学习python第六天
序列
?字符串、元组、列表都是序列,他们的共同点有:
1.都可以通过索引获取每一个元素
2.第一个索引都是0?
3.都可以通过切片获取一个范围内的集合
4. 都有很多共同的运算符
不同点:
根据元素能否被改变可以分为可变序列和不可变序列
列表是可变序列;字符串和元组是不可变序列
可以作用于序列的一些运算符和函数:
“+”:将两个序列合并成一个序列
“*”:将序列内的元素复制多少遍
id(序列):获取该序列的唯一标识符
is和is not用于检测唯一标识符是否一致
A = [1,2,1]
B = [1,2,1]
print(A is B)
print(A is not B)in 和 not in用于检测序列中是否包含某元素
C = "雨"
D= "下雨"
print(C in D)
print(C not in D)del:用于删除一个或者多个对象
A = [1,2,1]
B = [1,2,1]
C = [1,2,3,4,5,6]
del A
del B[1:]
del C[:5:2]序列之间相互转换的函数:
转换成列表:list()
转换成元组:tuple()
转换成字符串:str()

max 和min:输出传入内容的最大值和最小值(传入的内容可以直接是一个序列,也可以一堆数)(此时如果传入一个空对象,就会报错,我们可以用函数里面的default参数进行处理)

len:用于计算可变序列的长度(有长度限制,32位要求小于2的31次方-1,64位要求小于2的63次方-1)
sum(序列,start):求一个序列的和,start是用来指定第一个参数是多少

sorted(序列,revers=False,key):
对序列内容进行排序然后返回一个新的序列,原来序列不变,revers默认为False,如果revers=True的话,结果会再原来的基础上在进行反转,变成从大到小排序,key是可以传入一个函数,此时会先将元素挨个传入函数中,然后再对所得结果进行排序
列表中的sort和sorted的区别:sort方法只能处理列表,而且是对列表本身进行改变的,而sorted可以处理任何序列,并且是返回一个新的序列,不会改变原来序列

reversed:返回一个序列的反向迭代器对象

all函数:用来判断序列中是否所有元素都为真
any函数:用来判断序列中是否有元素为真
 ??
??
enumerate(start)函数:用于返回一个枚举对象,它的功能就是将可迭代对象中的每个元素及从0开始的序号共同构成一个二元组的列表。(start可以控制序号从多少开始)
 zip函数:用于创建一个聚合多个可迭代对象的迭代器。它会将作为参数传入的每个可迭代对象的每个元素依次组合成元组,即第ⅰ个元组包含来自每个参数的第ⅰ个元素(当传入的序列的长度不一致时,他会以最短的序列的长度为准)
zip函数:用于创建一个聚合多个可迭代对象的迭代器。它会将作为参数传入的每个可迭代对象的每个元素依次组合成元组,即第ⅰ个元组包含来自每个参数的第ⅰ个元素(当传入的序列的长度不一致时,他会以最短的序列的长度为准)

解决zip会舍弃长度比较长的序列的元素这个问题,我们可以使用itertools模块的zip_longest方法

map函数:会根据提供的函数对指定的可迭代对象的每个元素进行运算,并将返回运算结果的迭代器。?(传入的序列的长度不一致时,他会以最短的序列的长度为准)

filter函数:会根据提供的函数对指定的可迭代对象的每个元素进行运算,并将运算结果为真的元素,以迭代器的形式返回:?
 ?迭代器和可迭代对象:
?迭代器和可迭代对象:
一个迭代器肯定是一个可迭代对象
最大区别:可迭代对象可以重复使用而迭代器则是一次性的
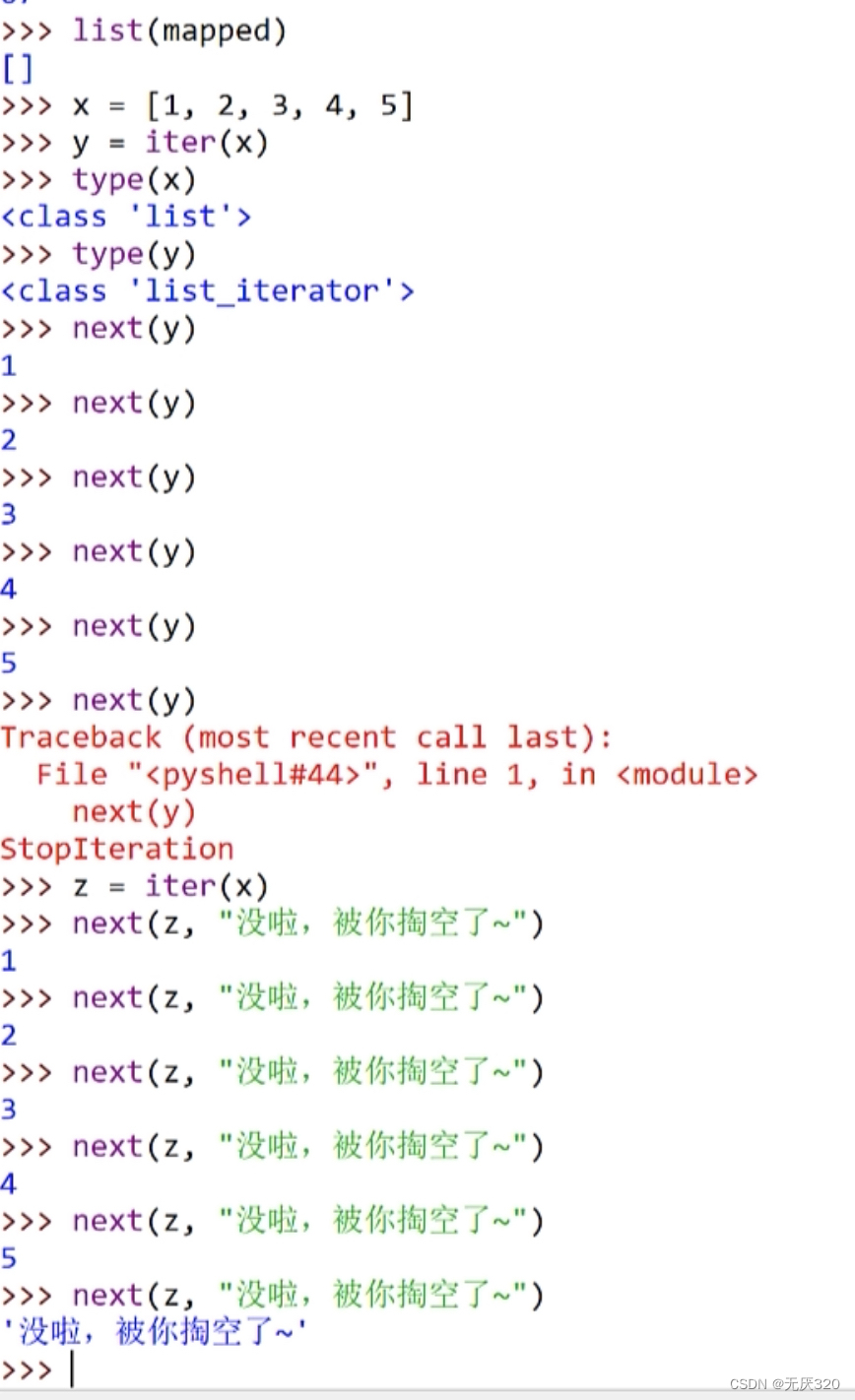
iter函数:将一个可迭代对象,转换成一个迭代器
next(iterable[, default])函数:返回迭代器的下一个项目,要和生成迭代器的?iter()?函数一起使用
terable -- 可迭代对象,default -- 可选,用于设置在没有下一个元素时返回该默认值,如果不设置,又没有下一个元素则会触发 StopIteration 异常。
? ?字典
字典的五种创建方法:
a = {"吕布":"口口布","关羽":"关习习","刘备":"刘baby"}
b = dict(吕布="口口布",关羽 = "关习习",刘备="刘baby")
c = dict([("吕布","口口布"),("关羽","关习习"),("刘备","刘baby")])
d = dict({"吕布":"口口布","关羽":"关习习","刘备":"刘baby"})
e = dict({"吕布":"口口布","关羽":"关习习"},刘备 = "刘baby")
f = dict(zip(["吕布","关羽","刘备"],["口口布","关习习","刘baby"]))
print(a == b == c == d == e ==f)增:
fromkeys(iterable[,values]):可以使用iterable指定的可迭代对象创建一个新的字典,并且初始化为values参数指定的值
g = dict.fromkeys("ascd",1)
print(g)
删:
pop(键):删除对应键的字典元素
e = dict({"吕布":"口口布","关羽":"关习习"},刘备 = "刘baby")
e.pop("吕布")
print(e)popitem:在python3.7之前是随机删除一个字典元素,python3.7之后,是删除最后添加进来的字典元素
f = dict(zip(["吕布","关羽","刘备"],["口口布","关习习","刘baby"]))
f.popitem()
print(f)del函数也可以用来删除字典元素
f = dict(zip(["吕布","关羽","刘备"],["口口布","关习习","刘baby"]))
del f["刘备"]del字典名:直接删除整个字典
字典.clear():删除字典内的所有元素
改:
直接通过键值进行查找:
f = dict(zip(["吕布","关羽","刘备"],["口口布","关习习","刘baby"]))
f["刘备"] = "111"update方法:支持一次修改多个,可以直接穿多个值,或者传入一个序列
f = dict(zip(["吕布","关羽","刘备"],["口口布","关习习","刘baby"]))
f.update(丈夫="222")
f.update({"吕布":"口口1布","关羽":"关习2习"})查:
直接使用键值进行查询(如果字典里面没有该元素时,会直接报错):
f = dict(zip(["吕布","关羽","刘备"],["口口布","关习习","刘baby"]))
print(f["刘备"])get(default)方法:可以处理查询字典里没有的元素会报错的问题
f = dict(zip(["吕布","关羽","刘备"],["口口布","关习习","刘baby"]))
g = f.get("lisan","没有该元素")
print(g)setdefault方法:查询字典中的某元素,如果有就返回值,如果没有就将查询的元素添加进去
f = dict(zip(["吕布","关羽","刘备"],["口口布","关习习","刘baby"]))
f.setdefault("张飞","小飞飞")
print(f)items、keys、values方法:dict.keys()、dict.values()?和?dict.items()?返回的都是视图对象( view objects),提供了字典实体的动态视图,这就意味着字典改变,视图也会跟着变化。视图对象不是列表,不支持索引,可以使用 list() 来转换为列表。我们不能对视图对象进行任何的修改,因为字典的视图对象都是只读的。
f = dict(zip(["吕布","关羽","刘备"],["口口布","关习习","刘baby"]))
print(f.keys())
print(f.values())
print(f.items())copy:浅拷贝(深拷贝父对象(一级目录),子对象(二级目录)不拷贝,子对象是引用)
a = {"1":1,"2":2,"3":3,"4":[1,2]}
b = a.copy()
a["1"] = 4
a["4"].remove(1)
print(a)
print(b)list(字典名):将字典的所有键生成一个列表
list(字典名.values):将字典的所有值生成一个列表
a = {"1":1,"2":2,"3":3,"4":[1,2]}
print(list(a))
print(list(a.values()))in和not in:看元素是否在字典中,是跟键做的比较
a = {"1":1,"2":2,"3":3,"4":[1,2]}
print("1" in a)
print("2" not in a)iter:
将一个可迭代对象,转换成一个迭代器
next(iterable[, default])函数:返回迭代器的下一个项目,要和生成迭代器的?iter()?函数一起使用
terable -- 可迭代对象,default -- 可选,用于设置在没有下一个元素时返回该默认值,如果不设置,又没有下一个元素则会触发 StopIteration 异常。
字典嵌套:
#如果是两个字典嵌套,那么修改都需要使用键
a = {"吕布":{"语文":80,"数学":90},"关羽":{"语文":83,"数学":99}}
print(a)
a["吕布"]["语文"]=100
print(a)
#如果是一个字典一个列表嵌套,那么修改时字典使用键列表使用下标
b = {"吕布":[22,11,33],"关羽":[11,66,88]}
print(b)
b["关羽"][0] = 99
print(b)字典推导式:
?
#键和值反转
a = {"a":1,"b":2,"c":3}
b = {k:v for v,k in a.items()}
print(b)
c = {b:ord(b) for b in "asdf" if ord(b)>100}
print(c)本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Jmeter实现CSV数据批量导入
- 数据库(一)| 数据库概述、基本概念、关系型数据库特点、超键候选码等
- Redis淘汰策略、持久化、主从同步与对象模型
- Java毕业设计基于springboot的网络云端日记本系统
- juejin小册前端面试一面 1:ES 基础知识点与高频考题解析
- 李宏毅机器学习第二十四周周报 Self-attention ConvLSTM
- 软件开发架构
- Mock.js使用并且添加到数据库中
- Select语句完整的执行顺序
- 阿里云2核2G3M服务器上传速度多少?下载速度快吗?