单元化、异地多活,大厂如何实现?
尼恩说在前面
在40岁老架构师 尼恩的读者交流群(50+)中,尼恩一直在指导大家改造简历、指导面试。指导很多小伙伴拿到了一线互联网企业网易、美团、字节、如阿里、滴滴、极兔、有赞、希音、百度、美团的面试资格,拿到大厂offer。
前几天,指导了一个40岁老伙伴拿到年薪100W offer,这个小伙伴的优势在:异地多活,在中间件的高可用(HA)。
在其他的小伙伴的简历指导的过程中,尼恩也发现: 异地多活的概念、异地多活的架构、非常重要。而且,异地多活的架构,本身就非常重要,大厂的线上高可用P0级别的严重问题也是非常频繁:
3月份出了两个大的线上事故,B站刚崩,唯品会又崩了。9月份之后,大厂接二连三的P0级事故(高可用事故)语雀崩了、阿里云崩,阿里崩完、滴滴崩…
异地容灾/异地多活,是架构师/高级开发必须掌握的核心技术,理由有2:
- 异地容灾/异地多活已经成为大厂核心服务的标准配置。当然,要实现真正意义上的异地多活,就需要对服务进行单元化改造。
- 另外,从面试视角来看,异地容灾、单元化、高可用也是面试的核心重点。
刚好前面几天,有小伙伴面试,遇到一些异地多活的很重要的面试题:
高可用异地多活,如何实现?
高可用异地容灾,你的方案是啥?
你们的高可用、单元化改造方式是啥?
在这里,尼恩给自己的技术自由圈(未来 超级 架构师) 社区的小伙伴, 积累一些 异地多活的架构方案和素材。 这些资料的主要的目标: 方便在架构指导的时候,作为参考资料。在尼恩的公号【技术自由圈】中,之前有过多篇大厂异地多活的方案文章:
《美团面试:ES+Redis+MySQL高可用,如何试实现?》
在这里,尼恩借助高德技术中心架构师韦王同学的文章《高德服务单元化方案和架构实践》,给大家做一下系统化、体系化的微服务底层架构 梳理,使得大家可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”。
也一并把这个题目以及参考答案,收入咱们的 《尼恩Java面试宝典PDF》V151版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
特别提示:尼恩的3高架构宇宙,持续升级。
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请到文末公号【技术自由圈】取
文章目录
高德服务单元化方案和架构实践
作者:韦王,高德技术
本文主要分享了高德在服务单元化构建方面的实际操作经验在服务单元化构建过程中,会遇到许多共性问题,例如请求路由、单元封闭、数据同步等。
有些问题已经有成熟的解决方案可以参考和使用,但是不同公司的业务都有各自的特点,因此需要尽可能结合自身的业务特点来进行相应的设计和处理。
一、为什么要做单元化
- 单机房资源瓶颈
随着业务规模和服务用户群体的扩大,单机房或同城双机房已经无法满足服务持续扩容的需求。
- 服务异地容灾
异地容灾已经成为核心服务的标准配置。虽然有些服务已经在多地多机房进行部署,但数据仍然只在中心机房。要实现真正意义上的异地多活,就需要对服务进行单元化改造。
二、高德单元化的特点
在做高德的单元化项目时,我们首先要考虑的是结合高德的业务特点,看高德的单元化有什么不一样的诉求,这样就清楚哪些经验和方案是可以直接拿来用的,哪些又是需要我们去解决的。
高德的业务与传统在线交易业务存在差异,高德为用户提供以导航为代表的出行服务,这些服务在许多场景下对响应时间(RT)有极高的要求。
因此,在做单元化方案时,尽可能减少对整体服务RT的影响,就是我们需要重点考虑的一个性能问题,尽量做到数据离用户近一些。转换到单元化技术层面需要解决两个问题:
-
用户设备的单元接入应尽可能实现就近接入,用户真实地理位置接近哪个单元就接入哪个单元。
例如华北用户接入到张北,华南接入到深圳。
-
用户的单元划分应与就近接入的单元保持一致,以减少单元间的跨单元路由。
例如用户请求从深圳进来,用户的单元划分最好就在深圳单元,如果划到张北单元就会造成跨单元路由。
此外,高德的许多服务无需用户登录,因此我们的单元化方案不仅需要支持用户ID,还必须支持基于设备ID的单元化。
高德的单元化项目要求我们深入理解其业务特性,并在此基础上设计出既能满足响应时间要求又能适应无需登录服务需求的单元化方案。
这涉及到优化用户接入策略,确保单元划分与用户地理位置的一致性,以及支持无登录服务的单元化技术。
三、高德单元化实践
为了实施服务的单元化架构改造,需要一个至上而下的系统性设计,核心要解决三个核心问题:
- 请求路由
- 单元封闭
- 数据同步

注意:请点击图像以查看清晰的视图!
-
请求路由:根据高德业务的特点,我们提供了两种路由策略:取模路由和路由表路由,目前上线应用使用较多的是路由表路由策略。
-
单元封闭:得益于集团的基础设施建设,我们使用vipserver、hsf等服务治理能力保证服务同机房调用,从而实现单元封闭(hsf unit模式也是一种可行的方案,但个人认为同机房调用的架构和模式更简洁且易于维护)。
-
数据同步:数据部分使用的是集团DB产品提供的DRC数据同步。
单元路由服务采用什么样的部署方案是我们另一个要面临的问题,考虑过以下三种方案:

注意:请点击图像以查看清晰的视图!
首先,我们排除了Server SDK方式,因为它对业务的侵入性太强。
其次,考虑Proxy 统一接入层进行代理和去中心化Nginx Plugin插件集成两种方案。
这两种方案各有利弊,但当时首批要接入单元化架构的服务很多都还没有统一接入到gateway,所以基于现状的考虑使用了去中心化Nginx Plugin插件集成的方式,通过在应用的nginx集成UnitRouter。
实施高德单元化实践是一个全面而系统的改革过程,涉及到请求路由、单元封闭以及数据同步三大核心问题的解决。
通过深入分析和灵活应对,我们选择了最适合当前情况的策略和部署方案,确保了单元化架构的成功实施和高效运行。
服务单元化架构
目前高德账号系统,云同步系统、用户评论系统都完成了单元化改造,采用三地四机房部署,
其中,写入量较高的云同步系统,单元写高峰能达到数w+QPS (存储是mongodb集群)。
以账号系统为例介绍下高德单元化应用的整体架构。

注意:请点击图像以查看清晰的视图!
账号系统服务是三地四机房部署,数据分别存储在tair为代表的缓存和XDB里,数据存储三地集群部署、全量同步。
账号系统服务器的Tengine上安装UntiRouter,它请求的负责单元识别和路由,用户单元划分是通过记录用户与单元关系的路由表来控制。
PS:由于历史原因,缓存使用了tair和自建的uredis(在redis基础上添加了基于log的数据同步功能),目前已经在逐步统一到tair。
数据同步依赖tair和alisql的数据同步方案,以及自建的uredis数据同步能力。
高德的单元化架构改造是一个复杂而全面的过程,涉及到多个服务和多个数据存储系统的整合与优化。
通过分布式部署和精细化的路由控制,高德成功提升了系统的可扩展性和稳定性,同时也为未来的服务升级和扩展打下了坚实的基础。
就近接入实现方案
为了满足高德对于低延迟的业务需求,关键在于让数据(单元)更靠近用户。其中有两个关键链路:一个是通过aserver接入的外网连接,另一个是服务内部路由(尽可能不产生跨单元路由)。
-
措施1:客户端的外部网络接入通过aserver的配置,将不同地理区域(七个大区)的用户设备导向最近的单元,例如华北地区的用户接入张北单元。
-
措施2:通过分析系统日志,记录用户与单元的关系路由表,以划分用户所属的单元。用户经常从哪个单元入口进来,就会把用户划分到哪个单元,这样确保了请求入口与单元划分的一致性,从而减少跨单元路由。
因此,在最终的单元路由实现上,我们提供了传统的取模路由,以及为了降低延时而设计的基于路由表路由两种策略。同时,为了解无须登录的业务场景问题,上述两种策略除了支持用户ID,我们同时也支持设备ID。
高德通过精细化的本地接入策略,显著提升了服务的响应速度和用户体验。通过智能路由分配和设备导向,高德确保了用户数据请求能够快速且高效地被处理,从而在竞争激烈的地图服务市场中保持领先地位。这种策略的实施不仅优化了网络延迟问题,还增强了服务的可靠性和稳定性,为用户提供了更加流畅和精准的服务体验。

路由表设计
路由表分为两部分:一个是用户-分组的关系映射表,另一个是分组-单元的关系映射表。在使用时,通过路由表查对应的分组,再通过分组看用户所属单元。这些分组与中国大陆的七个大区相对应。
先看“用户-(大区)分组”:
路由表是定期通过系统日志分析出来的,看用户最近IP属于哪个大区就划分进哪个分组,同时也对应上了具体单元。例如,如果一个北京用户长期访问深圳,那么当IP地址变化时,路由表会更新,用户将被重新分配到新的深圳大区分组,实现用户从张北单元到深圳单元的迁移。
再看“分组-单元”:
分组与单元的映射有一个默认关系,通常是按照地理位置的接近性来配置的,例如华南地区对应深圳单元。除了默认的映射关系,还有几个用于切流预案的关系映射。
| 单元分组 | 默认配置 | 单元一切流预案 | 单元二切流预案 |
|---|---|---|---|
| 东北 | 单元一 | 单元二 | 单元一 |
| 华北 | 单元一 | 单元三 | 单元一 |
| 西北 | 单元二 | 单元二 | 单元三 |
| …… | 单元三 | 单元三 | 单元三 |
| 模1分组 | 单元一 | 单元二 | 单元二 |
| 模2分组 | 单元二 | 单元二 | 单元二 |
| 模3分组 | 单元三 | 单元三 | 单元三 |
老用户可以通过路由表来查找单元,新用户怎么办?对于新用户的处理我们会降级成取模的策略进行单元路由,直至下次路由表的更新。因此,新用户跨单元路由的比例肯定会比老用户高得多。然而,由于新用户是一个相对稳定的增量,所以整体比例在可接受范围内。
| BitMap | MapDB | Bloom Filter | |
|---|---|---|---|
| 支持模型 | Uid | Uid、Tid、… | Uid、Tid、… |
| 空间占用 | 小 | 大 | 适中 |
| 效率 | 良好 | 一般 | 良好 |
| 准确率 | 100% | 100% | >99% |
| 实时修改 | 是 | 是 | 否 |
高德通过这种精细化的路由策略构建,确保了用户数据能够高效、准确地被导向相应的单元。这种策略不仅考虑了用户的地理位置,还预设了灵活的映射关系,以便应对各种突发情况。同时,对于新用户的处理也体现出了系统的弹性和适应性。通过这种方式,高德在提供地图服务时能够更好地适应不同用户的需求,从而在竞争激烈的市场中保持领先地位。这种设计不仅提高了服务的响应速度,还增强了系统的弹性和可靠性,为用户提供了一种无缝且稳定的体验。
路由计算
有了路由表,接下来就要解决工程化应用的问题,性能、空间、灵活性和准确率,以及对服务稳定性的影响这几个方面是要进行综合考虑的,首先考虑外部存储会增加服务的稳定性风险,后面我们在BloomFilter 、BitMap和MapDB多种方案中选择BloomFilter,万分之几的误命中率导致的跨单元路由在业务可接受范围内。
在通过日志分析确定用户所属大区后,我们将不同分组制作成多个布隆过滤器,以便在计算时进行逐层过滤。这种计算方式存在两种特殊情况:
-
因为BloomFilter存在误算率,有可能存在一种情况,华南分组的用户被计算到华北了,这种情况比例在万分之3 (生成BloomFilter时可调整)。这种情况对业务影响不大,因为这些用户相当于被稳定地划分到了一个非所在大区的分组中,虽然会出现跨单元路由,但在业务上是可接受的。
-
对于新用户,由于他们不在分组信息中,即使经过逐层的计算也没有匹配到对应大区分组,此时会使用取模进行模除分组的计算。

注意:请点击图像以查看清晰的视图!
如果业务采用的是取模路由而非路由表路由策略,那么将直接根据tid或uid进行模除分组计算,这种方法的原理相对简单,不再详细说明。
路由计算是实现高效、准确的用户数据导向的关键环节。通过精心设计的路由策略和计算方法,我们能够确保用户数据被准确地分配到相应的大区分组和单元,同时保持了服务的稳定性。BloomFilter的使用虽然带来了一定的误算率,但其稳定性风险在可控范围内,且对新用户的处理也确保了系统的灵活性和适应性。通过这种方式,我们不仅提高了服务的响应速度,还增强了系统的弹性和可靠性,为用户提供了一种无缝且稳定的体验。
单元切流
在发生单元故障进行切流时,主要分为四步骤
打开单元禁写 (跨单元写不敏感业务可以不配置)
检查业务延时
切换预案
解除单元禁写
PS:更新路由表时,也需要上述操作,只是第3步的切换预案变成切换新版本路由表;单元禁写主要是了等待数据同步,避免数据不一致导致的业务问题。
核心指标
单元计算耗时1~2ms
跨单元路由比例底于5%
除了性能外,因就近接入的诉求,跨单元路由比例也是我们比较关心的重要指标。从线上观察看,路由表策略单元计算基本上在1、2ms内完成,跨单元路由比例3%左右,整体底于5%。
四、后续优化
统一接入集成单元化能力
目前,多数服务已经整合到统一的接入网关服务中。这种集成单元化能力的方法显著降低了服务单元化部署的成本。通过简易的配置,即可实现单元路由,使得服务能够更专注于业务单元的封闭性和数据同步。
分组机制的优化
按大区分组存在三个问题:
-
通过IP地址计算大区存在一定的误算率,会导致部分用户被错误地分配到不正确的分组。
-
分组粒度太大,当进行单元切流时,流量不好分配。例如,如果华东是用户密集的大区,切流时无论将该分组分配到哪个指定单元,都可能造成该单元的服务压力剧增。
-
计算次数多,分多少个大区,理论最大计算次数是有多少次,最后采取取模策略。
针对上述几个问题我们计划对分组机制做如下改进
-
通过记录用户进入单元的情况来确认用户所属的单元,而不是根据用户的IP地址所在大区来判断,以解决上述问题1。
-
将每个单元划分4个虚拟分组,支持更细粒度单元切流,解上述问题2。
-
用户确实单元后,通过取模来划分到不同的虚拟分组。每个单元只要一次计算就能完成,新用户只需经过3次计算,解上述问题3。
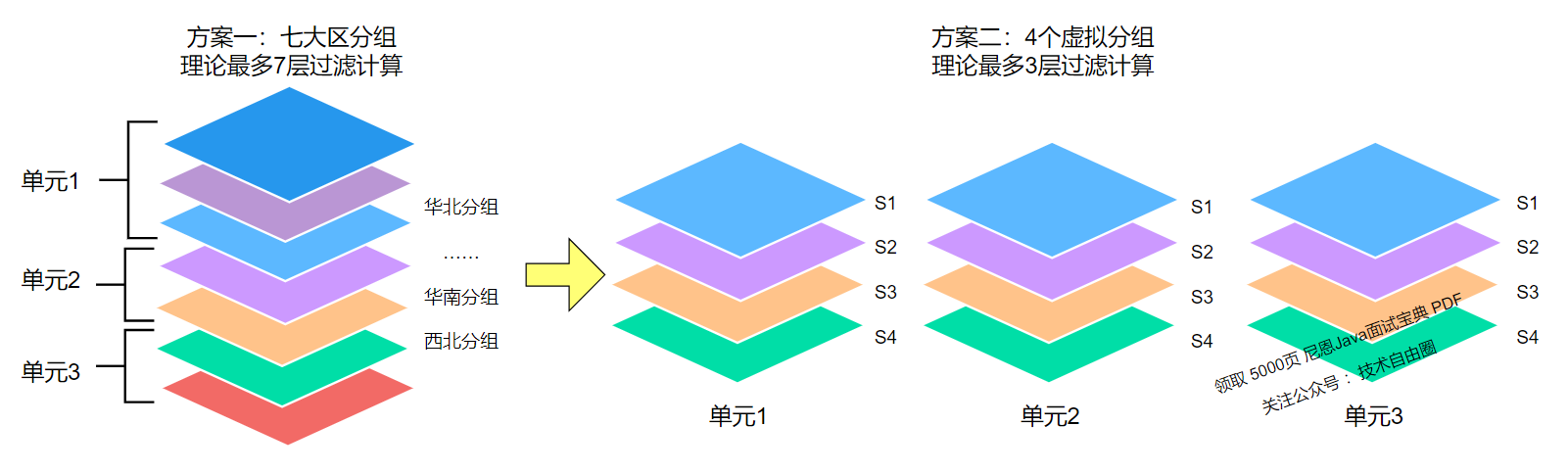
注意:请点击图像以查看清晰的视图!
通过统一接入集成单元化能力,我们能够简化服务的部署和管理,同时通过优化分组机制,提高了服务单元化部署的效率和准确性。这些改进不仅减少了误判率,还细化了分组粒度,确保了流量分配的均衡性,并简化了计算过程。这些措施共同提升了服务的整体性能和可靠性,为用户提供了更加稳定和高效的服务体验。
热更时的双表计算
与取模路由策略不同,路由表策略需要定期更新以维持跨单元路由的稳定性。然而,目前更新时需要一个短暂的单元禁写,这对于很多业务来说是难以接受的。
为优化这个问题,系统将在路由表更新时做双(路由)表计算,即将新老路由表同时加载进内存,更新时不再对业务做完全的禁写,我们会分别计算当前用户(或设备)在新老路由表的单元结果,如果单元一致,则说明路由表的更新没有导致该用户(或设备)变更单元,所以请求会被放行,反之,如果计算结果是不同单元,说明发生了单元变更,该请求会被拦截,直至到达新路由表的一个完全起用时间。
在优化前,服务会完全禁写比如10秒(具体时间取决于数据同步的时间)。而在优化后,只有在这10秒内路由发生变更的用户才会触发禁写。这将显著减少对业务的影响。
通过采用双表计算机制,我们能够在路由表更新时避免对业务造成不必要的干扰。这种机制通过同时处理新旧路由表,确保了即使在更新过程中,用户的请求也能够得到妥善处理。这样不仅提高了系统的可用性,还确保了业务的连续性,从而为用户提供了更加稳定和流畅的服务体验。
服务端数据驱动的单元化场景
前面提到,高德在路由策略上根据业务的特性进行了特别设计,尽管如此,整体的单元划分仍然是基于用户(或设备)这一维度进行的。然而,高德业务中还存在一个我们需要面对和解决的巨大挑战,那就是基于数据维度进行单元设计。这将意味着,基于终端的服务路由将转变为基于数据域的服务路由。
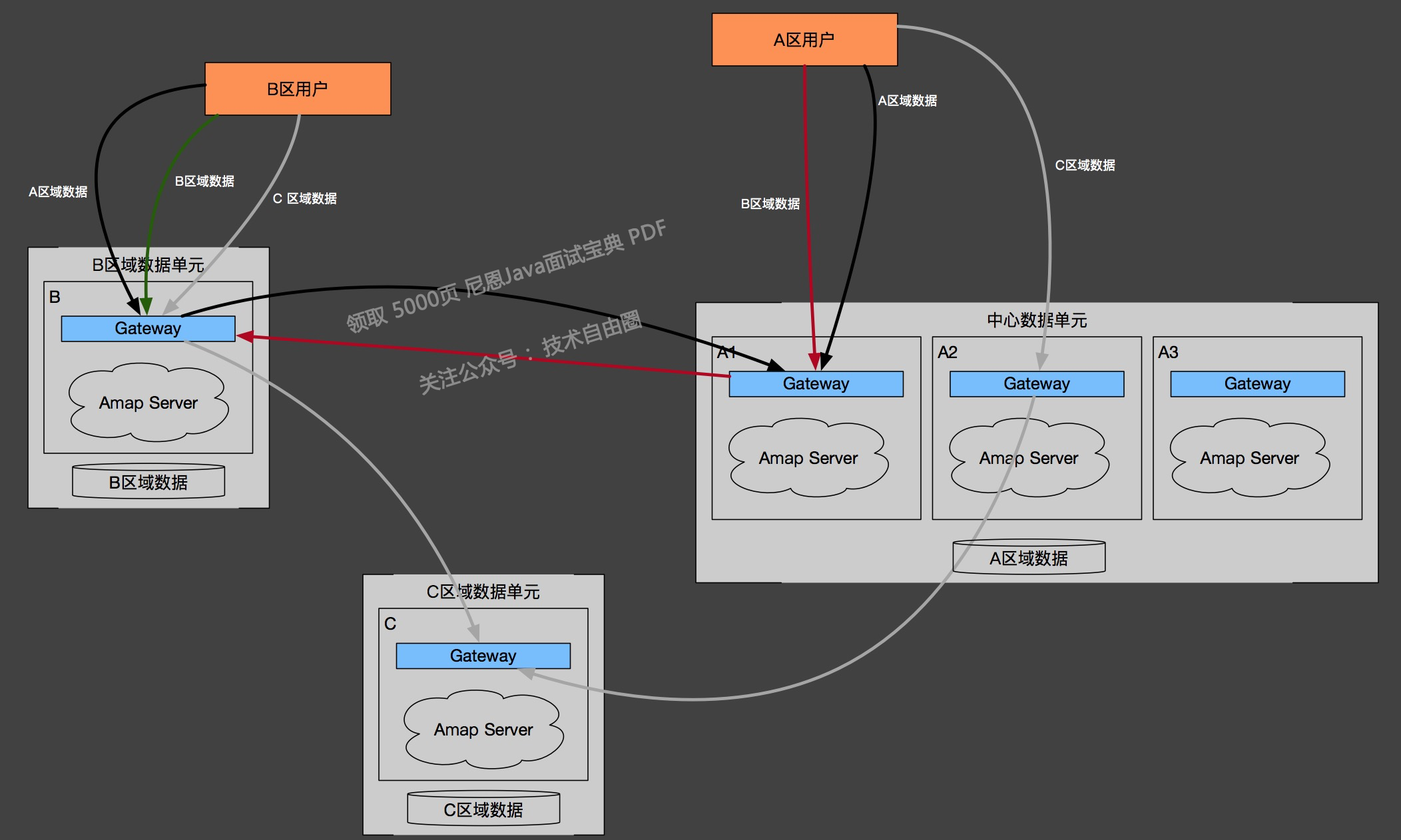
高德的许多服务都是以服务数据为核心的,例如地图数据,这些数据并非直接由用户产生。随着业务的发展,数据存储量也将不断增长,尤其是在5G和自动驾驶等领域,数据的爆炸式增长使得单点全量存储变得不切实际。因此,基于服务端数据驱动的服务单元化设计,成为了我们接下来需要重点考虑的应用场景。
随着业务的不断发展和数据的激增,我们需要从传统的用户维度转向数据维度,进行服务单元化设计。这不仅能够更好地满足业务需求,还能够有效应对数据存储和处理的挑战。基于服务端数据的单元化设计,将为高德带来更加高效和灵活的服务架构,从而为用户提供更优质的服务体验。
说在最后
高并发、高可用、异地多活的相关的面试题,是非常常见的面试题。
以上的内容,如果大家能对答如流,如数家珍,基本上 面试官会被你 震惊到、吸引到。最终,让面试官爱到 “不能自已、口水直流”。offer, 也就来了。
在面试之前,建议大家系统化的刷一波 5000页 《尼恩Java面试宝典PDF》,并且在刷题过程中,如果有啥问题,大家可以来 找 40岁老架构师尼恩交流。
另外,如果没有面试机会,可以找尼恩来帮扶、领路。
尼恩指导了大量的就业困难的小伙伴上岸,刚刚,帮助一个40岁+就业困难小伙伴,拿到了一个年薪100W的offer。
尼恩技术圣经系列PDF
- 《NIO圣经:一次穿透NIO、Selector、Epoll底层原理》
- 《Docker圣经:大白话说Docker底层原理,6W字实现Docker自由》
- 《K8S学习圣经:大白话说K8S底层原理,14W字实现K8S自由》
- 《SpringCloud Alibaba 学习圣经,10万字实现SpringCloud 自由》
- 《大数据HBase学习圣经:一本书实现HBase学习自由》
- 《大数据Flink学习圣经:一本书实现大数据Flink自由》
- 《响应式圣经:10W字,实现Spring响应式编程自由》
- 《Go学习圣经:Go语言实现高并发CRUD业务开发》
……完整版尼恩技术圣经PDF集群,请找尼恩领取
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》PDF,请到下面公号【技术自由圈】取↓↓↓
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!