用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
近年来,随着AIGC的爆火,图片生成技术得到飞速发展,当前AI生成的图片已达到真假难辨的高保真度。不过,当合成图片中出现文字内容时,仍能够使AI露出马脚,因为当前主流方法尚无法在图片中生成准确可读的字符。
最近半年来已有学者开始研究文本生成的问题,但这些方法大多以英文为主,无法解决中文这种字形繁杂、字符数以万计的文字生成。
本文分享一种新颖的文字生成方法AnyText,通过创新性的算法设计,可以支持中文、英语、日语、韩语等多语言的文字生成,还支持对输入图片中的文字内容进行编辑。AnyText模型所涉及的文字生成技术为电商海报、Logo设计、创意涂鸦、表情包等新型AIGC应用提供了可能性。
代码链接:
https://github.com/tyxsspa/AnyText
论文链接:
https://arxiv.org/abs/2311.03054
模型链接:
https://modelscope.cn/models/damo/cv_anytext_text_generation_editing

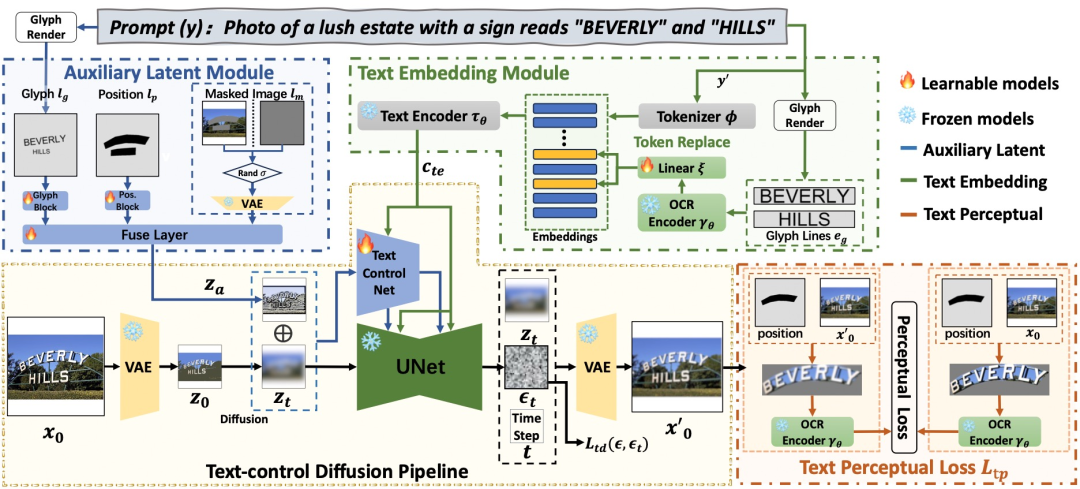
AnyText 主要基于扩散(Diffusion)模型,包含两个核心模块:隐空间辅助模块(Auxiliary Latent Module)和文本嵌入模块(Text Embedding Module)。
其中,隐空间辅助模块对三类辅助信息(字形、文字位置和掩码图像)进行编码并构建隐空间特征图像,用来辅助视觉文字的生成;文本嵌入模块则将描述词中的语义部分与待生成文本的字形部分解耦,使用图像编码模块单独提取字形信息后再与语义信息做融合,既有助于文字的书写精度,也有利于提升文字与背景的一致性。
训练阶段,除了使用扩散模型常用的噪声预测损失,AnyText还增加了文本感知损失,在图像空间对每个生成文本区域进行像素级的监督,以进一步提升文字书写精度。
技术交流
建了AIGC大模型技术交流群! 想要学习、技术交流、获取如下原版资料的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:来自CSDN + 技术交流

模型体验
魔搭创空间地址:
https://modelscope.cn/studios/damo/AnyDoor-online
新年做个春联吧!
prompt:一条金色的中国龙,在门框中间,中国风,剪纸风,上面写着“龙年大吉”“心想事成”

环境准备
环境配置与安装
-
python 3.8及以上版本
-
pytorch 1.12及以上版本,推荐2.0及以上版本
-
建议使用CUDA 11.4及以上
本文主要演示的模型推理代码可在魔搭社区免费实例PAI-DSW的配置下运行(显存24G) :
第一步:点击模型右侧Notebook快速开发按钮,选择GPU环境
第二步:新建Notebook
第三步:克隆AnyText仓库,安装依赖,准备字库文件(https://modelscope.cn/studios/damo/studio_anytext/file/view/master/font%2FArial_Unicode.ttf?status=2)
# 克隆anytext仓库
!git clone https://github.com/tyxsspa/AnyText.git
%cd AnyText
# 准备字库文件(推荐Arial Unicode MS)
!mv your/path/to/arialuni.ttf ./font/Arial_Unicode.ttf
# 使用modelscope notebook最新镜像(ubuntu22.04-cuda11.8.0-py310-torch2.1.0-tf2.14.0-1.10.0),安装如下依赖包
!pip install Pillow==9.5.0
===
模型推理
参照如下示例代码,对anytext进行模型推理,实现文字生成或文字编辑:
from modelscope.pipelines import pipeline
from util import save_images
pipe = pipeline('my-anytext-task', model='damo/cv_anytext_text_generation_editing', model_revision='v1.1.0')
img_save_folder = "SaveImages"
params = {
"show_debug": True,
"image_count": 2,
"ddim_steps": 20,
}
# 1. text generation
mode = 'text-generation'
input_data = {
"prompt": 'photo of caramel macchiato coffee on the table, top-down perspective, with "Any" "Text" written on it using cream',
"seed": 66273235,
"draw_pos": 'example_images/gen9.png'
}
results, rtn_code, rtn_warning, debug_info = pipe(input_data, mode=mode, **params)
if rtn_code >= 0:
save_images(results, img_save_folder)
# 2. text editing
mode = 'text-editing'
input_data = {
"prompt": 'A cake with colorful characters that reads "EVERYDAY"',
"seed": 8943410,
"draw_pos": 'example_images/edit7.png',
"ori_image": 'example_images/ref7.jpg'
}
results, rtn_code, rtn_warning, debug_info = pipe(input_data, mode=mode, **params)
if rtn_code >= 0:
save_images(results, img_save_folder)
print(f'Done, result images are saved in: {img_save_folder}')
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 艺术家与AI创作:解析他们之间的紧张关系
- 如何通过内网穿透实现公网访问Portainer管理监控Docker容器
- 如何愉快,有效的阅读毛选
- 7.6、kali windows 虚拟机如何移除
- git推送前HOOK pre-push判断版本号增加再推送
- 笔记1-Windows10深度学习环境
- milkv-duo cvi-mmf 硬件加速 JPG 解码性能测试
- 数据割据:当代社会数据治理的挑战
- 我的创作纪念日三年收获和感悟
- DL专栏—笔记目录