并发编程不能离开的锁
一、锁的作用
并发编程的问题
????????在日常开发中最简单的编程方式即串行化处理,所有的任务都是按照顺序一个一个执行,就像最早电子管时代的穿孔打卡编程。但串行化任务处理的最大弊端就是效率太差。现在的计算机都是多核处理器,串行化的任务处理模式完全不能充分发挥处理器的性能。因此,为了充分利用计算机资源,我们都要通过并发编程的方式来提高资源利用率。然而,多任务处理在提高效率的同时,会引入其他的问题,其中最重要的就是数据的安全性。当多个任务同时处理一个变量时,由于是并发处理,此外还会有编译器和处理器的指令重排序,所以会出现不可预知的结果。这就涉及到并发编程中的可见性、原子性和有序性三大问题。
? ? ? ? 如果做过电商的话,经常会遇到商品库存变更的问题,我上一份工作主要是财务结算业务的,所以会经常涉及到账户金额的修改。这两种场景都涉及到并发问题,尤其是对热点商品或者热点账户,问题更加突出。如果不加锁,那么可能导致两个并发扣减请求导致余额或库存字段变成负数或者是修改成一个错误的数字。如何通过锁的机制保证我们数据的一致性,准确性,且同时不会影响整体的性能,这是最关键的。
? ? ? 像操作系统如Linux本身就是一个典型的多租户,多任务的操作系统,锁是必不可少的,锁用于进程的调度,资源的管理,内存分配等各种并发场景。
这里再举两个简单的例子阐述锁的必要性。
public Integer a = 0;
public void getA(){
return a;
}
public voic setA(Integer value){
a = value;
}
public void modify(){
Integer a = getA();
setA(++a);
}????????上面代码中,主要是获取变量,并将值进行更新。当串行执行时,没有任何问题。但如果同时有两个任务进行处理,两个任务同时先取a,结果取到的都是0,随后更新a的值,最后a的值并不是想要的2,而是1。实际上这个更改账户余额是一样的,也是先取出余额,然后再更新。
????????另外一个例子,说明因为指令重排序导致的问题。
int a = 1;
int b = 2;
public void read(){
if (b == 3){
int y = a*a;
}
public void write(){
a=2;
b = 3;
} ????????write方法中的两个语句没有依赖关系,因此在单线程内会被重排序。这就可能导致b=3先执行,随后read方法先读取到b==3,然后执行y=a*a,这里 的a的当前值是1,即y=1。
锁的介绍
????????为了解决上述的问题,一个最常见的解决方案就是加锁。通过加锁,保证了操作的原子性,只有获得锁的任务才能执行相关流程,从而保证最后得到的结果是可预知的。比如在电商系统中,下单支付后更改库存,通过使用悲观锁或者乐观锁来保证不会超售。
????????锁是用于控制多任务同时访问共享资源的一种同步机制。
????????通常,我们会将锁分成两大类,悲观锁和乐观锁。悲观锁即认为一定存在竞争,所以在处理之前加上互斥锁,存在排他性,只有获得到该锁的任务才能处理,其他的会被挂起。
????????相比于悲观锁,乐观锁认为不是总是存在冲突,它在处理之前不会像悲观锁一样加上锁,而是在执行数据更新时,利用版本号和CAS来实现数据的更新。比如Mysql中的MVVC,Java中的CAS更是随处可见,比如atomic下的多种原子类,locks下的锁等等。
? ? ? ? 当然这里不是说,乐观锁一定比悲观锁性能更好,只是说两者适用的场景不近相同,如果并发量异常高,你总是进行CAS操作,那性能可能更差,因为你会多出很多无效的操作。
? ? ? ?本文会介绍Linux,JAVA,Mysql的锁以及用于进程间的资源同步的分布式锁。
死锁、活锁
????????锁是在并发编程中最重要的同步机制,但是也不能贪杯,不能过度使用锁,也不能随意使用。过度使用锁可能会降低整体性能,如果锁的粒度比较大,那就会导致几乎一直都是单个任务处理,此外由于上下文切换导致其性能还不如串行化处理方式。另外随意使用锁可能会出现死锁现象,这是一个比较常见,且严重的问题。想要避免死锁,就是要避免产生死锁的几大条件的发生。死锁产生的条件是:
1、非抢占式系统;非抢占保证了进程或者线程不会主动抢占其他已被占用的资源
2、互斥;资源占用具有排他性
3、请求和保持; 已经占用的资源不会被释放,会一直保持
4、循环等待;不同任务循环等待,首尾相接,形成了一个闭环;
看到了死锁的产生条件,我们就要避免其发生,这也是我们平时在开发时要注意的一点。解决策略主要也是分成两种,一是避免死锁,二是解决死锁。避免就是预防,不让死锁发生。比如对于不同的线程在申请资源时最好是同样的顺序。如有资源A和资源B,线程1,线程2在申请时,最好都保持先申请A,再申请资源B,不要反着来。此外还有一种著名的避免死锁的算法叫做银行家算法。感兴趣的可以参考:详解操作系统之银行家算法(附流程图) - 知乎
下面是一个简单的死锁例子:
public class DeadLock {
public static final Object objA = new Object();
public static final Object objB = new Object();
public static class ThreadA extends Thread {
@Override
public void run() {
synchronized (objA){
try{
TimeUnit.SECONDS.sleep(10);
}catch (Exception e){
}
synchronized (objB){
System.out.println(objB);
}
}
}
}
public static class ThreadB extends Thread {
@Override
public void run() {
synchronized (objB){
try{
TimeUnit.SECONDS.sleep(10);
}catch (Exception e){
}
synchronized (objA){
System.out.println(objA);
}
}
}
}
public static void main(String[] args) throws InterruptedException {
ThreadA threadA = new ThreadA();
ThreadB threadB = new ThreadB();
threadA.start();
threadB.start();
threadA.join();
threadB.join();
}
}除了预防死锁的发生,也可以在死锁发生时进行处理,比如可以通过定时检测死锁,解除死锁等方式。
????????和死锁相对应的一个现象是活锁。活锁最大的特点它不会保持,还是上面的例子,线程1获取到A再获取资源B时,如果失败了,就会放弃资源A,再去重新获取资源A和B;线程2获取到B再获取资源A时,如果失败了,同样放弃资源B,再去重新获取资源B和A。也就是说,两个线程在获取不到全部资源时,就会放弃占用资源,随后接着再按照相同的顺序去获取资源,如此反复,导致两个线程永远获取不到全部资源,也不会执行响应任务。对于活锁,维基百科有比较好的解释:
两个人都没有停下来等对方让路,而是都有很有礼貌地给对方让路,但是两个人都在不断朝路的同一个方向移动,这样只是在做无用功,还是不能让对方通过。
? ? ? ? 另外一个比较典型的例子就是RedisCluster集群,其基于Raft算法进行选举,当某个master节点挂掉,要从slave种选举出新的master,在同一个term内,很有可能出现几个slave获得了相同的投票,当获得相同投票时,Redis只能进行下一次选举,直到在某一个周期term内选举成功。上述这种现象就是一种活锁现象。
? ? ? ? 如果了解Redis的人会知道,为了避免上述现象发生,Redis的做法是如果从节点发现主节点下线,就会等待一段随机时间长度后,向其他master节点发送一条广播消息,给自己拉票,希望自己成为主节点。每个slave等待的时间是随机的,而不是固定的时间,即有先后顺序。这也是解决活锁的标准方案。
二、Linux中的锁
????????操作系统的锁是所有的锁的灵魂,是因为其他语言或者应用都是借助操作系统的锁机制来实现的,因为我平时都是使用Linux,所以这里介绍Linux中的锁。
????????Linux做为一种典型的多用户、多任务的操作系统,通过特殊的同步机制来保证多任务并发或并行处理的安全性。主要包括信号量、互斥锁、自旋锁、读写锁、RCU等。
1、信号量
????????信号量英文叫做Semaphore,看到这,JAVA程序员应该很熟悉吧,多线程编程中,JAVA并发包提供了一个类叫Semaphore。在Linux中,同样有个叫Semaphore的机制,如果你参加过面试,有时面试官会问你,进程间通信都有哪些机制,其中一个就是信号量,不过信号量不仅仅用于进程间通信,还可以干很多事情,如内核资源管理、中断处理、进程调度等等。
? ? ? ? 信号量本质类似一个计数器,它会在初始时设置成一个固定值,随后进程成功获取资源后,会将信号量减去1(对应的是P操作),释放后,信号量加1(对应的是V操作)。linux对应的结构体如下:
struct semaphore {
spinlock_t lock;
unsigned int count;
struct list_head wait_list;
};????????其中count就是对应的信号量值,当然对count的加减操作是原子性的操作,且对其他进程(线程)可见。只有当信号量为非负数时,才能获取资源,否则将对应的进程会放入等待队列wait_list,并将其状态改为休眠。该等待队列本质上是一个链表结构,如下:
struct semaphore_waiter
{
struct list_head list;
struct task_struct *task;
int up;
};????????当进程执行完之后,如果等待队列是空的,直接将count值+1,否则就会唤醒等待队列中的进程(或线程)。
????????通常情况,信号量主要是用于在同一时间只能被有限个任务访问处理的场景。比如同时我只允许最多100个人在打球,多了不可以。这有点像限流里的令牌桶,最多我发这么多,超过这些就不发了。为了直观,我用JAVA来演示信号量的使用。但还是要注意,Java的信号量的实现和Linux系统的是不一致的,只是适用场景比较类似。
??public class SemaphorePra {
private static int count = 40;
private static ExecutorService executorService = Executors.newFixedThreadPool(count);
//这里定义了信号量的初始值,是10.
private static Semaphore semaphore = new Semaphore(10);
public static void main(String[] args){
//这里可以观察线程处理的情况。
for (int i=0;i< count;i++){
executorService.execute(new Runnable() {
@Override
public void run() {
try{
semaphore.acquire();
System.out.println(String.format("thread:%s",Thread.currentThread().getName()));
}catch (Exception e){
e.printStackTrace();
}finally {
semaphore.release();
}
}
});
}
}
}2、互斥锁
Linux通过mutex来实现互斥锁,实际上无论我们使用Java还是其他语言实现的互斥锁,最终都是通过操作系统的互斥锁来实现的。
mutex结构体如下:
struct mutex {
/* 1: unlocked, 0: locked, negative: locked, possible waiters */
atomic_t count;//原子操作类型变量
spinlock_t wait_lock;//自旋锁类型变量
struct list_head wait_list;
#ifdef CONFIG_DEBUG_MUTEXES
struct thread_info *owner;
const char *name;
void *magic;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};????????可以看到mutex和信号量比较类似,区别是其count只能是0或1两个值,其本质上也是信号量,所以也被称为二进制信号量。
????????那么问题是,count本身也是一个变量,又怎么保证获取并设置该标志位的过程是原子操作呢?
????????比较著名的一种做法是 test-and-set-lock(TSL,实际上就是咱们经常说的CAS),是一种不可中断的原子操作,实现方式有硬件或者软件的方式,它将count变量读取寄存器 RX 中,然后在该内存地址上存一个非零值,读取操作和写入操作从硬件层面上保证是不可打断的,即保证原子性。
????????上述原子操作,在单核系统是完全没有问题的,但在多核系统中,虽然是原子操作,但单靠它是完全没法做到CPU间的同步的。基于此,操作系统可以通过控制总线(比如保持同一时间只能有一个处理器操作),基于缓存锁定(保证同一时间只有一个处理器在操作缓存)或者其他实现方式。
????????通过这种结构,可以保证资源使用的排他性,同时只能有一个任务占用该资源。传统的mutex中如果进程(线程)获取锁失败,会直接进入等待队列,等待锁释放重新竞争锁。后续Linux对此进行了改进,当获取锁失败时,可以先不进入等待队列,而是采用自旋的方式,不必挂起。这种方式的目的也是为了减少进程挂起唤醒等操作。
3、自旋锁
????????自旋锁spinlock,刚才也提到了,它的主要思想就是当没有成功获取到锁时,并不会进入休眠状态,而是自旋等待,直到获取资源。相比于互斥锁,它并不需要挂起再被唤醒。其应用场景一般都是需要等待的时间比较短的情况,而互斥锁和信号量可以是执行时间比较长的场景。对于自旋锁,如果等待时间较长,自旋过程会一直占用CPU,这在一定程度上也浪费了资源。为了解决这个问题,一是尽量在等待锁的时间较短的情况下使用,此外也不能一味地等待,在等待一定时间时还获取不到就应该失败。这在后面介绍Java自旋锁的时候也会介绍。
4、读写锁
????????读写锁rwlock,是针对互斥锁的一个改进,即当读操作时,锁是共享状态,当写时,是互斥锁。这样是为了避免所有情况都加互斥锁,从而提升了并发性能。在我们日常的开发中,也基本上是读多写少的场景,没必要一定要独占。这个就将共享和独占很好得结合到了一起,如果大家平常都使用Mysql得话,就会知道Mysql也提供了shared和独占的锁。
????????读写锁存在的模式即读模式锁,写模式锁,无锁。其中写锁的优先级要高于读模式锁。当有写锁时,其他具有读锁的都会被阻塞。
5、RCU
????????RCU,全称时Read-copy-update,是在linux2.6中引入的。有点像写时复制,即CopyOnWrite(这个在零拷贝中是比较有用的一个概念)。当只是读时,不需要加锁;当进行写操作时,会拷贝一份副本,然后在合适的时候会将执行旧数据的指针更新为执行新数据。
????????相比于读写锁,RCU最大的变化是进行写操作时,读锁不需要被阻塞。此外,就是其修改对于其他任务来说可能不是立即可见的,有滞后性。因此对于数据具有敏感性,需要实时读到最新的场景,RCU是不合适的。另外,RCU由于需要进行副本拷贝,还要进行删除旧数据等一系列操作,所以其写锁的开销成本较大。因此,RCU在写操作越少的情况,其性能就越好。
????????
????????以上介绍了Linux的各种锁,并介绍各自的使用场景。在我们实际开发中可能并不会直接调用库函数来完成锁的实现,而是通过编程语言去调用,编程语言去负责Linux的系统调用。
三、JAVA中的锁
????????JAVA中的锁是用来控制多线程同时访问临界区时最重要的方式。在1.5版本之前只有sychronized这一种内置锁,且是比较重量级的,在后续的版本中,引入了Lock接口,并提供多种锁,此外sychronized实现了四种不同状态的锁,从而提升系统的性能;同时加入了atomic类,引入了乐观锁,即CAS,有的地方不把他当做锁,不过我认为这个就是悲观锁和乐观锁的区别。
总结目前JAVA的锁存在几大类:
? ? ? ? ?- sychronized内置锁
? ? ? ? -? Lock接口实现的锁
? ? ? ? -? atomic包下的CAS乐观锁
????????其中sychronized和Lock接口实现类本质上都是悲观锁,atomic包下的是采用CAS思想实现的乐观锁。悲观锁和乐观锁的区别不再赘述,首先说一下两种悲观锁的区别。
????????从上面对比可以看到,Lock接口实现类提供了更加灵活、丰富的锁特性,而不是sychronized那种固化的加锁模式,但也不是说sychronized就不能用,如果我们不需要Lock所提供的特性,完全没必要使用Lock实现类,因为sychronized经过1.6的升级,性能也很好。接下来详细介绍一下这几种锁。
1、synchronized
????????synchronized是Java的一个内置锁(JVM级别),是一种独占互斥锁。那么它到底是如何实现的呢?synchronized最传统(JDK1.6之前,现在只有膨胀到重量级锁才会出现)的锁依赖的是操作系统的Mutex Lock,关于mutex在Linux锁中已经有过介绍。这种传统的锁的方式比较重,因为如果线程抢不到锁的话,就会进入休眠状态,待有锁资源再被换起。休眠和换起的这两个状态,都是耗费CPU的,在1.6版本中又引入了轻量级锁和偏向锁(锁升级过程:无锁->偏向锁->轻量级锁->重量级锁)。其主要思想也是尽量无锁,或者采用自旋锁的方式避免线程休眠和唤醒。自旋锁在上也有讲过。在JDK1.6之后,在自旋锁的原有基础上又提出了自适应自旋锁。自适应自旋锁重试次数或时间不再固定,而是由前一次在同一个锁对象的自旋时间及锁地拥有着的状态来决定。如果上一个自旋时间很短。那它这次也认为自己可以获得锁,这时它就允许自旋时间长一些。
????????虽然自旋锁有很多优点,但也只有在满足一定条件下才可能得到性能的提升,比如多核,比如任务不能太过耗费时间等等。
???????这里需要注意的是Sychronized锁定的都是对象。我们可能在实际应用中会有不同的使用方式:
????????1、实例前加synchronized,实际上锁住的是该实例对象;
????????2、在类前面加synchronized,锁住的是该类对象;
????????3、在同步块前加synchronized,锁住的是括号里的对象;
public void add(){
synchronized (this){
}
}????????假如说一个类对象里有两个不同的静态方法都加了synchronized,那么这个锁是这个类对象,相当于全局锁,因此即使访问把不同的方法,同样是互斥的。
public static synchronized add(){
}???????对于非静态类方法,即实例方法,如果不同的线程操作的不同的对象,那么加锁是毫无影响的。如果是操作同一个实例对象,那会产生互斥。
public synchronized add(){
}?????????使用synchronized的代码块在编译的时侯会插入monitorenter(加锁)和monitorexit(解锁字节码指令。enter是插入到同步代码块开始的地方,exit是在方法结束和异常的情况。
????????对于被synchorized修饰的方法,会被一个叫ACC_SYNCHRONIZED的修饰,有该修饰的对象就会尝试获取锁资源。
? ? ? ? 注意这两种方式本质上没什么区别,都是创建monitor对象,只不过是前种需要显示地在字节码中指定加锁和线索。
????????对象应用的锁是保存在对象头中的,对象头中的MARK WORD主要存储hashcode,分代年龄以及锁的标志位头中保存的锁信息是什么,还要根据具体的锁机制有关,有重量级锁,轻量级锁还有偏向锁。通过synchronized最终指向了操作系统的Monitor实现了加锁,如图(图片来源于网络):

2、Lock接口锁
?Lock接口的锁包括如下几种:

- ?ReentranLock,纯互斥锁,悲观锁。
- ReentrantReadWriteLock,其中使用了ReadLock 、WriteLock,读锁共享,写锁互斥。说到这儿,我不得不提到CopyOnWriteArrayList,读写锁和CopyOnWriteArrayList都实现了读共享区别在于读写锁在出现写时会阻塞读,CopyOnWriteArrayList是一种写时复制的机制,在有写时,会复制一份到新的数组上,JAVA里有,Redis里同样有写时复制的思想。
- StampedLock 在读写锁的基础上增加了乐观读。
Lock的实现类都借助了AQS实现的。其实不仅仅是锁,还有其他的包括同步容器,比如Semaphore,CountDownLatch,FutureTask也都是基于此实现的。
AQS,全称AbstractQueuedSynchronizer,即同步器,如果看过该类的代码,你会觉得这就是艺术品,Doug Lea大神充分考虑了各种复杂的应用场景以及潜在的风险。本文不对该源码做分析,感兴趣的可以见我自己网站的一篇文章:?千与千寻-Java多线程共享变量同步机制及各种锁?。
简单说下AQS的基本思想。AQS本身维护了一个volatile变量叫state,这个大家应该都很熟悉了,可以保证可见性和禁止重排序。
此外,其维护了一个FIFO的双向队列,队列本质上就是一个双向链表,特别的是其head是个虚拟的节点,除此之外,每个节点都是一个Node,Node包含当前的waitStatus,前驱节点和后继节点。这个队列本质上就是一个等待队列。
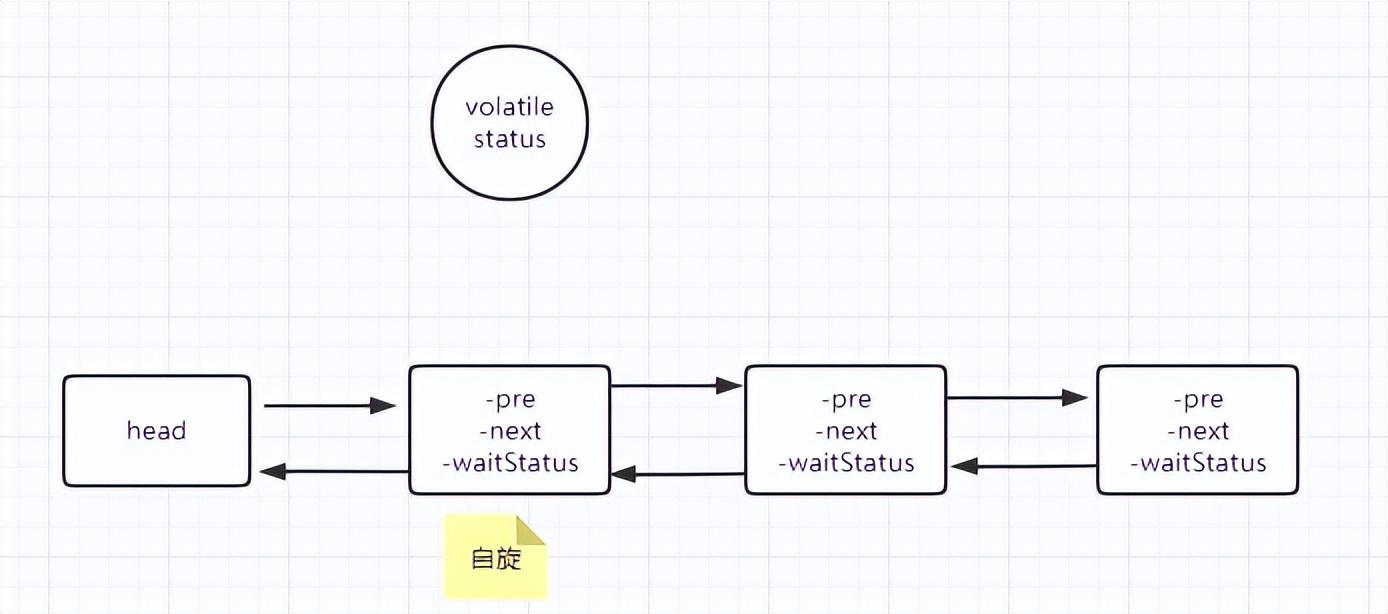
AQS支持互斥锁和共享锁两种模式,互斥锁就是ReentranLock这种,共享锁就是Semaphore,CountDownLatch这种。
这里就拿互斥锁来说。其获取锁的过程是:
1、线程尝试获取锁,这里调用的都是具体锁的实现类覆盖的方法,如ReentrantLock的tryAcquire;
2、如果获取成功,则直接执行同步代码块即可;如果获取锁失败,则继续向下进行; 3、将获取锁失败的前程通过CAS添加到队列尾部(这里处理比较特殊,可以看下源代码);
4、线程开始自旋,如果前节点是头节点,就尝试获取锁,如果获取成功了,就更改头节点;如果前节点不是头节点或者获取锁失败了,且前节点的waitStatus是SIGNAL(这个表示处于休眠状态),也直接进入休眠;如果是取消状态,则prev指针往前移;如果是其他的,则将前节点的waitStatus设置为SIGNAL。随后将线程挂起,进入休眠状态。这里要说明一下,waitStatus不影响当前节点,只影响后节点使用;
5、如果持有锁的线程执行完释放锁之后,就会唤醒头节点的后继节点,这个地方也比较艺术,就是如果next节点是SIGNAL状态,就直接唤醒,否则从队尾从后往前遍历,直到找到队中第一个waitStatus小于0的,再唤醒。
上面说的互斥锁的释放比较简单,共享锁要麻烦一些,因为共享锁可以被多个线程持有,这就会出现释放锁的并发问题,因此AQS又引入了一个PROPGATE的waitStatus常量,该常量可以完美解决因为共享锁,多线程并发引起的bug,当然这也是后来才修复的,最开始还真没有,感兴趣的可以看源代码哈,这里不做过多阐述。
使用AQS的场景比较多,包括ReentrantLock,Semphore,CountDownLatch,ReentrantReadWriteLock,线程池ThreadPoolExecutor。都会有使用。
| 同步工具 | 同步工具与AQS的关联 |
|---|---|
| ReentrantLock | 使用AQS保存锁重复持有的次数。当一个线程获取锁时,ReentrantLock记录当前获得锁的线程标识,用于检测是否重复获取,以及错误线程试图解锁操作时异常情况的处理。 |
| Semaphore | 使用AQS同步状态来保存信号量的当前计数。tryRelease会增加计数,acquireShared会减少计数。 |
| CountDownLatch | 使用AQS同步状态来表示计数。计数为0时,所有的Acquire操作(CountDownLatch的await方法)才可以通过。 |
| ReentrantReadWriteLock | 使用AQS同步状态中的16位保存写锁持有的次数,剩下的16位用于保存读锁的持有次数。 |
| ThreadPoolExecutor | Worker利用AQS同步状态实现对独占线程变量的设置(tryAcquire和tryRelease)。 |
这里说一下线程池ThreadPoolExecutor,其使用AQS的目的是,只能中断空闲线程,在尝试中断时,会调用tryAcquire,如果失败,则证明,线程正在执行任务,不可中断。在执行任务之前,会调用tryLock,其目的就是要加互斥锁,
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}可以看到,其是不可重入的。这是因为setCorePoolSize时,如果超过了设置数量,会中断线程,如果是可重入的,则会中断我们的线程。
这里只展示一下ReentranLock的部分源码:

关系图
该锁具备的特点一是可重入性,二是支持非公平和公平两种锁,三是可中断。
可重入性可以参考一下代码。以非公平锁为例,加锁的过程:
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
//同步状态state,volatile变量
int c = getState();
//处理尝试CAS加锁,并设置值为1(acquires传入的值基本上都是1)
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
//如果是当前线程,更新计数
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}释放锁:
? ?? protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
//如果重入锁全部释放了,就返回告知已经全部释放
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
//更新释放后的state
setState(c);
return free;
}
ReentrantLock第二大特点就是支持非公平和公平锁,非公平锁上面的代码已经展示了,即不会遵循FIFO,就算是后来了一个线程,也有可能先获得锁。其次是公平锁,公平锁会借助AQS的同步队列实现,调用如下函数:
public final boolean hasQueuedPredecessors() {
// The correctness of this depends on head being initialized
// before tail and on head.next being accurate if the current
// thread is first in queue.
Node t = tail; // Read fields in reverse initialization order
Node h = head;
Node s;
return h != t &&
((s = h.next) == null || s.thread != Thread.currentThread());
}只有满足以上条件才会获取锁,从而保证了公平性。
3、两种锁的对比
? ? 你可能经常会在网上看到,说Lock接口锁的性能会比sychronized要好,所以要考虑性能就要用Lock锁,实际上并不尽然。就像jdk源码中说的那样,Lock锁只是提供了相比于sychronized更多的功能特性,同时引入了支持不同条件的队列Condition。
?那具体说下Lock接口的新增的一些特性:
1、公平性。sychronized只支持非公平锁,而Lock接口两种均支持,其实现主要是借助于大名鼎鼎的AQS(AbstractQueuedSynchronizer),AQS维护着一个等待队列,如果是公平锁,当有其他线程等待时,后加入的线程不可直接获取锁,需要加入队列尾部。
2、可中断。这里说的可中断指的是在等待锁的过程中可中断,不是执行的过程中。sychronized不支持可中断的,而Lock接口时支持的,你会在源码中看到lockInterruptibly等带有Interruptibly字样的方法。
3、超时机制。超时机制同样指的是等待锁的超时时间,等待锁不是一直等待下去,而是到了一定时间,我就自动退出。sychronized是不支持超时的,而Lock支持的。
? 到了这里,应该就清楚了,sychronized会一直等待其他线程释放锁,而Lock就比较灵活了,支持可中断、支持超时等。
???????如果是从性能角度出发,而不考虑Lock接口的特性,那么就没必要使用Lock接口锁,而是使用内置的sychronized更好一些。在《Java并发编程实战》也有提到过说,sychronized的优势有三点:
? 1、sychronized的释放锁并不需要开发人员自己显示做,而是由虚拟机帮着做,而我们使用lock接口,必须在finally中显示地unlock一下锁。如果忘了做这步骤或者不是finally里做,就是灾难的。
? 2、sychronized这种内置锁使得我们可以输出线程堆栈的锁情况,也方便我们检测出出现死锁的情况。当然目前Lock接口也可以通过预留API的方式实现,但sychronized更加原生。
? 3、sychronized有时性能是好于Lock接口的。因为sychronized不仅仅提供了锁膨胀升级的优化,虚拟机还为其进行了锁消除等优化手段,从而提升其性能。
4、原子类
JAVA并发包提供了一系列原子类,通过使用原子类可以实现无锁编程,但实际上其是借助计算机的CAS对应的指令。通过使用原子类,在并发编程中,不需要再显示去加锁,即开发者完全可以忽略线程安全性的问题。其基本原理就是使用volatile和CAS完成的,这里拿AtomicInteger为例。
//value为volatile变量
private volatile int value;
//CAS操作
public final boolean compareAndSet(int expect, int update) {
//valueOffset是内存偏移量
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}????????Unsafe是JAVA提供的可以直接操作操作系统的类,可以进行内存管理,CAS操作,线程调度等等,但日常开发中,基本上是用不到的。
????????当然,原子类虽然好,但CAS操作还存在一个比较普遍的问题,即ABA问题。就是有个线程在修改的时候值是A,但可能值是被别的线程从A改到B,又从B改到A。那解决ABA问题,常见的方案就是加上版本号,每次进行update时,不仅比较当前值是否相等,还要比较版本号是否一致。原子类中就有一个类似的实现类可以使用:AtomicStampedReference。该类通过一个二元组,即保存值,又保存版本号。
private static class Pair<T> {
//引用
final T reference;
//版本号
final int stamp;
}
public boolean compareAndSet(V expectedReference,
V newReference,
int expectedStamp,
int newStamp) {
Pair<V> current = pair;
return
//地址和版本号要同时相等
expectedReference == current.reference &&
expectedStamp == current.stamp &&
((newReference == current.reference &&
newStamp == current.stamp) ||
casPair(current, Pair.of(newReference, newStamp)));
}四、Mysql锁
本文主要谈论InnoDB引擎的锁。下面是我画的一个思维导图,主要从不同维度去划分锁。

基于锁的属性分类:共享锁、排他锁
共享锁(S):加上共享锁之后,对应数据集合(行锁或者表锁)只能读,不能修改。当然共享锁可重复加,他也会阻止其他事务获取对应的排他锁。
现在我开启一个事务并加上共享锁。
mysql> begin;select * from c_group where user_id=33 lock in share mode;
Query OK, 0 rows affected (0.01 sec)
+-------+---------+-----------+--------+
| id | user_id | groupname | avatar |
+-------+---------+-----------+--------+
| 10016 | 33 | dwdaaa | dwd |
+-------+---------+-----------+--------+
1 row in set (0.00 sec)我再开启一个事务,执行修改。
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update c_group set groupname="dwd" where user_id=33;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
排他锁(X):排他锁就是我加上了,别人不可加任何的锁了,无论是共享锁还是排他锁,有时也称为排他写锁。
我再开启一个事务:
mysql> begin;select * from c_group where user_id=33 for update;
Query OK, 0 rows affected (0.00 sec)
+-------+---------+-----------+--------+
| id | user_id | groupname | avatar |
+-------+---------+-----------+--------+
| 10016 | 33 | dwd | dwd |
+-------+---------+-----------+--------+
这个开启了一个排他锁。
然后再打开一个事务:
ysql> begin;
Query OK, 0 rows affected (0.01 sec)
mysql> update c_group set groupname="dwd" where user_id=33;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
mysql> select * from c_group where user_id=33 ;
+-------+---------+-----------+--------+
| id | user_id | groupname | avatar |
+-------+---------+-----------+--------+
| 10016 | 33 | dwd | dwd |
+-------+---------+-----------+--------+
1 row in set (0.00 sec)
mysql> select * from c_group where user_id=33 lock in share mode;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
第二个事务的排他锁和共享锁都因为第一个事务已经加上了排他锁而报错了。
基于锁的粒度分类:表锁、行锁、记录锁、间隙锁、临键锁、插入意向锁。
表锁:即对整张表加锁,表锁的粒度比较粗,MyISAM存储引擎只支持表锁。当我们进行DDL(DML)操作或者查询条件没有索引的时候,都会使用表锁。当然也可以显示加表锁如Lock Table .....read (write)等。实际上表锁还可以细分,上面提到的DDL等操作实际上是属于元数据的锁,还有后面还提到的意向锁,以及自增锁。
????????自增锁是保证整个表全局的唯一性,最早的版本是只有事务执行完,自增锁才会释放,所以性能很差,后续的版本中为了提高性能,是只要获取了自增id就把自增锁释放掉,不必等到整个事务都执行完毕。
? ? ? 注意,表锁也会和行锁出现冲突的,除了意向锁以外哈,后面会介绍意向锁的作用。
行锁:在MyIsam中不存在,InnoDB支持行锁。但生效必须是通过索引查询的记录,否则不会生效。通过索引加的锁可以是单行,也可以是多行数据。其实记录锁,间隙锁,临建锁,插入意向锁都属于行锁的范围。
记录锁:精准锁住一条记录,一般都过主键或者唯一索引查询即可假如记录锁;
间隙锁:索引区间锁。和记录锁只锁住一行不同,间隙锁会把一个区间锁住。
简单说就是我们查询一个范围:
? ?mysql> begin;select * from c_group where user_id in (1,2,3) for update;事务提交前,不会允许插入或删除,解决了幻读的问题,当然只在RR隔离级别有效(这也是默认得隔离级别)。
比如我现在开启一个事务A,然后开启一个事务B
事务B执行:
select * from c_group where user_id>=123 and user_id<130;
+-------+---------+-----------+--------+
| id | user_id | groupname | avatar |
+-------+---------+-----------+--------+
| 10019 | 123 | wdw | qee |
| 10022 | 124 | wdw | qee |
| 10024 | 125 | wdw | qee |
+-------+---------+-----------+--------+
然后事务A执行insert,commit
insert into c_group (`user_id`,`groupname`,`avatar`) values(126,"wdw","qee");
因为MVCC快照读,事务B读到的还是上述结果集。
ysql> select * from c_group where user_id>=123 and user_id<130;
+-------+---------+-----------+--------+
| id | user_id | groupname | avatar |
+-------+---------+-----------+--------+
| 10019 | 123 | wdw | qee |
| 10022 | 124 | wdw | qee |
| 10024 | 125 | wdw | qee |
好,事务B执行insert,插入事务A同样的数据。
mysql> insert into c_group (`user_id`,`groupname`,`avatar`) values(126,"wdw","qee");
ERROR 1062 (23000): Duplicate entry '126' for key 'user_id'
这就是幻读的一种。
一种解决方式就是使用间隙锁。下面方式就是一种间隙锁的方式。
SELECT * FROM child WHERE id > 100 FOR UPDATE;
在事务中查询直接用select for update,这样就加了间隙锁。加了间隙锁之后,整个范围区间都会被锁住,即使对应数据可能不存在。因此假如间隙锁之后,其他事务就没法插入数据了,会被锁住,从而也就不会出现幻读了。
插入意向锁:插入意向锁其实是一种特殊的间隙锁,当执行insert的时候会有插入意向锁。上面提到间隙锁阻止其他事务插入,解决幻读的问题,实际上就是间隙锁和插入意向锁的冲突。但是插入意向锁和插入意向锁之间是不会冲突的,即当我们在同一个间隙内执行两个不同id的插入,是不会冲突的。
临键锁:是记录锁和间隙锁的组合,既解决脏读,也解决幻读。它锁住的是当前记录以及记录之前的数据,和间隙锁的开区间不同,临建锁是闭区间。比如我查询的是 id in (1,5,7),那么它锁住的是(-∞, 1],(1, 5],(5,7]。
基于是否可以锁住同步资源:悲观锁和乐观锁
这个就比较好理解了,因为在前面很多地方都提到过。我们通过select for update或者update ,delete加的都是悲观锁。通过悲观锁可以确保数据的一致性和准确性。但有时我们遇到的都是读多写少的情况,并不需要总是加悲观锁,即认为多数情况不会冲突,因此可以使用乐观锁。Mysql并没有提供现成的乐观锁供开发者使用,开发者需要借助额外的字段来实现,比如最常见的就是增加版本号字段。当在执行更新操作时,只有版本号和查询版本号一致的时候才可更新成功。
select version from users where id=1;
update users set name='he' where id=1 and version=version;基于状态:意向共享锁和意向排他锁
????????这两种锁是表级锁。当事务A对某个表中的某一行执行update操作时,为该行加入了行锁的同时,还会加入一个意向排他锁,假如有另外一个事务B想要锁表,那发现有意向排他锁,就会被阻塞。通过意向排他锁,事务B不需要校验每一行是否有排他锁,只需要看是否有意向排他锁就可以,大大提高了效率。但要注意,意向排他锁只是会限制表锁,不会和行锁发生冲突。
死锁问题
????????上面讲到了各种锁的分类,锁是保证同步的重要机制,但有锁的存在,势必会出现死锁的情况。那么出现死锁,Mysql是如何处理的呢?
????????处理方式主要包括两种,一是超时,二是死锁检测。超时比较好理解,事务长时间不提交,通过变量innodb_lock_wait_timeout控制,超时就自动回滚;
mysql> show variables like "%innodb_lock_wait_timeout%";
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| innodb_lock_wait_timeout | 120 |
+--------------------------+-------+
????????二是死锁检测,其基本原理就是构建一个以事务为顶点、锁为边的有向图,判断有向图是否存在闭环,如果存在就证明有死锁。具体实现这里就不做分析了。
????????上面是提到了死锁的处理方式,但解决死锁最好的方式还是预防,这就取决于我们平时写的sql了。总结几个尽量预防死锁的方式:
????????1)尽量避免大事务,避免长时间占用资源。我们很忌讳写大事务,写Java不是直接在一个方法上打上Transactional就完事大吉了,数据的操作要单独放一层,且避免大批量操作等;
????????2)要保证顺序性,这个在开始死锁的介绍也提到过。比如每个事务都是处理资源1,资源2,资源3,要保证每个事务都是按照同样的顺序去处理。;
????????3)避免一个事务同时占用过多的资源。这可以通过优化索引设计,sql等环节来实现。
????????4)事务中要使用索引或者主键来定位数据,避免占用过多的行,尤其是尽量避免表锁, 记录锁最好。
????????好了,上面说了Mysql的各种锁的分类,那Mysql锁的底层是靠什么实现的呢?
????????对于InnoDB引擎来说,其是一个多线程的处理引擎。其通过封装系统的mutex和信号量实现了互斥锁和读写锁。关于互斥锁和读写锁在Linux的锁介绍中已经介绍过,或者感兴趣的可以看下面的参考资料。
五、分布式锁
什么是分布式锁呢?
先看一段英文解释:
A distributed lock manager (DLM) runs in every machine in a cluster, with an identical copy of a cluster-wide lock database. In this way a DLM provides software applications which are distributed across a cluster on multiple machines with a means to synchronize their accesses to shared resources.
简单说,分布式锁的存在就是用来实现分布式系统中不同子系统的同步,控制不同节点对共享资源的同步访问,可以说成是分布式的互斥。
如何实现分布式锁?
分布式锁的种类
1、Mysql数据库锁
2、Redis分布式锁;
3、Zookeeper分布式锁;
4、基于ETCD实现的分布式锁;
1、Mysql数据库锁
????????是的,Mysql也可以说是提供了分布式锁,这是其天然的优势,通过悲观锁可以实现排他性。可以创建一个记录锁的表,并使用主键或者唯一键,根据独占锁来实现同步。比如下面的一张数据表:

????????但是用数据库实现分布式锁性能较差,首先写只能写单点,其次排他锁占用时间较长,会导致线程池耗尽,系统崩溃,再有就是很难实现复杂的场景,类如锁超时,中断,公平锁等。
2、Redis分布式锁
Redis简单使用方式:
set key value ex seconds||px milloseconds nx????????ex表示超时时间,nx表示只有不存在的时侯才可以创建成功。又由于Redis的命令执行是单线程的,这样就是分布式锁的完美实现。
????????其实在这之前,Redis还有一个是先执行 setnx(不存在时侯创建),然后再执行expire,设置超时时间,但是因为这不是一个原子操作,这意味着如果中间出现各种异常,都会出现错误。比如setnx执行完之后,redis服务挂了,或者网络挂了,总之没执行成功expire,那么这个锁就一直不会释放,假如某个线程执行时间非常长,一直不释放锁,那么整个系统可能会因此出现阻塞。
redis-cli:
ip> set test:lock true ex 100 nx上面就创建了一个锁,超时时间是100
用Java简单操作:
if(redisTemplate.opsForValue().setIfAbsent("test:lock",200,100,TimeUnit.SECONDS)){
log.info("redis testlock设置锁成功,value:200,超时时间为100秒");
}注意,上面在spring-data-redis 2.0版本以后才有,之前的得用execute去执行一下。
redisTemplate.execute(new RedisCallback<Boolean>() {
@Override
public Boolean doInRedis(RedisConnection connection) throws DataAccessException {
JedisCommands commands = (JedisCommands)connection.getNativeConnection();
String result = commands.set(key, value, "NX", "PX", unit.toMillis(timeout));
return "OK".equals(result);
}
});
上面展示了如何简单使用redis加锁。但现在考虑两个问题。
????????1、假如某个线程成功设置了这个锁,但是由于其业务逻辑执行太久,导致该锁超时被释放了;此时,另外一个线程抢到了这个锁,在这个线程执行的过程中,之前的线程突然执行完了,它最后的操作可能是要释放锁,那它就会把后来的线程锁给释放了,从而引发各种问题。这种情况该怎么解决呢?
????????其实很好解决,就是为锁的key设置不同的value,在线程中就是创建一个只属于该线程的随机数。这样在释放锁的时侯,如果该锁的value和自己一样,就释放,否则直接退出。简单逻辑是先用get方法取出该key的value,如果它和自己之前设置的value一致就执行del命令,删除。Redis可以使用lua脚本,使用lua可以轻松实现上面的原子操作。
下面的一个简单释放锁的例子:
@Component
public class RedisLock {
@Autowired
private ActivityRedisDao activityRedisDao;
@Autowired
private RedisTemplate redisTemplate;
public void addSimpleLock(){
Integer value = 200;
String key = "test:lock";
//加锁,并设置超时时间
if(redisTemplate.opsForValue().setIfAbsent(key,value,100,TimeUnit.SECONDS)){
log.info("redis testlock设置锁成功,value:200,超时时间为100秒");
}
try {
Thread.sleep(30000L);
}finally {
//释放锁
String luaScript = "local ret = redis.call('get',KEYS[1])\n" +
"if ret == ARGV[1] then \n"
+ "return redis.call('del',KEYS[1])\n"
+"else return 0\n"+
"end";
List<String> keys = new ArrayList<>();
keys.add("test:lock");
Object ret = activityRedisDao.runLuaScript(luaScript,keys,value);
}
}
}????????上面是Redis分布式锁的简单使用场景,如果更复杂的,可以使用Redisson,这也是Redis官网推荐的客户端,除了咱们上述说的实现,其还支持可重入、读写锁、信号量,支持锁的自动续期,底层基于Netty。性能强劲。
????????上面的例子就是Redis最简单的一种加锁方式,在单例中完全没问题,但实际应用中,Redis不可能只是以单例部署,部署方式都会采用哨兵或者Redis-Cluster等集群模式。在集群模式下,上面的方法是存在极大的不安全性。
????????比如在哨兵集群中,某个时刻加了一把锁,但是正巧注节点挂掉了,而此时由于主从同步延迟,锁还没有来得及同步到从节点。从节点成为主节点,但它并没有这把锁,此时别的线程是完全可以再接着加锁的。
????????基于此,Redis发布了一种加锁算法:RedLock。其实也是基于上面的基本思想。然后在整个集群中,通过同时加锁,达到目的。具体思想:
????????假设现在有N个master节点,这几个节点相互独立,不存在主从复制,其实就是目前比较稳定的Redis-Cluster。
获取锁:
????????1、首先获取当前时间戳,毫秒级;
????????2、客户端轮流地从所有实例中获取锁,直到成功地从超过一半(N/2+1)个实例中获取了锁为止;
????????3、此时这个锁的有效时间是最初始设置的有效时间减去获取锁的消耗时间。
????????4、假如客户端轮询完整个集群的实例之后,依然没有获得半数以上的锁,那么就要把所有之前已经获得的锁释放掉,整个流程也以失败告终。
????????5、如果获取了半数以上的锁,且最后的过期时间有效,那么就认为获取锁成功。
????????注意第二点中,客户端与每个节点都会有一个最大设置锁时间,如果超时就不再该节点建立锁,避免消耗太常时间。
????????此外,如果客户端没有获取到锁之后,也不要立即重试,否则会出现多个客户端申请同一把锁,然后导致谁也没成功。应该经过一段随机时间之后再重试。
????????释放锁,释放锁是遍历集群所有master节点,不管它实际上有没有锁。
????????好了,现在考虑这样一个场景。假如现在Redis集群有5个节点,一个客户端有了1,2,3三个节点的锁。
????????此时,突然服务器宕机了(不是执行Restart命令),那么此时还没有进行AOF,可能这台机器重启时就没有该锁了,而恰好另外一个客户端又申请了锁,那么此时就会造成两个客户端同时申请了锁。
????????这种情况目前最好的解决办法是等锁过期再重启,当然这种势必带来性能的下降。
RedLock基本上在常用的redis客户端中都有实现,Redisson更不必说,RedissonRedLock主要是继承了MultiLock,感兴趣的可以看看源码, 这里看一下python中的实现:
class Redlock(object):
def lock(self, resource, ttl):
retry = 0
val = self.get_unique_id()
# Add 2 milliseconds to the drift to account for Redis expires
# precision, which is 1 millisecond, plus 1 millisecond min
# drift for small TTLs.
drift = int(ttl * self.clock_drift_factor) + 2
redis_errors = list()
while retry < self.retry_count:
n = 0
start_time = int(time.time() * 1000)
del redis_errors[:]
#遍历所有节点
for server in self.servers:
try:
if self.lock_instance(server, resource, val, ttl):
n += 1
except RedisError as e:
redis_errors.append(e)
elapsed_time = int(time.time() * 1000) - start_time
validity = int(ttl - elapsed_time - drift)
if validity > 0 and n >= self.quorum:
if redis_errors:
raise MultipleRedlockException(redis_errors)
return Lock(validity, resource, val)
else:
for server in self.servers:
try:
self.unlock_instance(server, resource, val)
except:
pass
retry += 1
time.sleep(self.retry_delay)
return False
def unlock(self, lock):
redis_errors = []
for server in self.servers:
try:
self.unlock_instance(server, lock.resource, lock.key)
except RedisError as e:
redis_errors.append(e)
if redis_errors:
raise MultipleRedlockException(redis_errors)????????不过,RedLock还是存在很大弊端的,不能完全保证准确性。此外它还严格依赖时钟,比如一个服务器时钟异常,锁提前被释放了、比如执行过程中发生较长时间GC,导致锁过期释放,GC结束之后,又来执行业务逻辑等等。
????????总结Redis分布式锁,实现起来比较简单,但可能会在集群模式下出现数据不一致的问题。而且RedLock算法虽然一定程度上保证了安全性,但却损失了性能。注意,只是一定程度上,RedLock没有全部解决安全性。
????????此外,如果应用执行过程中宕机了,锁没有释放,其他应用也拿不到锁,一直执行不了,只能等待锁自己过期。这也是一直被青睐基于ZK实现的分布式锁的人所诟病的一点。
3、Zookeeper分布式锁
????????zookeeper分布式锁的优越性完全得益于其自身机制。
????????相比于Redis,zk分布式锁在获得锁之前不需要不断地重试,只需要监听即可(利用Watch);在持有锁的服务器宕机之后,也不用等到过期后释放锁,zookeeper会自动将其摘除。
其主要使用了ZK的几个功能:
? ? ?1、ZK可以创建临时有序节点;
? ? ?2、节点down之后,可以将临时节点删除;
? ? ?3、watch监听机制
获取锁的基本流程:
1、客户端创建子节点,并编号,******-01,最早得编号为1,以此累加;
2、客户端判断自己是不是最早的那个子节点(有序节点),如果是就获取锁成功;如果不是,就监听上一个节点,比如编号2监听1,编号3监听2等等。
3、执行完业务代码直接释放锁。
? ?(下面的图片非原创,来源于网络)

????????ZK的节点分为持久节点、有序持久节点、临时节点、临时有序节点。实现分布式锁用的是临时有序节点。ZK也经常用于注册中心,将暴露的服务url注册到ZK上。
????????Watch监听是ZK比较重要的一个机制,它可以避免惊群效应。惊群效应这个概念接触过多进程的应该都熟悉,一次可能会唤醒所有进程,但实际上只能有其中一个执行;像Nginx为了避免惊群效应是通过全局互斥锁实现的。
????????Watch的思想就是客户端注册watch事件到ZK,随后当事件发生后,会回调客户端注册的事件,当前一个节点持有锁且释放了(临时节点删除),客户端感知到就会执行获取锁的过程。
????????ZK作为一个完美的分布式协调方案,其可靠性要高于Redis,因为zookeeper不用担心突然宕机的问题,因为当某节点出现问题后,会自动摘除该节点,也就意味着自动释放了锁。
????????不过ZK在性能上也经常被吐槽,都说它不适合于高并发场景。这个观点的依据是ZK的加锁过程是每个客户端都会创建一个临时节点,释放锁的过程也是每个客户端都要删除一个临时节点,这种频繁的增加节点,删除节点的操作都是由ZK集群中的Leader统一完成的,那么当并发量较大时,Leader节点就一定会成为性能瓶颈的。
? ? ? ? Curator(org.apache.curator)客户端实现了分布式锁,它实现了多种类型的锁,包括互斥锁,读写锁,信号量等。可以直接用,关键类:InterProcessMutex,代码比较多,这里就不贴了,感兴趣的可以看一下源代码。
4、基于ETCD实现的分布式锁
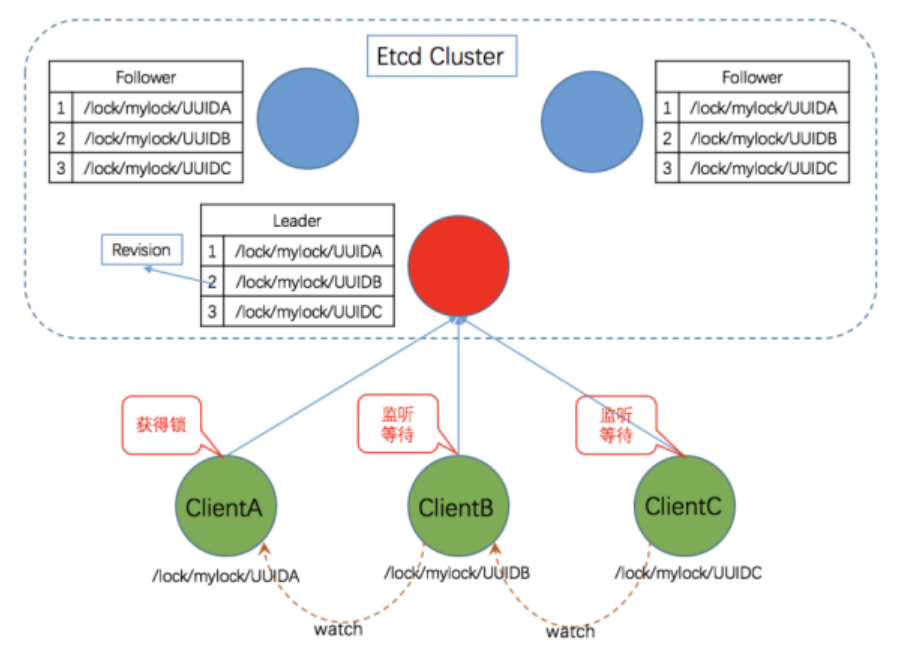
????????ETCD是K8s的衍生品,在K8s中发挥关键的作用,主要用于分享配置和服务发现,是用Go写的,现在也经常用来作为分布式锁。不过显然没有上述几种分布式锁常见,说实话我也是今年才接触的,主要是公司让我写一篇专利,我就选题就订了这个。现在市面上好用的ETCD分布式锁客户端也是用golang写的,Java也有,但我认为并不是特别成熟。而且,现在基本上只支持ETCD的互斥锁,没有读写锁等类似于Redisson客户端实现的复杂方案。因此我写的专利就是提出如何基于ETCD实现分布式读写锁,且支持写锁降级、读锁升级等。专利还在受理中,内容不能公布。只能先贴一个我画的一张图,主要展示了我在创建锁的过程中创建的key:

? ? ? ? ETCD集成了Redis的高性能(采用K-V存储方式),又借鉴了ZK的高可靠性,但不同于ZK通过自研的ZAB实现强一致性,ETCD通过raft协议来实现一致性,且采用基于HTTP2的grpc实现通信,因此性能要比ZK更好。
? ? ? ? 和ZK一样,ETCD也有Watch机制,不同的是,其还存在Prefix,Lease以及Revision机制。
- Watch机制:一种监听机制,通过该机制可以对系统内的某个key或者节点进行监听,当监听对象发生变化时,系统会主动给listener发送节点变更事件通知,该机制减少了轮询导致的资源消耗,避免惊群效应。常用于Redis的事务监听、ZK的节点监听、ETCD的key监听。
- Prefix机制:ETCD提供的一种前缀匹配机制,可通过前缀寻找到当前已存在的所有key列表。
- Revision机制:对于ETCD的每一个key,ETCD都会维护一个全局的Revision列表,每新增一个事务,revision自动加1。
- Lease 机制:支持有效期,且可以续期。
总结上面提到的几种分布式锁,现在做一下对比。
从性能上来看,Redis>ETCD>ZK>Mysql,Redis做为一个NoSQL中间件,性能不可比拟,Mysql最差。
从可靠性来看:ETCD>ZK>Redis>Mysql
从实现难易来看:ZK>ETCD>Redis>Mysql。
说句实话,目前我用的比较多的还是Redis。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- js获取对象数组中重复项的个数并排序,js数组对象筛选出重复数据 并计算 重复了几次
- 可转债系列文章1——可转债基础知识
- 递归和尾递归(用C语言解斐波那契和阶乘问题)
- 【OD统一考试( C&D 卷)】推荐多样性 200 分 ,JAVA 解答
- STC8_USBCDC模拟串口收发数据
- 学累了怎么休息???
- 【现代密码学】笔记2 -- 完善保密性《introduction to modern cryphtography》现代密码学原理与协议
- 代码随想录算法训练DAY27|回溯3
- 电源模块常见温升测试方法分享 -纳米软件
- (已解决)踩坑spring-session-data-redis包出现sessionId不一致问题