模型微调入门介绍二
上一篇博客中介绍了如何使用YelpReviewFull进行模型微调,其中,重点介绍了数据加载和数据预处理,此篇博客将介绍如何用squad数据集训练一个问答系统模型。
squad数据集
?SQuAD(The Stanford Question Answering Dataset)是一组阅读数据集,该数据集基于群众在维基百科中提出的问题,其中每个问题的答案来自于对应阅读段落的一段文本,共计500 多篇文章中的10 万多个问答配对。具体的数据信息如下图所示,包括title,context,question,answers字段,answer的答案来源于context,answer字段中给出了答案在context中的start字符位置。
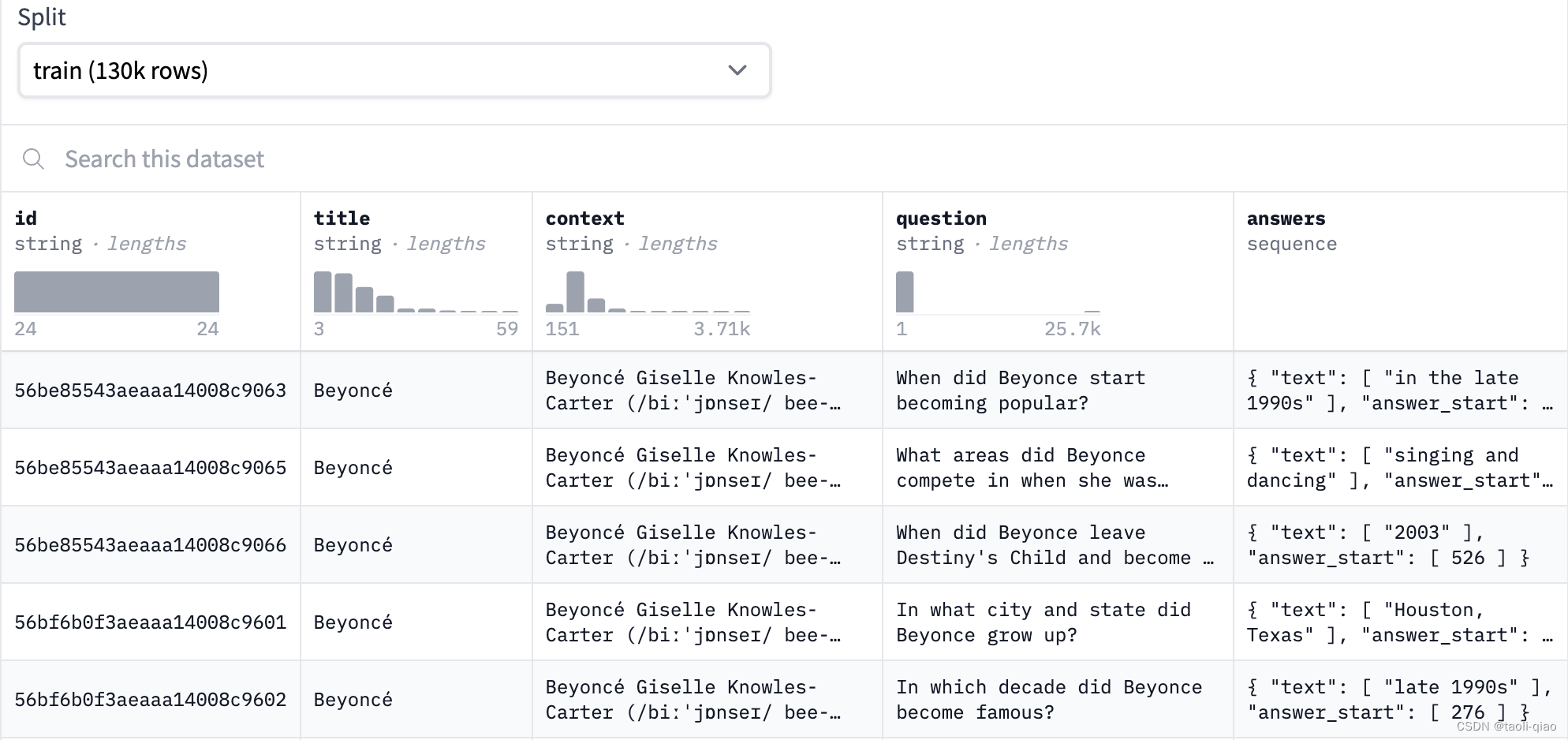
squad数据集最早设计出来,用于训练模型的阅读理解能力,文本摘要等能力,因为从context中寻找问题答案,本身就涵盖了对context的阅读理解能力,生成答案体现了对context内容的摘要能力。问答系统实际是一个端到端的业务场景,这个场景里面包含了阅读理解能力、文本摘要和内容生成能力。
数据预处理代码
(备注:以下代码来源于极客时间模型微调训练营)
下面的代码编写了大量脚本来对原始数据进行预处理,我们需要了解的是:这些代码究竟进行了哪些操作,为什么要进行这些操作。
from transformers import AutoTokenizer
squad_v2 = False
model_checkpoint = "distilbert-base-uncased"
batch_size = 16
pad_on_right = tokenizer.padding_side == "right"
# The maximum length of a feature (question and context)
max_length = 384
# The authorized overlap between two part of the context when splitting it is needed.
doc_stride = 128
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
import transformers
assert isinstance(tokenizer, transformers.PreTrainedTokenizerFast)
def prepare_train_features(examples):
# 一些问题的左侧可能有很多空白字符,这对我们没有用,而且会导致上下文的截断失败
# (标记化的问题将占用大量空间)。因此,我们删除左侧的空白字符。
examples["question"] = [q.lstrip() for q in examples["question"]]
# 使用截断和填充对我们的示例进行标记化,但保留溢出部分,使用步幅(stride)。
# 当上下文很长时,这会导致一个示例可能提供多个特征,其中每个特征的上下文都与前一个特征的上下文有一些重叠。
tokenized_examples = tokenizer(
examples["question" if pad_on_right else "context"],
examples["context" if pad_on_right else "question"],
truncation="only_second" if pad_on_right else "only_first",
max_length=max_length,
stride=doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length",
)
# 由于一个示例可能给我们提供多个特征(如果它具有很长的上下文),我们需要一个从特征到其对应示例的映射。这个键就提供了这个映射关系。
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
# 偏移映射将为我们提供从令牌到原始上下文中的字符位置的映射。这将帮助我们计算开始位置和结束位置。
offset_mapping = tokenized_examples.pop("offset_mapping")
# 让我们为这些示例进行标记!
tokenized_examples["start_positions"] = []
tokenized_examples["end_positions"] = []
for i, offsets in enumerate(offset_mapping):
# 我们将使用CLS令牌的索引来标记不可能的答案。
input_ids = tokenized_examples["input_ids"][i]
cls_index = input_ids.index(tokenizer.cls_token_id)
# 获取与该示例对应的序列(以了解上下文和问题是什么)。
sequence_ids = tokenized_examples.sequence_ids(i)
# 一个示例可以提供多个跨度,这是包含此文本跨度的示例的索引。
sample_index = sample_mapping[i]
answers = examples["answers"][sample_index]
# 如果没有给出答案,则将cls_index设置为答案。
if len(answers["answer_start"]) == 0:
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
# 答案在文本中的开始和结束字符索引。
start_char = answers["answer_start"][0]
end_char = start_char + len(answers["text"][0])
# 当前跨度在文本中的开始令牌索引。
token_start_index = 0
while sequence_ids[token_start_index] != (1 if pad_on_right else 0):
token_start_index += 1
# 当前跨度在文本中的结束令牌索引。
token_end_index = len(input_ids) - 1
while sequence_ids[token_end_index] != (1 if pad_on_right else 0):
token_end_index -= 1
# 检测答案是否超出跨度(在这种情况下,该特征的标签将使用CLS索引)。
if not (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char):
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
# 否则,将token_start_index和token_end_index移到答案的两端。
# 注意:如果答案是最后一个单词(边缘情况),我们可以在最后一个偏移之后继续。
while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char:
token_start_index += 1
tokenized_examples["start_positions"].append(token_start_index - 1)
while offsets[token_end_index][1] >= end_char:
token_end_index -= 1
tokenized_examples["end_positions"].append(token_end_index + 1)
return tokenized_examples
from datasets import load_dataset
data = load_dataset('squad')['train'][:10]
convert_data=prepare_train_features(data)
? 为了理解上面的预处理代码究竟对原始数据进行了哪些操作,可以先看一下处理后的数据是怎样的。可以看到,处理后的数据包括input_ids,start_positions,end_positions和attention_mask字段。


与直接调用tokenizer进行encode相比较,实际整个数据预处理就是计算答案的start_positions和end_postions信息,并将这个信息按模型训练需要的格式组装到dataset中。那么,为什么需要start_positions和end_positions呢?因为对于问答系统而言,从context中摘要获取问题的答案,得到了start_positions和end_positions,实际就得到了答案本身。在训练过程中,模型通过比较它的预测值(即 start_positions 和 end_positions)与真实的答案位置来计算损失。这种监督学习的设置有助于模型学习如何从文本中正确地定位答案。
? 对input_ids的内容进行decode,并打印得到下面的数据信息。因为总共只读取了10条数据,可以看到,每一段还是从原始数据中获取[CLS]question[SEP]context[SEP]进行组装,后面[PAD]都是填充占位符号,因为设置了max_length=384,当长度低于384时,就会自动进行填充。

对start_positions和end_positions进行decode,得到的信息如下图所示,以第一组为例子,答案就是context中第125-132字符内容。

? 明白了这么长的数据预处理结果,接下来再看看代码中重点部分代码,一起来捋一下整个代码实现流程。首先来看看sample_mapping和offset_mapping的含义。
下面的代码中,在调用tokenizer进行encode过程中设置了最大长度是100,如果超出这个长度就进行截断。例如,数据集第一条数据的question+context,如果长度大于100个字符,那么就要被截取成多段。[0,0,0,1...]表示处理后的数据的前面三段属于原始数据集中第一段内容,list是从0这个下标开始。

对encode的数据进行decode还原,如下图所示,可以看到确实是将第一条数据分成了三段来表示。总结而言:overflow_to_sample_mapping 是在处理长文本时的一个辅助数据结构,它用于将分割后的文本块(overflow)映射回原始数据集中的样本。

offset_mapping 是一个用于指示每个 token 在原始文本中的起始和结束字符位置的数据结构。即通过offset_mapping,你可以在处理分词后的文本时,准确地定位每个 token 在原始文本中的位置。注意,第一个位置因为是分割符号CLS,所以开始和结束位置是(0,0)。下面是一个更加简单的例子来说明offset_mapping的值的含义。对一个句子“Hello,how are you doing today?”进行encode后,对应的offset_mappings值如下所示:

? 理解了上面两个字段含义后,继续阅读上面的代码。可以看到,组装start_positions和end_postions是读取原始数据集中answer中的start的值,计算len(answer)来得到end_positons的信息。当然,过程中还有很多小细节处理,例如判断组装后是否超过最大长度等。
? 实际对于这类典型数据的典型应用场景,transformers库已经封装了方法来进行数据的预处理,对于squad数据,transformers库封装了squad_example_convert_features这个方法来进行数据预处理。下面是对这个方法的简要介绍。
squad_example_convert_features方法
squad_convert_examples_to_features 方法用于将 SQuAD 数据集中的示例(examples)转换为模型的特征(features)。这个函数的主要目的是将原始的 SQuAD 数据转换为适合训练和评估的特征格式,以便用于训练和评估问答模型。该函数的参数如下图所示:
transformers.data.processors.squad.squad_convert_examples_to_features(
examples: Union[List[InputExample], str],
tokenizer: PreTrainedTokenizer,
max_seq_length: Optional[int] = 384,
doc_stride: Optional[int] = 128,
max_query_length: Optional[int] = 64,
is_training: bool = True,
return_dataset: Optional[str] = None,
threads: Optional[int] = 1,
tqdm_enabled: Optional[bool] = True,
squad_v2: Optional[bool] = False
)
对上面参数的含义解释如下所示:
tokenizer: 预训练模型的分词器。max_seq_length: 输出特征的最大序列长度。doc_stride: 用于处理长文本的步幅(stride)。max_query_length: 问题的最大长度。is_training: 是否用于训练。如果设置为True,将返回 PyTorch 数据集。return_dataset: 如果设置为"pt",将返回 PyTorch 数据集;如果设置为"tf", 将返回 TensorFlow 数据集。threads: 处理示例的线程数。tqdm_enabled: 是否启用 tqdm 进度条。squad_v2: 是否是 SQuAD 2.0 数据集。
其中,doc_stride 是在处理长文本时的步幅(stride),它决定了模型在上下文中滑动的步长。在处理长文本时,将整个文本输入模型可能会超过模型的最大输入长度限制。为了应对这种情况,我们可以将文本分成多个片段,每个片段包含一部分上下文,并使用滑动窗口的方式在文本中移动。具体来说,doc_stride 的作用是控制两个相邻片段之间的重叠部分,以确保模型在处理每个片段时可以利用相邻片段的上下文信息。max_seq_length(最大序列长度): 该参数限制了输入序列(包括问题和上下文)的总长度。max_query_length(最大问题长度): 该参数用于限制输入中问题的长度。
如果要调用这个方法对squad数据进行处理以及模型微调,官网是给出了完整的code例子。
? 在实际项目中,如果是某个领域的特定数据,可能并没有已经封装好的数据预处理方法可以调用,所以,学习掌握数据预处理过程是非常有价值的。具体数据应该转换成什么格式,还需要与选训练的模型和训练的目标有关。
模型训练代码
数据预处理理解后,后面的代码就相对简单了,基本都是固化格式的代码,具体如下图所示:通过dataset.map()方法对下载的所有原始数据进行数据预处理。在TrainingArugments中设置微调的超参数,调用Trainer对象进行训练。下面的代码中用到了data collator。在Hugging Face Transformers库中,default_data_collator是一个数据整合器(data collator)的默认实现。数据整合器用于将一批(batch)的样本组合成适合输入模型的格式,通常用于训练时的数据加载和批处理过程。
from transformers import AutoModelForQuestionAnswering, TrainingArguments, Trainer
from datasets import load_dataset
model = AutoModelForQuestionAnswering.from_pretrained(model_checkpoint)
batch_size=64
model_dir = "models"
model_name = model_checkpoint.split("/")[-1]
datasets = load_dataset("squad_v2")
tokenized_datasets = datasets.map(prepare_train_features,
batched=True,
remove_columns=datasets["train"].column_names)
args = TrainingArguments(
f"{model_dir}/{model_name}-finetuned-squad",
evaluation_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=3,
weight_decay=0.01,
)
from transformers import default_data_collator
data_collator = default_data_collator
trainer = Trainer(
model,
args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
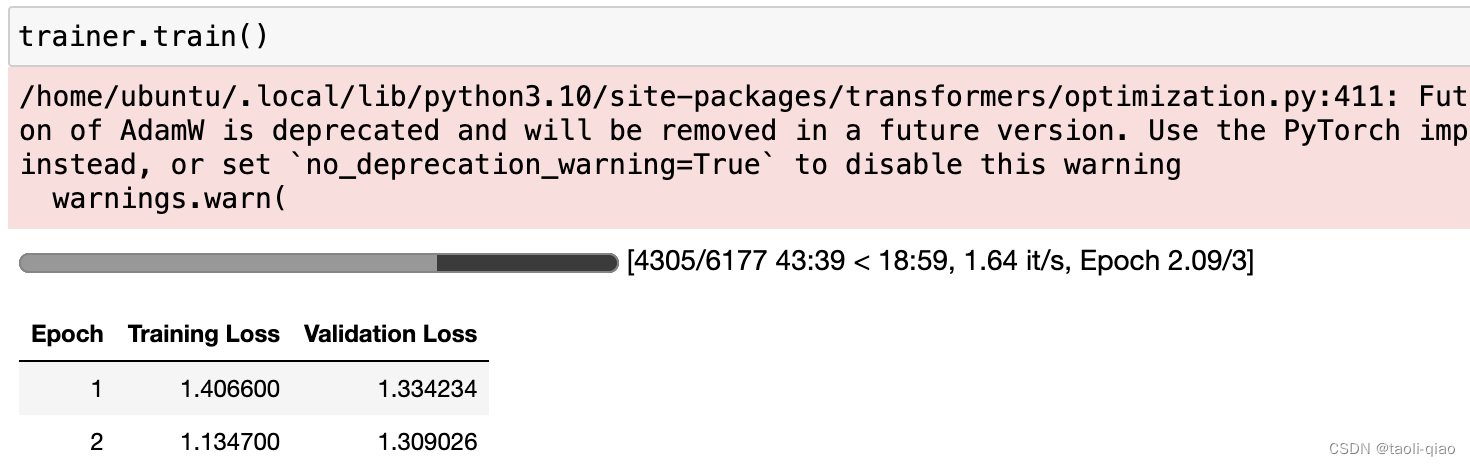
)调用trainer.train()方法开始模型微调训练,剩下的就是等待训练完成了。
以上就是对如何通过squad数据集训练问答模型的介绍。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Pandas实战100例-专栏介绍
- 力扣精选算法100题——找到字符串中所有字母异位词(滑动窗口专题)
- C/C++ 基础函数
- 小周带你读论文-2之“草履虫都能看懂的Transformer老活儿新整“Attention is all you need(1)
- CDP外采选型要考虑3个维度
- AI绘画生成器对室内设计有哪些帮助?
- Linux上iPortal 配置80端口的http
- Adobe illustrator各版本安装指南
- 力扣 面试经典150算法题
- WAZUH的安装、设置代理