力扣精选算法100题——找到字符串中所有字母异位词(滑动窗口专题)
第一步:了解题意

给定2个字符串s和p,找到s中所有p的变位词的字串,就是p是"abc",在s串中找到与p串相等的字串,可以位置不同,但是字母必须相同,比如”bca","bac"等,都是可以被称之为变位词。最终返回与p串字母相等但排列不同的字符串的初始索引即可。
例如 P="abc" { "abc","acb","cab","cba"}都是它的异位词。
S=“cbaebabacd" P="abc"
 符合条件的2组"cba"起始索引是0,"bac"起始索引是6,所以结果是[0,6].
符合条件的2组"cba"起始索引是0,"bac"起始索引是6,所以结果是[0,6].
第二步:算法原理
首先看到这个题目我们就会想到如何快速判断2个字符串是否是"异位词"
- 统计字符串中字符出现个数统计 统计就用hash表
这时候我们就想到了hash表,哈希表用来记录出现个数,对于下标的映射。首先给hash表各个元素都设置成0,然后依次存入a计入,然后让字符a的个数++,a的映射就是1,依次记录。所以p和s的字符串都用hash表来记录。
第一种解法:暴力枚举+哈希
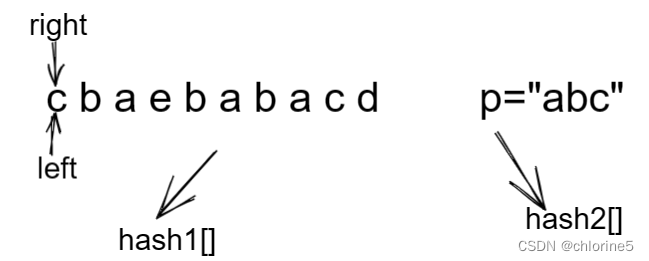
首先我们将P字符串依次存入hash1表中,Q字符串依次存入hash2表中。
定义2个指针都从头开始,依次计入hash2表中,然后当right-left+1>P字符串的长度时候,我们就判断俩个哈希表是否相等。然后清空hash2表。
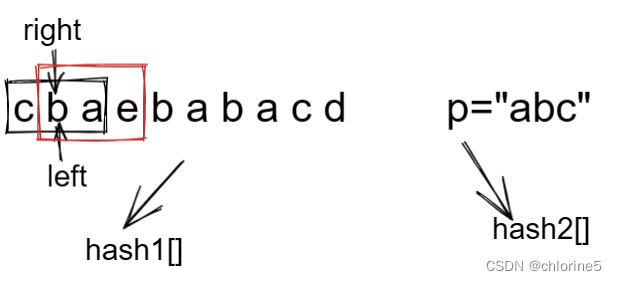 再存入新的值之前我们需要给"cba"存入hash2表值去才能重新存入。
再存入新的值之前我们需要给"cba"存入hash2表值去才能重新存入。
这样我们看着肯定是很繁琐的,为什么right要重新回到left下一个位置重新开始呢?为什么不right++呢?这就是可以优化的地方。
所谓优化就是:
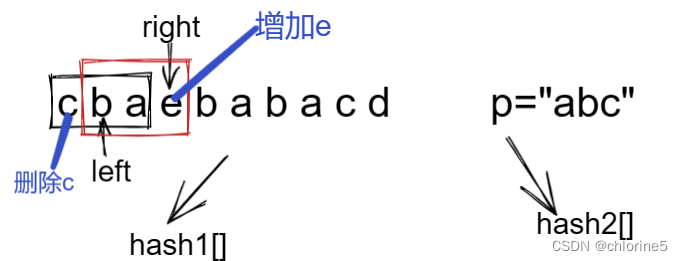
right不往回跑,left往后++,就是删除left所在的位置的值在hash2表中,增加right后面对应的值存入hash2表中。
第二种解法:滑动窗口+哈希
滑动窗口的模板:
1.left=0,right=0;
2.进窗口
3.判断
4.出窗口
更新结果(这是是在上面的4个步骤中根据题目的不同来穿插的)
2.进窗口
 将right对应的值存入到hash2表中去。
将right对应的值存入到hash2表中去。
3.判断
 当right-left+1>len(p),那么我们就要进行判断了。这时候开始出窗口了。
当right-left+1>len(p),那么我们就要进行判断了。这时候开始出窗口了。
4.出窗口
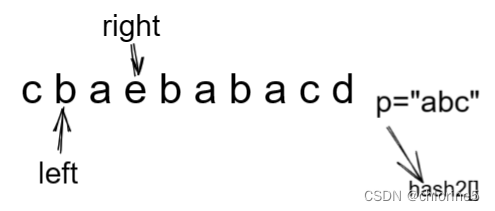 出窗口其实就是left对应的值从hash2表中删除,然后left++即可。
出窗口其实就是left对应的值从hash2表中删除,然后left++即可。
肯定很多人想知道这里是如何更新结果的,我们如何和p字符串进行判断?
?5.更新结果
我们可以再进窗口的时候就对其进行操作为后续的更新结果奠定基础。
主要进行的步骤就是 进窗口(后)对count的更新 和 出窗口(前)对count的更新
利用count变量来统计窗口中"有效字符"的个数
in和out就是对应的字符
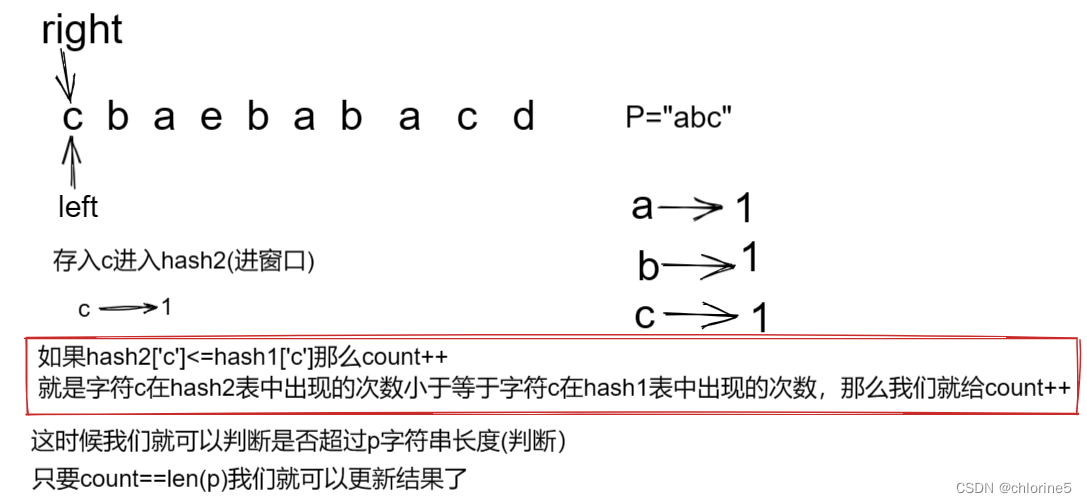
进窗口:进入后 hash2[in]<=hash1[in] count++;
出窗口:? 出去前?hash2[out]<=hash1[out] count--;
更新结果 count==len(p) ;
进窗口+count维护
更新结果

出窗口+count维护

这就是进窗口(后)和出窗口(前)进行count维护。
第三步:实现代码
class Solution {
public:
vector<int> findAnagrams(string s, string p)
{
int hashp[26]={0};//统计p字符串中各字符的个数
vector<int>ret;//记录结果
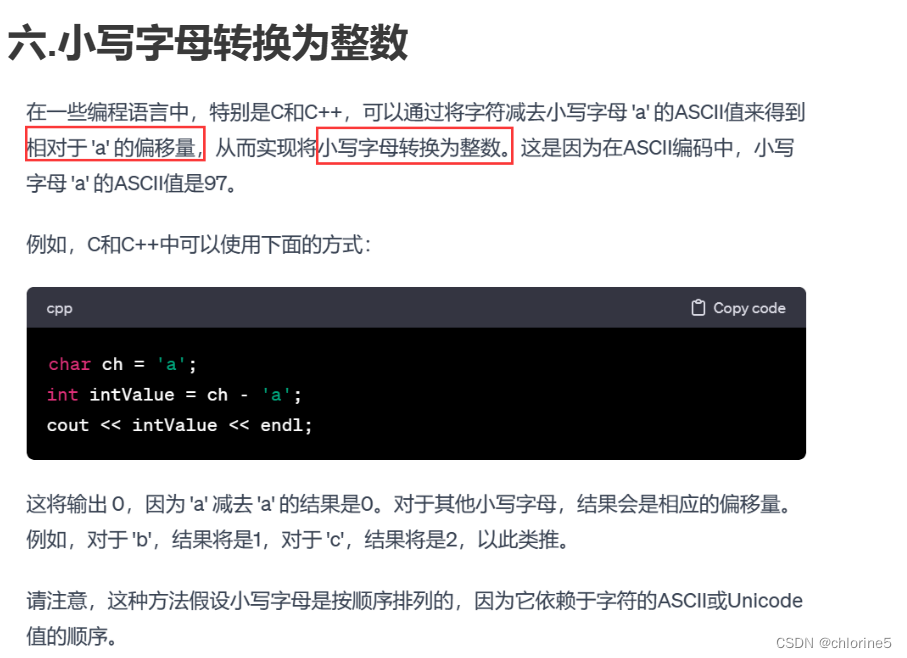
for(auto ch:p) hashp[ch-'a']++;
int hashs[26]={0};//统计s字符串中各字符的个数
int left=0,right=0;
int len=p.size(),count=0;
while(right<s.size())
{
if(++hashs[s[right]-'a']<=hashp[s[right]-'a'])count++;//进窗口+维护count
if(right-left+1>len)//判断
{
if(hashs[s[left]-'a']--<=hashp[s[left]-'a'])count--;//出窗口+维护count
left++;
}
//更新结果
if(count==len) ret.push_back(left);
right++;
}
return ret;
}
};小知识:
正在寒假的提升版。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!