Python从入门到精通 第五章(组合数据类型)
一、组合数据类型的分类
1、集合类型
(1)集合类型是一个元素集合,元素之间无序,相同元素在集合中唯一存在。
(2)Python中的集合类型与数学中的集合概念一致,即包含0个或多个数据项的无序组合,集合中的元素不可重复,元素类型只能是不可变数据类型,例如整数、浮点数、字符串、元组等。(列表、字典和集合类型本身都是可变数据类型,不可作为集合的元素)
2、序列类型
(1)序列类型是一维元素向量,元素之间存在顺序关系,通过序号访问其中的元素,元素之间不排他(也就是可以有相同元素)。
(2)Python提供了多种序列数据类型,比较重要的是字符串类型、列表类型和元组类型。字符串类型可以看成是单一字符的有序组合,属于序列类型;元组和列表是可以使用多种类型元素的序列类型(换句话说,它们每个元素类型不一定都要相同)
(3)序列类型使用相同的索引体系,即正向递增序号和反向递减序号,这个体系在第三章“字符串的索引”一节有介绍,该体系同样适用于列表和元组(切片操作也和字符串基本相同,把字符串的每个字符当成一个元素即可)。

(4)序列类型有一些通用的操作符和函数,如下所示:
| 操作符 | 描述 |
| in | x in s,如果x是s的元素,返回True,否则返回False |
| not in | x not in s,如果x不是s的元素,返回True,否则返回False |
| + | s + t,返回连接s和t的结果 |
| * | s * n 或n * s,返回序列s赋值n次的结果 |
| s[i] | 索引,返回序列的第i个元素 |
| s[i:j] | 切片,返回包含序列s第i到j个元素的子序列(不包含第j个元素) |
| s[i:j:k] | 步骤切片,返回包含序列s第i到j个元素以k为步长的子序列 |
| len(s) | 返回序列s的元素个数(序列s的长度) |
| min(s) | 返回序列s中的最小元素 |
| max(s) | 返回序列s中的最大元素 |
| s.index(x) | 返回序列s中第一次出现元素x的位置 |
| s.count(x) | 返回序列s中出现x的总次数 |
3、映射类型
(1)映射类型是“键-值”数据项的组合,每个元素是一个键值对,表示为(key,value),元素之间是无序的。
(2)键值对(key,value)是一种二元关系,源于属性和值的映射关系。键(key)表示一个属性,也可以理解为一个类别或项目,值(value)是属性的内容。键值对将映射关系结构化,用于存储和表达。
(3)映射类型是序列类型的一种扩展,在序列类型中,采用从0开始的正向递增序号进行具体元素值的索引,而映射类型则由用户来定义序号(即键),用其去索引具体的值。
(4)Python提供了专门的映射类型,即字典类型。
二、集合类型
1、集合的定义
(1)Python中的集合是元素的无序组合,其类型用大括号{}表示,它没有索引和位置的概念,集合中的元素可以动态增加或删除。由于集合中的元素是无序的,集合的输出顺序与定义顺序可以不一致。
(2)集合中的元素不可重复,元素类型只能是固定数据类型(可理解为C语言中的常量)。由于集合元素独一无二,使用集合类型能够过滤掉重复元素。
(3)type函数返回的集合类型标记为’set’。
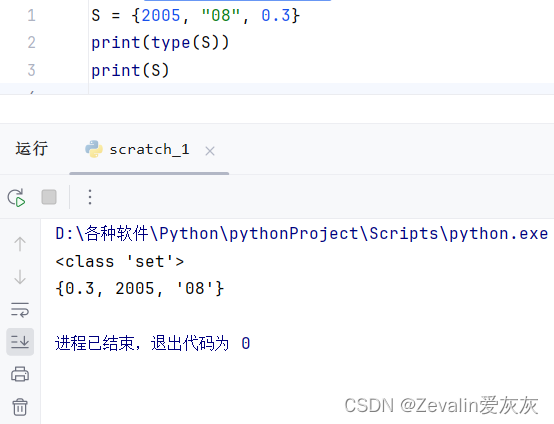
2、集合的创建
(1)直接赋初值创建集合:
①利用大括号({})直接创建集合。
②由于集合类型和字典类型都用大括号标记,所以采用大括号方式创建集合时必须赋初值,不能创建空集合(否则只能创建空字典)。

(2)set函数创建集合:
①set(x)函数可以根据参数x创建集合类型,要求参数x是组合数据类型,如列表或字符串等。
②如果参数x中存在重复元素,创建后的集合会自动去重。
③空集合用set()表示。

(3)set函数只接收1个参数,它会分解该参数(将输入的序列分解为多个元素,然后进行去重),形成集合;{}可以接收多个参数,每个参数会被当作一个独立元素,不会再被分解。
3、集合的操作符
| 操作符的运算 | 描述 |
| S-T | 返回一个新集合,包括在集合S中但不在集合T中的元素 |
| S&T | 返回一个新集合,包括同时在集合S和T中的元素 |
| S^T | 返回一个新集合,包括集合S和T中的非共同元素 |
| S|T | 返回一个新集合,包括集合S和T中的所有元素 |

4、集合的操作函数
| 函数或方法 | 描述 |
| S.add(x) | 如果数据项x不在集合S中,将x增加到S中 |
| S.clear() | 移除S中所有数据项 |
| S.discard(x) | 移除指定元素x,指定元素不存在不会报错 |
| S.pop() | 随机移除并返回某个元素 |
| S.remove(x) | 如果x在集合S中,移除该元素;如果不在则产生KeyError异常 |
| S.update(S1) | 将一个集合S1中的元素加入另一个集合S中 |
| len(S) | 返回集合S的元素个数 |
| x in S | 如果x是S的元素,返回True;否则返回False |
| x not in S | 如果x不是S的元素,返回True;否则返回False |
三、列表类型
1、列表的定义
(1)List(列表)是Python中使用最频繁的数据类型,在其它语言中通常叫做数组。
(2)列表用“[]”定义,数据之间使用“,”分隔。
(3)列表的索引从0开始。
①索引就是数据在列表中的位置编号,又称为下标。
②从列表中取值时,如果超出索引范围,程序会报错。
2、列表常用操作


(1)列表的基本使用:
name_list = ["zhangsan", "lisi", "wangwu"] # 创建列表
# 1. 取值和取索引
# list index out of range - 列表索引超出范围
# 列表指定的索引超出范围,程序会报错!
# 例如:print(name_list[3])
print(name_list[2])
# 知道数据的内容,想确定数据在列表中的位置(如果该数据出现多次,会得到第一次出现的位置)
# 使用index方法需要注意,如果传递的数据不在列表中,程序会报错!
print(name_list.index("wangwu"))
# 2. 修改
name_list[1] = "李四"
# list assignment index out of range
# 列表指定的索引超出范围,程序会报错!
# 例如:name_list[3] = "王小二"
# 3. 增加
# append 方法可以向列表的末尾追加数据
name_list.append("王小二")
# insert 方法可以在列表的指定索引位置插入数据
name_list.insert(1, "小美眉")
# extend 方法可以把其他列表中的完整内容,追加到当前列表的末尾
temp_list = ["孙悟空", "猪二哥", "沙师弟"]
name_list.extend(temp_list)
# 4. 删除
# remove 方法可以从列表中删除指定的数据
name_list.remove("wangwu")
# pop 方法默认可以把列表中最后一个元素删除
name_list.pop()
# pop 方法可以指定要删除元素的索引
name_list.pop(3)
# clear 方法可以清空列表
name_list.clear()
print(name_list)(2)del关键字:
name_list = ["张三", "李四", "王五"]
# (知道即可)使用 del 关键字(delete)删除列表元素
# 提示:在日常开发中,要从列表删除数据,建议使用列表提供的方法
del name_list[1]
# del 关键字本质上是用来将一个变量从内存中删除的
name = "小明"
del name
# 注意:如果使用 del 关键字将变量从内存中删除
# 后续的代码就不能再使用这个变量了
# print(name)
print(name_list)(3)列表的数据统计:
name_list = ["张三", "李四", "王五", "王小二", "张三"]
# len(length 长度) 函数可以统计列表中元素的总数
list_len = len(name_list)
print("列表中包含 %d 个元素" % list_len)
# count 方法可以统计列表中某一个数据出现的次数
count = name_list.count("张三")
print("张三出现了 %d 次" % count)
# 从列表中删除第一次出现的数据,如果数据不存在,程序会报错
name_list.remove("张三")
print(name_list)(4)列表排序:
name_list = ["zhangsan", "lisi", "wangwu", "wangxiaoer"]
num_list = [6, 8, 4, 1, 10]
# 升序
name_list.sort()
num_list.sort()
# 降序
name_list.sort(reverse=True)
num_list.sort(reverse=True)
# 逆序(反转)
name_list.reverse()
num_list.reverse()
print(name_list)
print(num_list)(5)列表遍历:
name_list = ["张三", "李四", "王五", "王小二"]
# 使用迭代遍历列表
"""
顺序的从列表中依次获取数据,每一次循环过程中,数据都会保存在
my_name 这个变量中,在循环体内部可以访问到当前这一次获取到的数据
for my_name in 列表变量:
print("我的名字叫 %s" % my_name)
"""
for my_name in name_list:
print("我的名字叫 %s" % my_name)(6)对于基本的数据类型,如整数或字符串,可以通过等号实现元素赋值,但对于列表类型,使用等号是无法实现真正的赋值的(如下所示,Is=It语句并不是拷贝It中的元素给变量Is,而是新关联了一个引用,即Is和It所指向的是同一套内容),要想达到复制列表的效果,需要借助copy方法。
It = ["2005","08","03"]
Is = It
It.clear() # 清空It
print(Is)
It = ["2005","08","03"]
Is = It.copy()
It.clear() # 清空It
print(Is)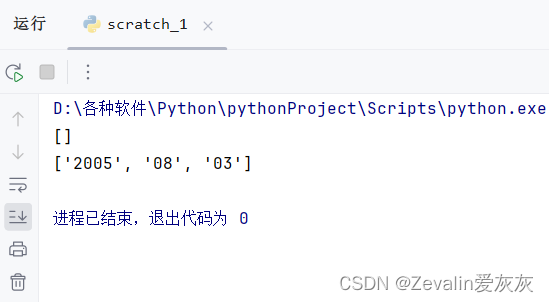
四、元组类型
1、元组的定义
(1)Tuple(元组)与列表类似,不同之处在于元组在创建完之后就不能修改。
(2)元组用“()”定义,元素之间使用“,”分隔。
(3)元组的索引从 0 开始,索引就是数据在元组中的位置编号。

2、元组的创建
(1)创建普通元组:
info_tuple = ("zhangsan", 18, 1.75)(2)创建空元组:
info_tuple = ()(3)创建只包含一个元素的元组:(需要在那一个元素后面添加逗号,否则创建的数据类型不是元组)
info_tuple = ("zhangsan",)3、元组常用操作
(1)元组的基本使用和数据统计:
info_tuple = ("zhangsan", 18, 1.75, "zhangsan")
# 1. 取值和取索引
# 根据下标访问元组中的元素
print(info_tuple[0])
# 已经知道数据的内容,希望知道该数据在元组中的索引
print(info_tuple.index("zhangsan"))
# 2. 统计计数
# 统计元组中某个元素出现的次数
print(info_tuple.count("zhangsan"))
# 统计元组中包含元素的个数
print(len(info_tuple))(2)元组遍历:(在实际开发中,除非能够确认元组中的数据类型,否则针对元组的循环遍历需求并不是很多)
info_tuple = ("zhangsan", 18, 1.75)
"""
# for 循环内部使用的变量 in 元组
for item in info:
循环内部针对元组元素进行操作
print(item)
"""
# 使用迭代遍历元组
for my_info in info_tuple:
print(my_info)4、元组的应用场景
(1)函数的参数和返回值:一个函数可以接收任意多个参数(参数类型为元组类型,其中的元素就是需要接收的参数),或者一次返回多个数据(返回值类型为元组类型,其中的元素就是需要返回的数据)。
def measure():
"""测量温度和湿度"""
print("测量开始...")
temp = 39
wetness = 50
print("测量结束...")
# 元组-可以包含多个数据,因此可以使用元组让函数一次返回多个值
# 如果函数返回的类型是元组,小括号可以省略
# return (temp, wetness)
return temp, wetness
# 元组
result = measure()
print(result)
# 需要单独的处理温度或者湿度 - 不方便
print(result[0])
print(result[1])
# 如果函数返回的类型是元组,同时希望单独的处理元组中的元素
# 可以使用多个变量,一次接收函数的返回结果
# 注意:使用多个变量接收结果时,变量的个数应该和元组中元素的个数保持一致
gl_temp, gl_wetness = measure()
print(gl_temp)
print(gl_wetness)(2)让列表不可以被修改,以保护数据安全。
(3)格式字符串:格式化字符串后面的“()”本质上就是一个元组。
info_tuple = ("小明", 21, 1.85)
# 格式化字符串后面的 `()` 本质上就是元组
print("%s 年龄是 %d 身高是 %.2f" % info_tuple)
info_str = "%s 年龄是 %d 身高是 %.2f" % info_tuple
print(info_str)(4)在Python中,可以将一个元组使用赋值语句同时赋值给多个变量(变量的数量需要和元组中的元素数量保持一致)。
# 交换两个数字
a = 6
b = 100
# 解法1:-使用其他变量
# c = a
# a = b
# b = c
# 解法2:-不使用其他的变量
# a = a + b
# b = a - b
# a = a - b
# 解法3:-Python 专有
# a, b = (b, a)
# 提示:等号右边是一个元组,只是把小括号省略了
a, b = b, a
print(a)
print(b)5、元组和列表之间的转换
(1)使用list函数可以把元组转换成列表(列表作为返回值,不影响原本的元组):
变量名 = list(元组)
(2)使用tuple函数可以把列表转换成元组(元组作为返回值,不影响原本的列表):
变量名 = tuple(列表)
五、字典类型
1、字典的定义
(1)dictionary(字典)是除列表以外 Python之中最灵活的数据类型。
(2)字典同样可以用来存储多个数据,通常用于存储描述一个物体的相关信息。
(3)和列表的区别:列表是有序的对象集合,字典是无序的对象集合。
(4)字典用“{}”定义。
(5)字典使用键值对存储数据,键值对之间使用“,”分隔。
①键(key)是索引,值(value)是数据。
②键和值之间使用“:”分隔。
③键必须是唯一的,也就是不能有重复。
④值可以取任何数据类型,但键只能使用字符串、数字或元组。
{<键1>:<值1>,<键2>:<值2>,…,<键n>:<值n>}
(6)可以简单地把字典看成元素是键值对的集合。
# 字典是一个无序的数据集合,使用print函数输出字典时,通常
# 输出的顺序和定义的顺序是不一致的!
xiaoming = {"name": "小明",
"age": 18,
"gender": True,
"height": 1.75,
"weight": 75.5} # 创建字典
print(xiaoming)2、字典常用操作
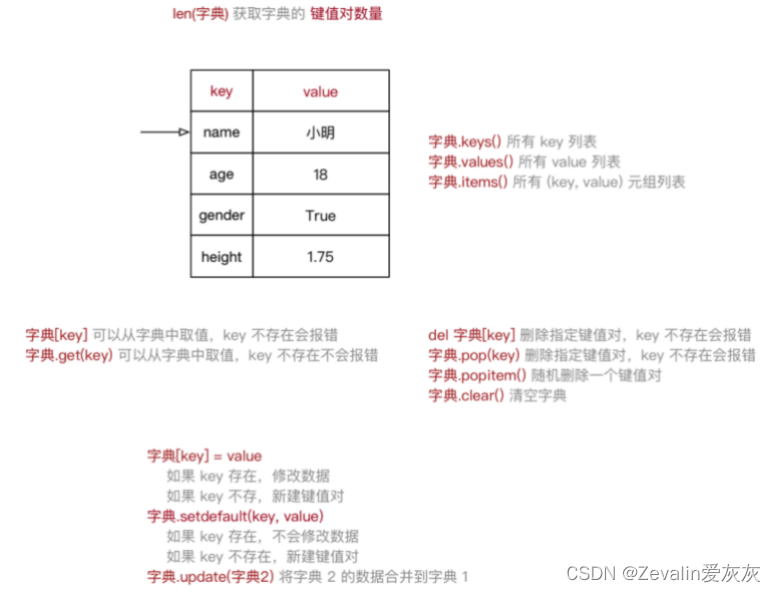
(1)基本使用:
xiaoming_dict = {"name": "小明"} # 创建字典
# 1. 取值
print(xiaoming_dict["name"])
# 在取值的时候,如果指定的key不存在,程序会报错!
# print(xiaoming_dict["name123"])
# 2. 增加/修改
# 如果key不存在,会新增键值对
xiaoming_dict["age"] = 18
# 如果key存在,会修改已经存在的键值对
xiaoming_dict["name"] = "小小明"
# 3. 删除
xiaoming_dict.pop("name")
# 在删除指定键值对的时候,如果指定的key不存在,程序会报错!
# xiaoming_dict.pop("name123")
print(xiaoming_dict)(2)其它操作:
xiaoming_dict = {"name": "小明",
"age": 18}
# 1. 统计键值对数量
print(len(xiaoming_dict))
# 2. 合并字典
temp_dict = {"height": 1.75,
"age": 20}
# 注意:如果被合并的字典中包含已经存在的键值对,会覆盖原有的键值对
xiaoming_dict.update(temp_dict)
# 3. 清空字典
xiaoming_dict.clear()
print(xiaoming_dict)(3)循环遍历:
xiaoming_dict = {"name": "小明",
"qq": "123456",
"phone": "10086"}
# 迭代遍历字典
# 变量k是每一次循环中,获取到的键值对的key
for k in xiaoming_dict:
print("%s - %s" % (k, xiaoming_dict[k]))六、字符串
1、字符串的定义
(1)字符串就是 一串字符,是编程语言中表示文本的数据类型。
(2)在Python中可以使用一对双引号或者 一对单引号定义一个字符串。
(3)可以使用索引获取一个字符串中指定位置的字符,索引计数从0开始;也可以使用for 循环遍历字符串中每一个字符。
str1 = "hello python"
str2 = '我的外号是"大西瓜"'
print(str2)
print(str1[6])
# 字符串的遍历
for char in str2:
print(char)
2、字符串的常用操作
(1)字符串的统计操作:
hello_str = "hello hello"
# 1. 统计字符串长度
print(len(hello_str))
# 2. 统计某一个小(子)字符串出现的次数
print(hello_str.count("llo"))
print(hello_str.count("abc"))
# 3. 某一个子字符串出现的位置
print(hello_str.index("llo"))
# 注意:如果使用index方法传递的子字符串不存在,程序会报错!
print(hello_str.index("abc"))(2)字符串的判断方法:

# 1. 判断空白字符
space_str = " \t\n\r"
print(space_str.isspace())
# 2. 判断字符串中是否只包含数字
# 1> 以下三个方法都不能判断是否包含小数
# num_str = "1.1"
# 2> unicode 字符串
# num_str = "\u00b2"
# 3> 中文数字
num_str = "一千零一"
print(num_str)
print(num_str.isdecimal())
print(num_str.isdigit())
print(num_str.isnumeric())(3)查找和替换:

(4)大小写转换:
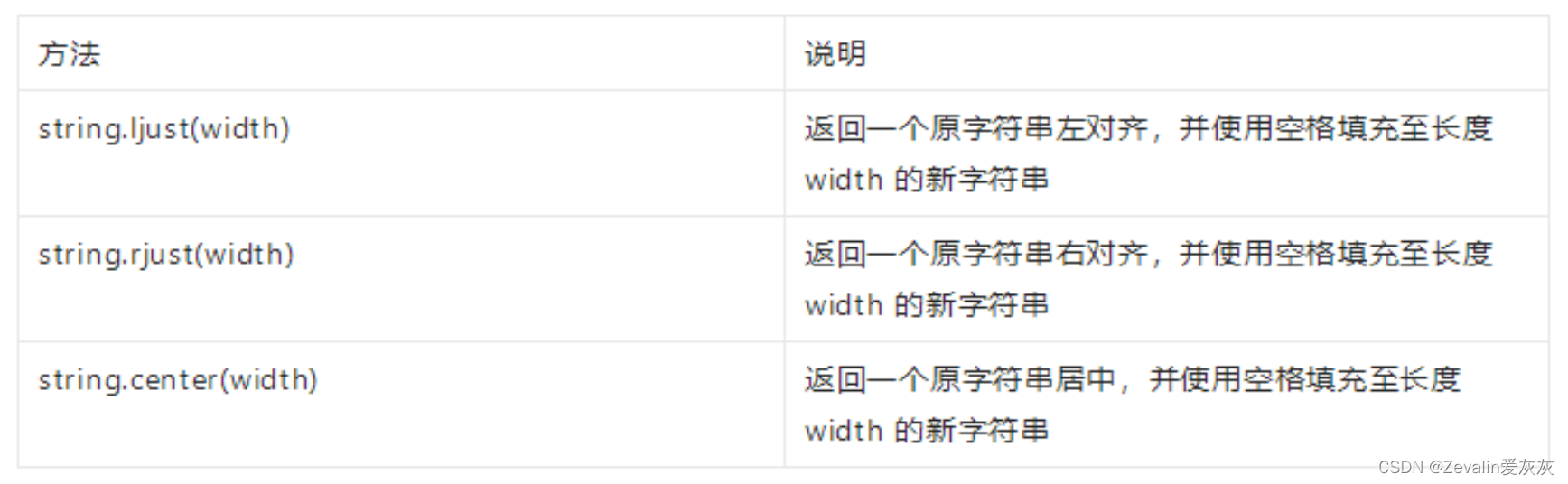
(5)文本对齐:
(6)去除空白字符:

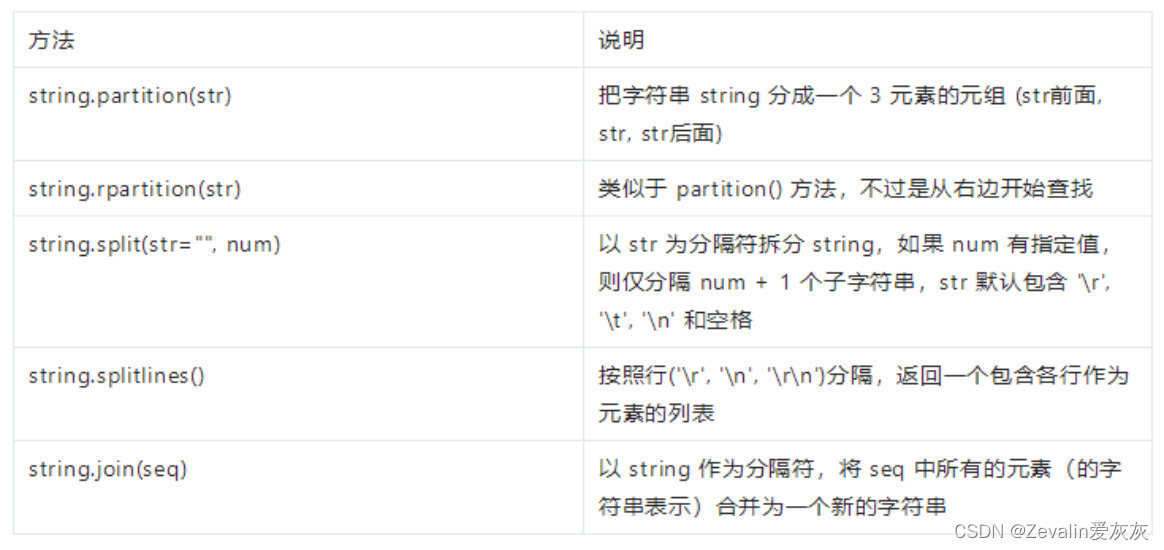
(7)拆分和连接:
七、公共方法
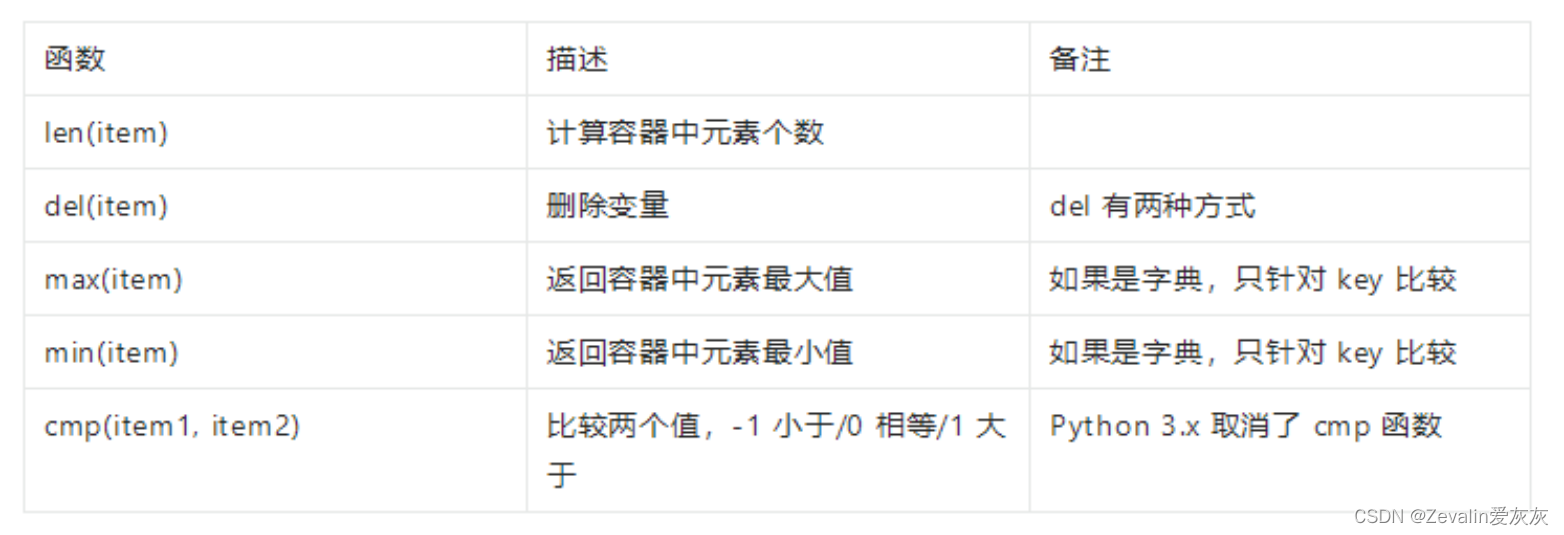
1、Python内置函数
2、切片

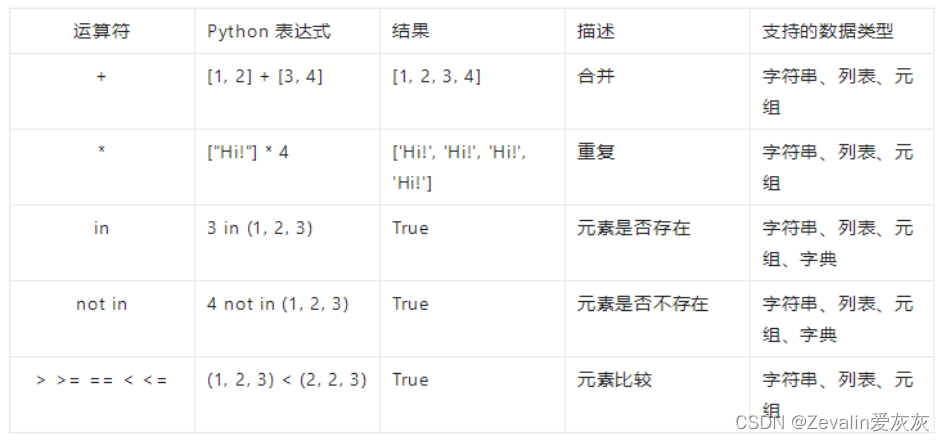
3、运算符
注意:
①in在对字典操作时,判断的是字典的键。
②in和not in被称为成员运算符,成员运算符用于测试序列中是否包含指定的成员。
③in和not in也支持集合数据类型,上表中没有体现。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 一文了解数据库vs数据仓库vs数据湖
- 【题解】leetcode---69. x 的平方(二分查找入门)
- ssm某研发型企业知识管理系统(程序+开题)
- meyesphere 脚本出现 Class: JSONObject not found in namespace
- 设计模式(4)--对象行为(7)--观察者
- (salutation称呼)Mr., Mrs., Miss, Ms., Mx.,Jr.,Sr.,II,III,IV 分别是什么意思
- 人工智能 AI 如何让我们的生活更加便利
- vs code 设置了自动格式化保存 但是json 配置文件不想自动格式化
- 深入剖析LinkedList:揭秘底层原理
- Mysql show Profiles详解