 是依次尝试使用
fs_names里面的文件系统类型进行挂载 - do_mount_root(name, p, flags, root_mount_data) 是具体挂载过程,此处
name=/dev/root,一旦挂载成功则退出整个挂载步骤,不会再继续尝试其他文件系统类型。
static int __init do_mount_root(const char *name, const char *fs,
const int flags, const void *data)
{
struct super_block *s;
struct page *p = NULL;
char *data_page = NULL;
int ret;
if (data) {
/* init_mount() requires a full page as fifth argument */
p = alloc_page(GFP_KERNEL);
if (!p)
return -ENOMEM;
data_page = page_address(p);
/* zero-pad. init_mount() will make sure it's terminated */
strncpy(data_page, data, PAGE_SIZE);
}
ret = init_mount(name, "/root", fs, flags, data_page);
if (ret)
goto out;
init_chdir("/root");
s = current->fs->pwd.dentry->d_sb;
ROOT_DEV = s->s_dev;
printk(KERN_INFO
"VFS: Mounted root (%s filesystem)%s on device %u:%u.\n",
s->s_type->name,
sb_rdonly(s) ? " readonly" : "",
MAJOR(ROOT_DEV), MINOR(ROOT_DEV));
out:
if (p)
put_page(p);
return ret;
}
- data 是上一步传入的
root_mount_data变量,root_mount_data是cmdline 中 “rootflags=xxx” 参数=后面的部分,即挂载选项。如果不为空,则需要申请内存保存data - init_mount(name, “/root”, fs, flags, data_page) 将
/dev/root设备挂载到/root - init_chdir(“/root”) 将当前工作路径改为
/root - s = current->fs->pwd.dentry->d_sb 获取当前文件系统的超级块
- ROOT_DEV = s->s_dev 将超级块的设备号赋值给 ROOT_DEV
- 这时候可以看到如下内核打印,说明rootfs已经挂载成功
[ 2.337243] VFS: Mounted root (squashfs filesystem) readonly on device 259:0.
# device 259:0 对应设备
brw------- 1 root root 259, 0 Jan 1 1970 /dev/mmcblk1p65
overlayfs 挂载过程
在openwrt系统中,overlayfs 挂载需要使用 fstools工具。fstools并不是一个具体的tool,它包含了多个小工具,这些小工具都是运行在应用层的,这也说明了overlayfs是在应用层进行挂载的。
fstools
fstools实际上包括如下小工具:
- jffs2reset
- mount_root
- libfstools.so
除此之外,下列工具也放在fstools的包里面,它们是基于fstools开发出来的拓展工具,而且如果需要安装下面的工具,除了
使能CONFIG_PACKAGE_fstools=y之外,还需要使能对应的配置。
- block (CONFIG_PACKAGE_block-mount)
- blockd (CONFIG_PACKAGE_blockd)
- snapshot_tool (CONFIG_PACKAGE_snapshot-tool)
- ubi (CONFIG_PACKAGE_ubi-utils)
mount_root(应用层)
mount_root就是用来挂载overlayfs的工具,它支持4种模式:
- 默认(无参数):挂载overlayfs模式
- ram :挂载基于ram的overlayfs
- stop:获取
SHUTDOWN环境变量状态 - done:挂载结束后置文件系统状态位
//fstools-2022-06-02-93369be0/mount_root.c
int main(int argc, char **argv)
{
if (argc < 2)
return start(argc, argv);
if (!strcmp(argv[1], "ram"))
return ramoverlay();
if (!strcmp(argv[1], "stop"))
return stop(argc, argv);
if (!strcmp(argv[1], "done"))
return done(argc, argv);
return -1;
}
在oepnwrt系统运行第一个进程(1号进程)时,mount_root就会被调用。可以看到此时mount_root没有携带任何参数,所以它首先走的是start(argc, argv) 逻辑。
# openwrt/package/base-files/files/lib/preinit/80_mount_root
do_mount_root() {
mount_root
boot_run_hook preinit_mount_root
[ -f /sysupgrade.tgz -o -f /tmp/sysupgrade.tar ] && {
echo "- config restore -"
cp /etc/passwd /etc/group /etc/shadow /tmp
cd /
[ -f /sysupgrade.tgz ] && tar xzf /sysupgrade.tgz
[ -f /tmp/sysupgrade.tar ] && tar xf /tmp/sysupgrade.tar
missing_lines /tmp/passwd /etc/passwd >> /etc/passwd
missing_lines /tmp/group /etc/group >> /etc/group
missing_lines /tmp/shadow /etc/shadow >> /etc/shadow
rm /tmp/passwd /tmp/group /tmp/shadow
# Prevent configuration corruption on a power loss
sync
}
}
mount_root->start
static int
start(int argc, char *argv[1])
{
struct volume *root;
struct volume *data = volume_find("rootfs_data");
struct stat s;
if (!getenv("PREINIT") && stat("/tmp/.preinit", &s))
return -1;
if (!data) {
root = volume_find("rootfs");
volume_init(root);
ULOG_NOTE("mounting /dev/root\n");
mount("/dev/root", "/", NULL, MS_NOATIME | MS_REMOUNT, 0);
}
/* Check for extroot config in rootfs before even trying rootfs_data */
if (!mount_extroot("")) {
ULOG_NOTE("switched to extroot\n");
return 0;
}
/* There isn't extroot, so just try to mount "rootfs_data" */
volume_init(data);
switch (volume_identify(data)) {
case FS_NONE:
ULOG_WARN("no usable overlay filesystem found, using tmpfs overlay\n");
return ramoverlay();
case FS_DEADCODE:
/*
* Filesystem isn't ready yet and we are in the preinit, so we
* can't afford waiting for it. Use tmpfs for now and handle it
* properly in the "done" call.
*/
ULOG_NOTE("jffs2 not ready yet, using temporary tmpfs overlay\n");
return ramoverlay();
case FS_EXT4:
case FS_F2FS:
case FS_JFFS2:
case FS_UBIFS:
mount_overlay(data);
break;
case FS_SNAPSHOT:
mount_snapshot(data);
break;
}
return 0;
}
- volume_find(“rootfs_data”) 查询分区name为
rootfs_data的分区,这里最终调用的是volume>-driver->find(),不同类型的文件系统会有不同的实现,find()过程会初始化一个volume对象,但volume对象的成员信息有可能是不完整的,还需要在接下来的init()环节继续填充完整。 - volume_init(data) 初始化
volume对象,继续完善volume成员信息,这里最终调用的是volume>-driver->init() - volume_identify(data) 识别volume指向的分区的文件系统类型,如果是
FS_EXT4FS_F2FSFS_JFFS2FS_UBIFS这4种文件系统之一,接下来就会执行挂载overlayfs流程,这里最终调用的是volume>-driver->identify()
int mount_overlay(struct volume *v)
{
const char *overlay_mp = "/tmp/overlay";
char *mp, *fs_name;
int err;
if (!v)
return -1;
mp = find_mount_point(v->blk, 0);
if (mp) {
ULOG_ERR("rootfs_data:%s is already mounted as %s\n", v->blk, mp);
return -1;
}
err = overlay_mount_fs(v, overlay_mp);
if (err)
return err;
/*
* Check for extroot config in overlay (rootfs_data) and if present then
* prefer it over rootfs_data.
*/
if (!mount_extroot(overlay_mp)) {
ULOG_INFO("switched to extroot\n");
return 0;
}
switch (fs_state_get(overlay_mp)) {
case FS_STATE_UNKNOWN:
fs_state_set(overlay_mp, FS_STATE_PENDING);
if (fs_state_get(overlay_mp) != FS_STATE_PENDING) {
ULOG_ERR("unable to set filesystem state\n");
break;
}
case FS_STATE_PENDING:
ULOG_INFO("overlay filesystem has not been fully initialized yet\n");
overlay_delete(overlay_mp, true);
break;
case FS_STATE_READY:
break;
}
fs_name = overlay_fs_name(volume_identify(v));
ULOG_INFO("switching to %s overlay\n", fs_name);
if (mount_move("/tmp", "", "/overlay") || fopivot("/overlay", "/rom")) {
ULOG_ERR("switching to %s failed - fallback to ramoverlay\n", fs_name);
return ramoverlay();
}
return -1;
}
- const char *overlay_mp = “/tmp/overlay” 定义临时挂载点
- find_mount_point 查找
rootfs_data分区的挂载点,主要目的是为了确认rootfs_data是否已经挂载,如果未挂载,则继续执行 - overlay_mount_fs 将
rootfs_data分区挂载到/tmp/overlay目录 - overlay_fs_name(volume_identify(v)) 获取
rootfs_data分区文件系统的类型 - mount_move(“/tmp”, “”, “/overlay”) 将挂载点
/tmp/overlay迁移至/overlay, - fopivot(“/overlay”, “/rom”) 挂载
overlayfs,可写文件系统的挂载点为/overlay,/rom此时还只是一个普通文件夹
int fopivot(char *rw_root, char *ro_root)
{
char overlay[64], mount_options[64], upperdir[64], workdir[64], upgrade[64], upgrade_dest[64];
struct stat st;
if (find_filesystem("overlay")) {
ULOG_ERR("BUG: no suitable fs found\n");
return -1;
}
snprintf(overlay, sizeof(overlay), "overlayfs:%s", rw_root);
snprintf(upperdir, sizeof(upperdir), "%s/upper", rw_root);
snprintf(workdir, sizeof(workdir), "%s/work", rw_root);
snprintf(upgrade, sizeof(upgrade), "%s/sysupgrade.tgz", rw_root);
snprintf(upgrade_dest, sizeof(upgrade_dest), "%s/sysupgrade.tgz", upperdir);
snprintf(mount_options, sizeof(mount_options), "lowerdir=/,upperdir=%s,workdir=%s",
upperdir, workdir);
/*
* Initialize SELinux security label on newly created overlay
* filesystem where /upper doesn't yet exist
*/
if (stat(upperdir, &st))
selinux_restorecon(rw_root);
/*
* Overlay FS v23 and later requires both a upper and
* a work directory, both on the same filesystem, but
* not part of the same subtree.
* We can't really deal with these constraints without
* creating two new subdirectories in /overlay.
*/
if (mkdir(upperdir, 0755) == -1 && errno != EEXIST)
return -1;
if (mkdir(workdir, 0755) == -1 && errno != EEXIST)
return -1;
if (stat(upgrade, &st) == 0)
rename(upgrade, upgrade_dest);
if (mount(overlay, "/mnt", "overlay", MS_NOATIME, mount_options)) {
ULOG_ERR("mount failed: %m, options %s\n", mount_options);
return -1;
}
return pivot("/mnt", ro_root);
}
- find_filesystem(“overlay”) 判断当前内核是否支持
overlayfs - snprintf(mount_options,xxx) 设置
overlayfs的挂载选项 - mount(overlay, “/mnt”, “overlay”, MS_NOATIME, mount_options) 将overlayfs挂载到
/mnt目录 - pivot(“/mnt”, ro_root) 这一步操作比较复杂,它主要做了2件事情:1.将当前进程的
/重新挂载到ro_root目录,也就是/rom2.将/mnt重新挂载为新的/,因为上一步中overlayfs挂载到/mnt,所以这一步结果是 overlayfs挂载到/。
最终的效果如下:
$ mount
/dev/root on /rom type squashfs (ro,relatime) # 只读文件系统
/dev/mmcblk1p66 on /overlay type ext4 (rw,noatime) # 可写文件系统
overlayfs:/overlay on / type overlay (rw,noatime,lowerdir=/,upperdir=/overlay/upper,workdir=/overlay/work) #overlayfs
有关volume 和 driver相关说明如下:
- volume
volume用于描述一个分区(块设备),但与ubifs中的volume不是一个概念,要注意区分。
这里的volume包含如下信息:
enum {
UNKNOWN_TYPE,
NANDFLASH,
NORFLASH,
UBIVOLUME,
BLOCKDEV,
};
struct volume {
struct driver *drv;//分区对应driver
char *name;//分区名
char *blk;//分区对应的设备节点,dev/xxx
__u64 size;//分区大小
__u32 block_size;//块大小
int type;//NANDFLASH/NORFLASH/UBIVOLUME
};
- driver
driver是操作volume的驱动,包括初始化、查找、读写、擦除等操作,这些操作与具体的文件系统有关,因此不同的文件系统会对应不同的driver。
typedef int (*volume_probe_t)(void);
typedef int (*volume_init_t)(struct volume *v);
typedef void (*volume_stop_t)(struct volume *v);
typedef struct volume *(*volume_find_t)(char *name);
typedef int (*volume_identify_t)(struct volume *v);
typedef int (*volume_read_t)(struct volume *v, void *buf, int offset, int length);
typedef int (*volume_write_t)(struct volume *v, void *buf, int offset, int length);
typedef int (*volume_erase_t)(struct volume *v, int start, int len);
typedef int (*volume_erase_all_t)(struct volume *v);
struct driver {
struct list_head list;//用于将多个不同的driver挂接在一起
char *name;//驱动名
volume_probe_t probe;
volume_init_t init;//
volume_stop_t stop;
volume_find_t find;
volume_identify_t identify;
volume_read_t read;
volume_write_t write;
volume_erase_t erase;
volume_erase_all_t erase_all;
};
mount_root->ram
int
ramoverlay(void)
{
mkdir("/tmp/root", 0755);
mount("tmpfs", "/tmp/root", "tmpfs", MS_NOATIME, "mode=0755");
return fopivot("/tmp/root", "/rom");
}
- mount(“tmpfs”, “/tmp/root”, “tmpfs”, MS_NOATIME, “mode=0755”) 挂载
tmpfs - fopivot(“/tmp/root”, “/rom”) 将当前进程的
/重新挂载到/rom目录 然后将/tmp/root重新挂载为新的/,这种overlayfs的可写部分是基于RAM的文件系统,所有的修改掉电后会丢失。
mount_root->stop
static int
stop(int argc, char *argv[1])
{
if (!getenv("SHUTDOWN"))
return -1;
return 0;
}
- getenv(“SHUTDOWN”) 获取
SHUTDOWN环境变量并返回结果码
mount_root->done
# openwrt/package/base-files/files/etc/init.d/done
#!/bin/sh /etc/rc.common
# Copyright (C) 2006 OpenWrt.org
START=95
boot() {
mount_root done
rm -f /sysupgrade.tgz && sync
# process user commands
[ -f /etc/rc.local ] && {
sh /etc/rc.local
}
# set leds to normal state
. /etc/diag.sh
set_state done
}
- mount_root done 会在openwrt所有服务启动的尾声被调用
static int
done(int argc, char *argv[1])
{
struct volume *v = volume_find("rootfs_data");
if (!v)
return -1;
switch (volume_identify(v)) {
case FS_NONE:
case FS_DEADCODE:
return jffs2_switch(v);
case FS_EXT4:
case FS_F2FS:
case FS_JFFS2:
case FS_UBIFS:
fs_state_set("/overlay", FS_STATE_READY);
break;
}
return 0;
}
- volume_find(“rootfs_data”) 查询分区name为
rootfs_data的分区,返回对应的volume对象 - volume_identify(v) 识别
rootfs_data分区的文件系统类型,如果是FS_EXT4FS_F2FSFS_JFFS2FS_UBIFS这4种文件系统之一,会设置文件系统状态为FS_STATE_READY,表示overlayfs挂载完成。
参考
核心的進入點: start_kernel()
Linux内核源码分析-安装实际根文件系统- prepare_namespace
内核启动之start_kernel()和rest_init()函数
/dev/root
文章来源:https://blog.csdn.net/qq_24835087/article/details/135462194
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python入门知识点分享——(十四)异常处理
- python:PyCharm更改.PyCharm配置文件夹存储位置
- js中window的OPen方法,弹窗的特征
- 蒙牛×每日互动合作获评中国信通院2023“数据+”行业应用优秀案例
- 使用uni-app实现弹幕功能及滚动效果
- C++知识点总结(13):函数
- 通过几个基本概念说一下为什么openGauss是当下之选?
- Vue组件间的通信
- Java云讲座系统(源码+开题)
- Redis:5种基本数据类型概述