Shell 脚本应用(四)
正则表达式概述
????????正则表达式又称正规表达式,常规表达式。在代码中常简写为regex,regexp 或RE.正则表达式 是使用单个字符串来描述,匹配一系列符合某个句法规则的字符串,简单来说,是一种匹配字符串 的方法,通过一些特殊符号,实现快速查找,删除、替换某个特定字符串。 正则表达式是由普通字符与元字符组成的文字模式。模式用于描述在搜索文本时要匹配的一 个或多个字符串,正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。其中 普通字符包括大小写字母,数字,标点符号及一些其他符号,元字符则是指那些在正则表达式中 具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中 的出现模式.
基础正则表达式
????????正则表达式的字符串表达方法根据不同的严谨程度与功能分为基本正则表达式与扩展正则表达 式,基础正则表达式是常用的正则表达式的最基础的部分,在Linux系统中常见的文件处理工具中 grep 与sed支持基础正则表达式,而egrep与awk支持扩展正则表达式。掌握基础正则表达式的使用 方法,首先必须了解基本正则表达式所包含的元字符的含义,下面通过grep命令以举例的方式逐个介绍。
1.基础正则表达式示例
下面的操作需要提前准备一个名为test.txt的测试文件,文件具体内容如下所示.
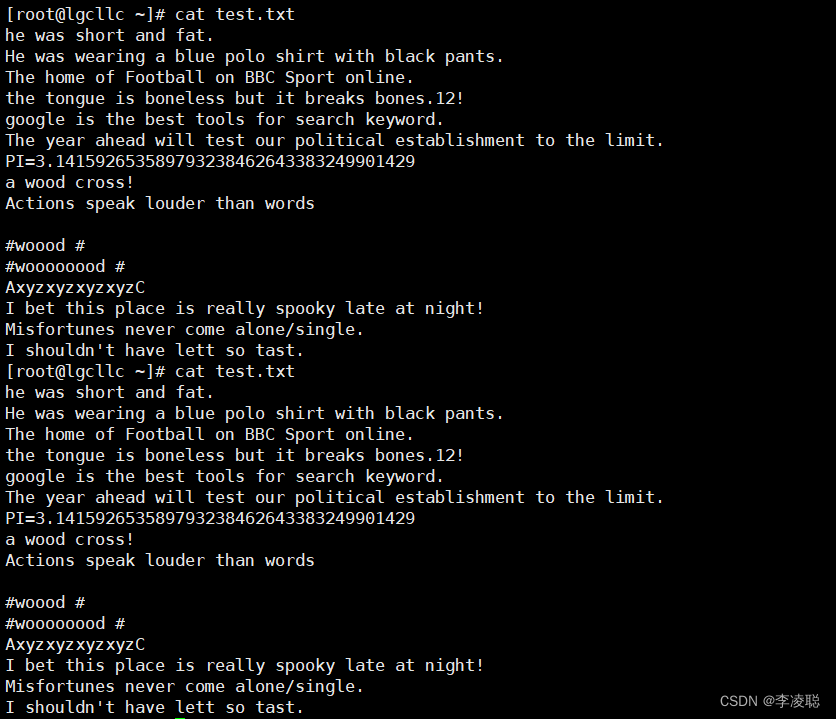
?(1)查找特定字符
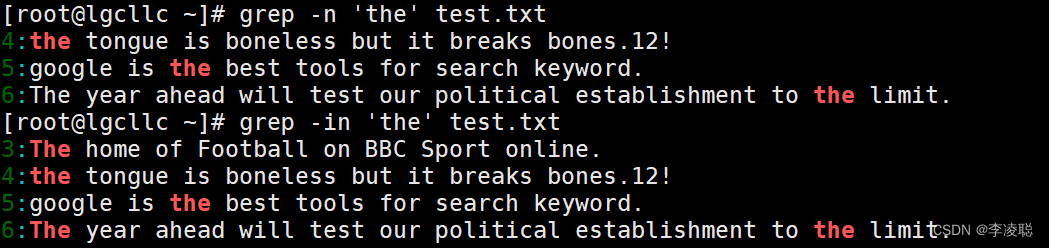
????????查找特定字符非常简单,如执行以下命令即可从test.txt文件中查找出特定字符“the"所在位置. 其中“-n”表示显示行号,“-i”表示不区分大小写,命令执行后,符合匹配标准的字符,字体颜色 会变为红色(本章中全部通过加粗显示代替)
[root@lgcllc ~]# grep -n 'the' test.txt?
[root@lgcllc ~]# grep -in 'the' test.txt?
?
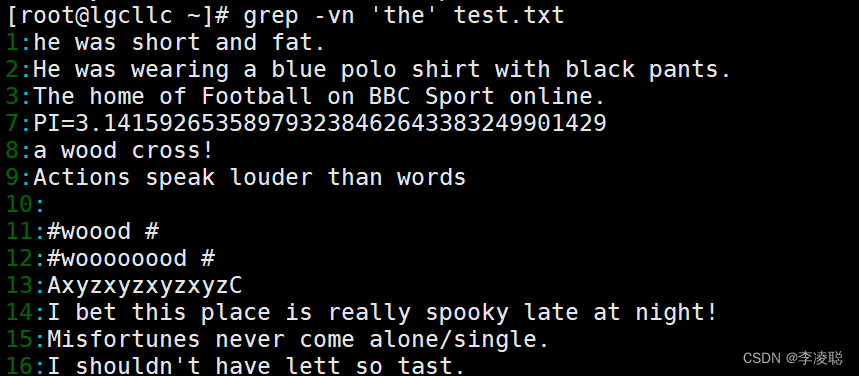
若反向选择,如查找不包含“the”字符的行,则需要通过grep命令的‘-vn”选项实现.
[root@lgcllc ~]# grep -vn 'the' test.txt?
 ?
?
(2)利用中括号“[ ]”来查找集合字符
????????????????想要查找“shirt”与“short”这两个字符串时,可以发现这两个字符串均包含“sh与rt".此 时执行以下命令即可同时查找到“shirt与“short”这两个字符串.“I”中无论有几个字符,都仅代表一个字符,也就是说“[io]”表示匹配"i”或者“o”.
[root@lgcllc ~]# grep -n 'sh[io]rt' test.txt?

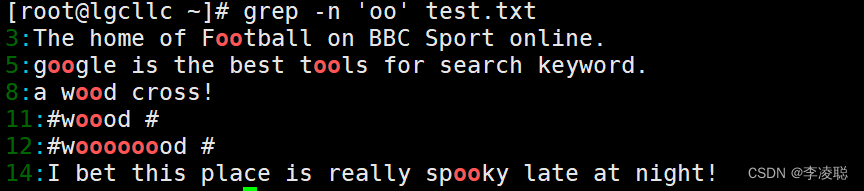
?若要查找包含重复单个字符‘oo”时,只需要执行以下命令即可。
[root@lgcllc ~]# grep -n 'oo' test.txt?
?若查找‘oo”前面不是‘w”的字符串,只需要通过集合字符的反向选择“[]”来实现该目的, 如执行“grep -n“[“w]oo'test.txt”命令表示在test.txt文本中查找“oo”前面不是“w”的字符串。
[root@lgcllc ~]# grep -n '[^w]oo' test.txt

?(3)查找行首“^”?与行尾字符“$”?
查询the字符串时出现了很多包含“the”的行,如果想要查询以“the”字符串为行首的行,则可以通过 ' ^'元字符来实现。
[root@lgcllc ~]# grep -n '^the' test.txt?

?
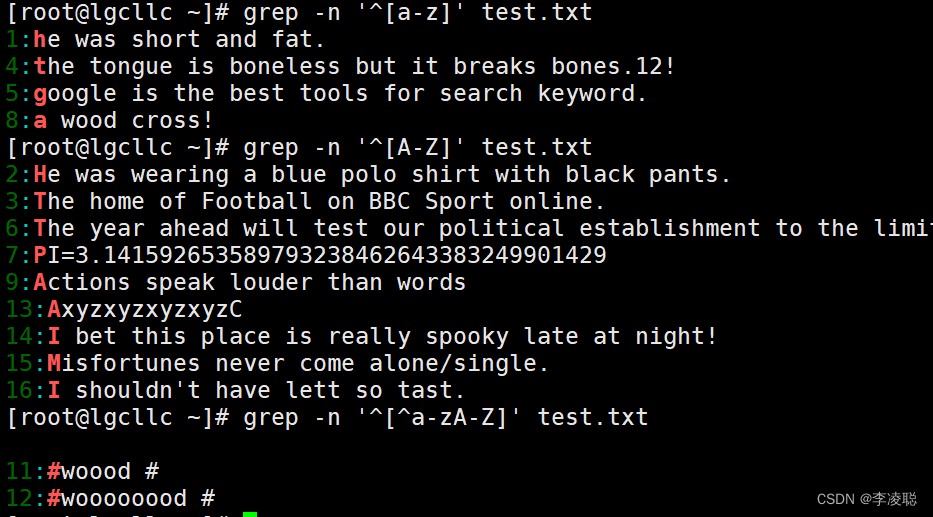
查询以小写字母开头的行可以通过“[a-z]”规则来过滤,查询大写字母开头的行则使用“[A-Z]” 规则,若查询不以字母开头的行则使用“T—a-zA-Z]”规则。
[root@lgcllc ~]# grep -n '^the' test.txt
[root@lgcllc ~]# grep -n '^[A-Z]' test.txt?
[root@lgcllc ~]# grep -n '^[^a-zA-Z]' test.txt?
 ?
?
当查询空白行时.执行“grep-n““s'test.txt”命令即可。
?[root@lgcllc ~]# grep -n '^$' test.txt?
?(4)查找任意一个字符”.”与重复字符”*”
????????在正则表达式中小数点(.)也是一个元字符,代表任意一个字符。例如,执行以下 命令就可以查找“w??d”的字符串,即共有四个字符,以w开头d结尾.
[root@lgcllc ~]# grep -n 'w..d' test.txt
 ?
?
若查询包含至少两个o以上的字符串,可执行以下语句
[root@lgcllc ~]# grep -n 'ooo*' test.txt?
 ?
?
(5)查找连续字符范围“{ }”
????????在上面的示例中,我们使用“.”与“*”来设定零个到无限多个重复的字符,如果想要限制一 个范围内的重复的字符串该如何实现呢?例如,查找三到五个o的连续字符,这个时候就需要使用基础正则表达式中的限定范围的字符“{ }”.因为“{ }”在Shell中具有特殊意义,所以在使用“{}” 字符时,需要利用转义字符“\”,将“{ }”字符转换成普通字符。“{}”字符的使用方法如下所示。?
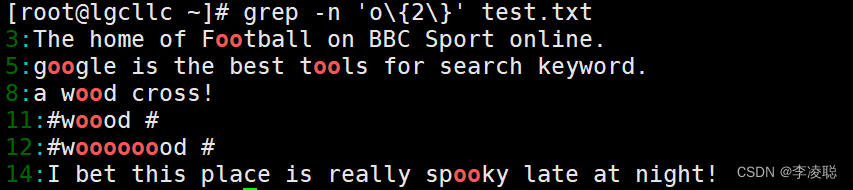
????????查询两个o的字符。
[root@lgcllc ~]# grep -n 'o\{2\}' test.txt?
 ?
?
?????????查询以w开头以d结尾,中间包含2~5个o的字符串。?
[root@lgcllc ~]# grep -n 'wo\{2,5\}d' test.txt?
 ?
?
????????查询以w开头以d结尾,中间包含2以上o的字符串。?
[root@lgcllc ~]# grep -n 'wo\{2,\}d' test.txt?
 ?
?
2.元字符总结?

文本处理器?
????????在Linux/UNX系统中包含很多种文本处理器或文本编辑器,其中包括我们之前学习过的VM编辑器 与grep等。而 grep,sed,awk 更是shell编程中经常用到的文本处理工具,被称之为Shell编程三剑客。
sed工具
????????通常情况下调用sed命令有两种格式,如下所示,其中,“参数”是指操作的目标文件,当存在 多个操作对象时用,文件之间用逗号””分隔:而scriptfile表示脚本文件,需要用“-f”选项指定. 当脚本文件出现在目标文件之前时,表示通过指定的脚本文件来处理输入的目标文件。??????
 ??
??
awk工具?
????????通常情况下awk所使用的命令格式如下所示,其中,单引号加上大括号“{ }”用于设置对数据 进行的处理动作。awk可以直接处理目标文件,也可以通过“-f ”读取脚本对目标文件进行处理。

????????默认情况下字段的分隔符为空格或者tab键。awk执行结果可以通过 print的功能将字段数 据打印显示。在使用awk命令的过程中,可以使用逻辑操作符“&&”,表示“与”,“II”表示“或”, “!”表示“非”:还可以进行简单的数学运算,如+,一、*./.%、“分别表示加、减、乘、除、取余和乘方。
 ?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 批量剪辑方法:掌握视频剪辑技巧,按指定时长轻松分割视频
- 【架构】API接口安全防护救命的11招
- 【Vue】Vue 路由传参
- 精密划片机在电子烟芯片上的应用
- 面向对象的三大基本特征之三:多态
- 解决[ Ubuntu ]E: Unable to locate package clang-14
- EasyRecovery2024电脑数据恢复工具好不好用?
- 使用OpenCV和PIL库读取图片的区别
- 「工业遥测」图表控件LightningChart在制造加工业中的应用
- AI绘画:Midjournety的使用体验