【读书笔记】《重构_改善既有代码的设计》重构的方法论
重构的方法论
标题:【读书笔记】【读书笔记】《重构_改善既有代码的设计》重构的方法论
时间:2024.01.14
作者:耿鬼不会笑
重构是什么?
什么是重构:
“重构”这个词既可以用作名词也可以用作动词。
重构(名词):对软件内部结构的一种调整,目的是在不改变软件可观察行为的前提下,提高其可理解性,降低其修改成本。
重构(动词):使用一系列重构手法,在不改变软件可观察行为的前提下, 调整其结构。
重构 != 性能优化:
重构与性能优化有很多相似之处:两者都需要修改代码,并且两者都不会改变程序的整体功能。
两者的差别在于其目的:重构是为了让代码“更容易理解, 更易于修改”。这可能使程序运行得更快,也可能使程序运行得更慢。在性能优化时,我只关心让程序运行得更快,最终得到的代码有可能更难理解和维护。
重构应该永远是一种经济驱动的决定:
重构是一种经济适用行为,而非道德使然,如果它不能让我们更快更好的开发,那么它是毫无意义。
重构的唯一目的就是让我们开发更快,用更少的工作量创造更大的价值。
重构的意义:
重构对个体程序员的意义是提高ROI。
- 更快速的定位问题,节省调试时间。
- 最小化变更风险,提高代码质量,减少修复事故的时间。
- 得到程序员同行的认可,更好的发展机会。
重构对整个研发团队的意义是战斗力的提升。
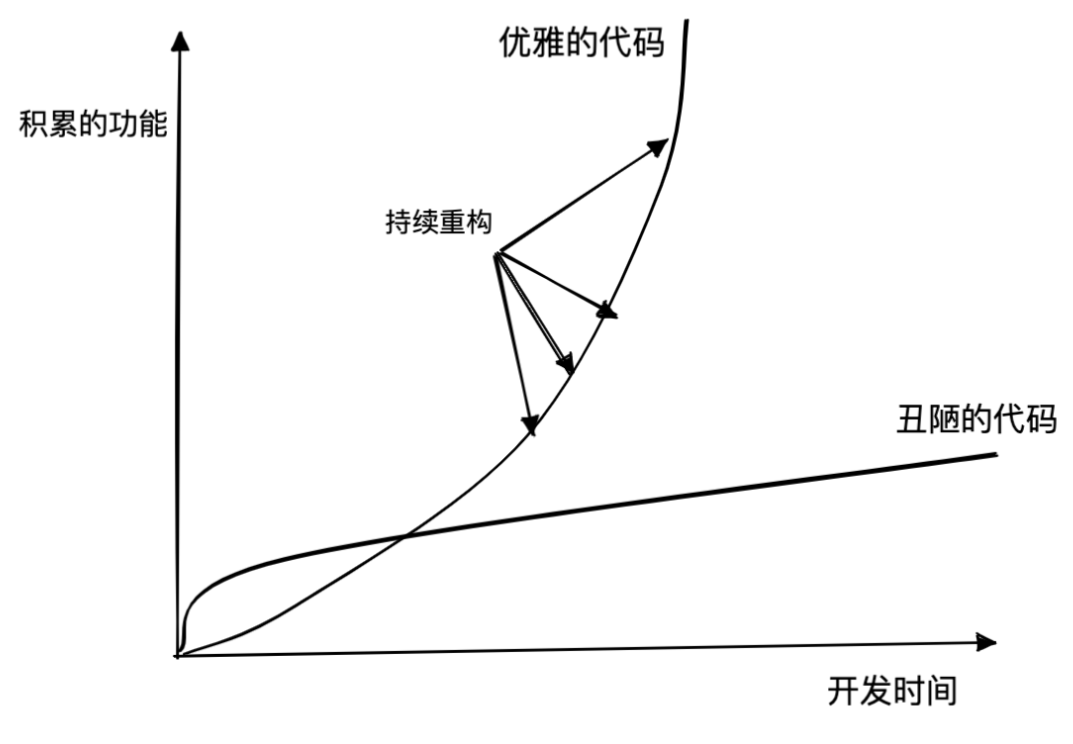
重构的原则
- 重构的目标: 提高迭代效率。
- 获得同行认可的方法: 每一次提交代码,都应该使代码变得更好,先重构,再开发。
- 增量式重构 = 自动化测试+持续集成+TDD驱动重构。
什么时候需要重构?
三次法则:
Don Roberts给了我一条准则:第一次做某件事时只管去做;第二次做类似的事会产生反感,但无论如何还是可以去做;第三次再做类似的事,你就应该重构。 正如老话说的:事不过三,三则重构。
预备性重构:让添加新功能更容易
重构的最佳时机就在添加新功能之前。在动手添加新功能之前,我会看看现有的代码库,此时经常会发现:如果对代码结构做一点微调,我的工作会容易得 多。
帮助理解的重构:使代码更易懂
我需要先理解代码在做什么,然后才能着手修改。这段代码可能是我写的, 也可能是别人写的。一旦我需要思考“这段代码到底在做什么”,我就会自问:能 不能重构这段代码,令其一目了然?当你接手一个异常难读的项目时, 说服项目组将重构作为一项需求任务来做。
捡垃圾式重构
帮助理解的重构还有一个变体:我已经理解代码在做什么,但发现它做得不好,例如逻辑不必要地迂回复杂,或者两个函数几乎完全相同,可以用一个参数化的函数取而代之。如果重构需要花一些精力,甚至会阻塞当前的任务,那么只需要将这块需要重构的代码记录下来,每次经过这段代码时都把它变好一点点,积少成多,垃圾总会被处理干净。每次 commit 代码时: 每一次经你之手提交的代码都应该比之前更加干净。
有计划的重构和见机行事的重构
见机行事的重构:我并不专门安排一段时间来重构,而是在添加功能或修复bug的同时顺便重构。例如:预备性重构、帮助理解的重构、捡垃圾式重构
有计划的重构:如果团队过去忽视了重构,那么常常会需要专门花一些时间来优化代码库,以便更容易添加新功能。 在重构上花一个星期的时间,会在未来几个月里发挥价值。当迭代效率低于预期时,将重构当作一个项任务专门来做,必要的时候停下来迭代需求。
长期重构
如果一些大型的重构可能要花上几个星期,例如要替换一个正在使用的库,或者将整块代码抽取到一个组件中并共享给另一支团队使用,再或者要处理一大堆混乱的依赖关系,等等。 这样的情况下,可以让整个团队达成共识,在未来几周时间里逐步解决这个问题,这经常是一个有效的策略。每当有人靠近“重构区”的代码,就把它朝想要改进的方向推动一点。这个策略的好处在于,重构不会破坏代码——每次小改动之后,整个系统仍然照常工作。
复审代码时重构
在给别人code review时嗅出坏味道,可以适当的提出重构的建议。
何时不应该重构
如果我看见一块凌乱的代码,但并不需要修改它,那么我就不需要重构它。 如果丑陋的代码能被隐藏在一个API之下,我就可以容忍它继续保持丑陋。只有 当我需要理解其工作原理时,对其进行重构才有价值。 另一种情况是,如果重写比重构还容易,就别重构了。
重构的手段
参考:重构:改善既有代码的设计
一种自底向上的演进方法
| 名称 | 目的 | 场景 | 做法 |
|---|---|---|---|
| 提炼变量 | 让表达式更加可读 | 当存在难以阅读的表达式时(逻辑&计算) | 划分子表达式使用有意义的名称命名子表达式 |
| 提炼函数 | 将意图与实现分离 | 有大量重复的逻辑段时如果需要浏览一段代码才能理解其在做什么时 | 识别变量依赖给函数命名确定函数体的存放位置构造参数,在目标位置进行调用编译,测试 |
| 封装类型 | 高内聚,低耦合 | 大量重复的,相同/相似变量被同时传递存在大量参数与逻辑无需关心。 | 从函数的变量和行为上发现相关性从高度相关的函数中抽象出一个概念将概念具像化为一种类型/对象为其设计合理的名称以及生命周期 |
| 模块化 | 逻辑划分,代码复用 | 当一些类需要频繁配合完成一个独立的功能时 | 关注点分离,抽象出模块/类库模块内部类相互紧密协作模块外部通过接口相互调用模块之间保持单一方向进行依赖 |
| 封装阶段 pipeline | 保持单一原则 | 一段函数中处理存在处理多种事情时多个if/else代码杂糅在一起时逻辑分支膨胀&循环冗余 | 抽象出多个任务阶段,并对阶段命名将阶段和处理的参数对象进行分离利用接口/多态特性替换if/else模式 |
| 委托模式 | 分离变化与不变的逻辑 | 被调用方会频繁变更时 | 封装接口,通过依赖倒置隔离下游变更 |
| 服务化/多进程 | 资源隔离(机器&人力) | 当某一个接口需要大量的状态与资源时为了提高运行时的稳定性时 | 注册一个新的git仓库迁移代码,搭建CICD流程 |
| 配置化 | 提高研发效率,减少重复需求 | 当存在反复的大量的重复的需求时业务需求频繁,疲于应付需求 | 抽象通用业务模型 |
| 领域化 | 微服务的划分,拆分核心领域 | 当具有一组完整业务交付价值的功能需要复用时 | 提供完整的架构方案设计对外接口,提供SDK完善接入流程 |
| 中台化 | 研发效能复用 | 当公司多个业务具有相同功能时 | 在系统化的基础上进行多租户化权限/资源管理 |
| 平台化 | 自动化业务流程 | 当业务需求模式清晰,需要边界明确时当研发成本成为最大成本时当要规模化获客接入时 | 抽象自动化流程pipeline将研发介入的流程配置化将配置通过平台调度自动化权限/资源/计量/计费/数分 |
| 产品/开源化 | 向公司外部提供产品服务榨取研发资源的剩余价值产品复杂度过高,超出内部研发能力 | 技术资源不能创造更大价值时市场需求明确,规模化获客与续约不成问题时用户增长逻辑明确时 | 提供对外open api 提供产品化的角色/权限/资源管理能力恰到好处的处理客户/用户使用问题 |
参考资料
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!