环形链表[简单]
优质博文:IT-BLOG-CN
一、题目
给你一个链表的头节点head,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪next指针再次到达,则链表中存在环。为了表示给定链表中的环,评测系统内部使用整数pos来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回true否则,返回false
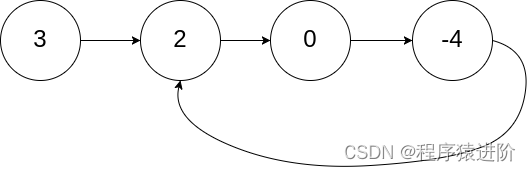
快慢指针
可以使用快慢指针法, 分别定义fast和slow指针,从头结点出发,fast指针每次移动两个节点,slow指针每次移动一个节点, 如果 fast和slow指针在途中相遇,说明这个链表有环。
为什么fast走两个节点,slow走一个节点,有环的话,一定会在环内相遇呢,而不是永远的错开呢?
首先第一点:fast指针一定先进入环中,如果fast指针和slow指针相遇的话,一定是在环中相遇,这是毋庸置疑的。
那么来看一下,为什么fast指针和slow指针一定会相遇呢?
可以画一个环,然后让fast指针在任意一个节点开始追赶slow指针。
这是因为fast是走两步,slow是走一步,其实相对于slow来说,fast是一个节点一个节点的靠近slow的,所以fast一定可以和slow重合。
/**
* Definition for singly-linked list.
* class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public boolean hasCycle(ListNode head) {
ListNode fast = head;
ListNode slow = head;
// 空链表、单节点链表一定不会有环
while (fast != null && fast.next != null) {
fast = fast.next.next; // 快指针,一次移动两步
slow = slow.next; // 慢指针,一次移动一步
// 不要比较value,对象可能是个空的
if (fast == slow) { // 快慢指针相遇,表明有环
return true;
}
}
return false; // 正常走到链表末尾,表明没有环
}
}
时间复杂度: O(N),其中N是链表中的节点数。当链表中不存在环时,快指针将先于慢指针到达链表尾部,链表中每个节点至多被访问两次。当链表中存在环时,每一轮移动后,快慢指针的距离将减小一。而初始距离为环的长度,因此至多移动 NNN 轮。
空间复杂度: O(1)。我们只使用了两个指针的额外空间。
三、哈希表
最容易想到的方法是遍历所有节点,每次遍历到一个节点时,判断该节点此前是否被访问过。
具体地,我们可以使用哈希表来存储所有已经访问过的节点。每次我们到达一个节点,如果该节点已经存在于哈希表中,则说明该链表是环形链表,否则就将该节点加入哈希表中。重复这一过程,直到我们遍历完整个链表即可。
public class Solution {
public boolean hasCycle(ListNode head) {
Set<ListNode> seen = new HashSet<ListNode>();
while (head != null) {
if (!seen.add(head)) {
return true;
}
head = head.next;
}
return false;
}
}
时间复杂度: O(N),其中N是链表中的节点数。最坏情况下我们需要遍历每个节点一次。
空间复杂度: O(N),其中N是链表中的节点数。主要为哈希表的开销,最坏情况下我们需要将每个节点插入到哈希表中一次。
四、数组与链表
作为线性表的两种存储方式 —— 链表和数组,这对相爱相杀的好基友有着各自的优缺点。接下来,我们梳理一下这两种方式。
数组,所有元素都连续的存储于一段内存中,且每个元素占用的内存大小相同。这使得数组具备了通过下标快速访问数据的能力。
但连续存储的缺点也很明显,增加容量,增删元素的成本很高,时间复杂度均为O(n)。
增加数组容量需要先申请一块新的内存,然后复制原有的元素。如果需要的话,可能还要删除原先的内存。
删除元素时需要移动被删除元素之后的所有元素以保证所有元素是连续的。增加元素时需要移动指定位置及之后的所有元素,然后将新增元素插入到指定位置,如果容量不足的话还需要先进行扩容操作。
总结一下数组的优缺点:
优点: 可以根据偏移实现快速的随机读写。
缺点: 扩容,增删元素极慢。
链表,由若干个结点组成,每个结点包含数据域和指针域。结点结构如下图所示:
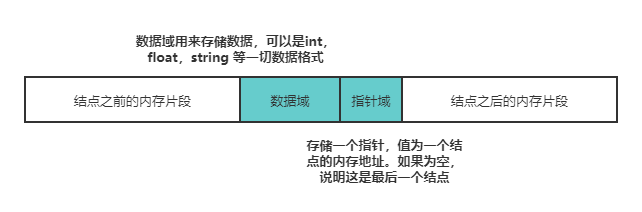
链表的一个结点一般来讲,链表中只会有一个结点的指针域为空,该结点为尾结点,其他结点的指针域都会存储一个结点的内存地址。链表中也只会有一个结点的内存地址没有存储在其他结点的指针域,该结点称为头结点。
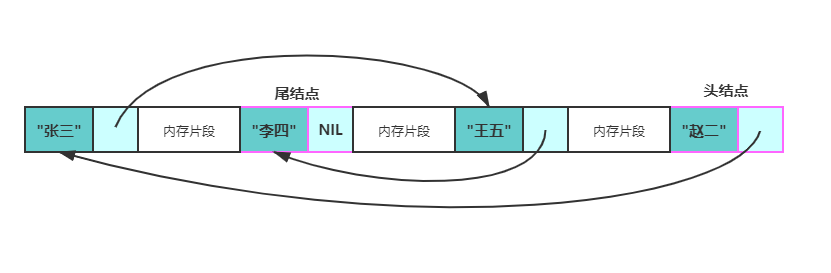
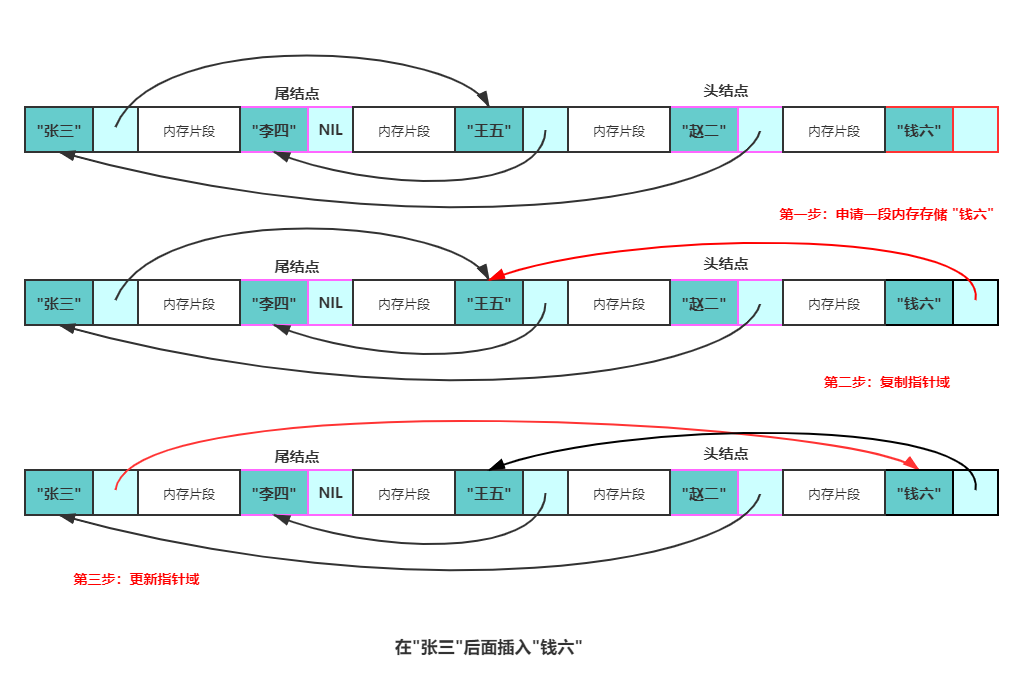
内存中的链表链表的存储方式使得它可以高效的在指定位置插入与删除,时间复杂度均为O(1)。
在结点p之后增加一个结点q总共分三步:
1、请一段内存用以存储q (可以使用内存池避免频繁申请和销毁内存)。
2、将p的指针域数据复制到q的指针域。
3、更新p的指针域为q的地址。
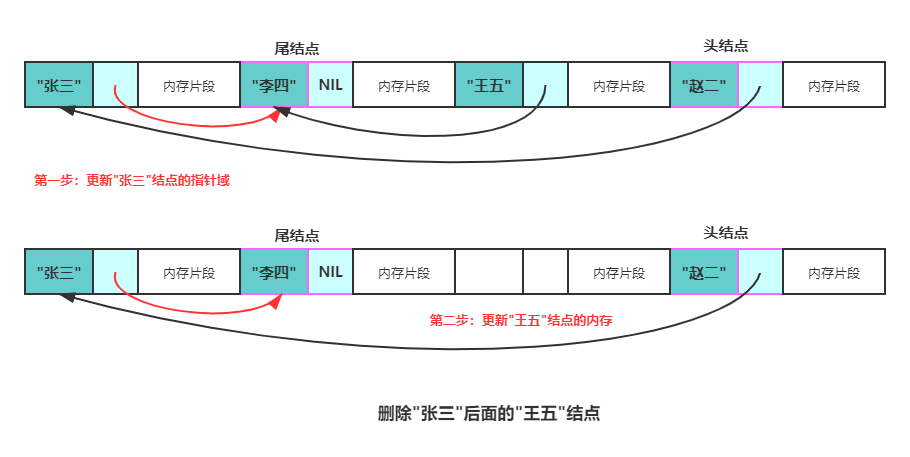
删除结点p之后的结点q总共分两步:
1、将q的指针域复制到p的指针域。
2、释放q结点的内存。
#include <bits/stdc++.h>
using namespace std;
//定义一个结点模板
template<typename T>
struct Node {
T data;
Node *next;
Node() : next(nullptr) {}
Node(const T &d) : data(d), next(nullptr) {}
};
//删除 p 结点后面的元素
template<typename T>
void Remove(Node<T> *p) {
if (p == nullptr || p->next == nullptr) {
return;
}
auto tmp = p->next->next;
delete p->next;
p->next = tmp;
}
//在 p 结点后面插入元素
template<typename T>
void Insert(Node<T> *p, const T &data) {
auto tmp = new Node<T>(data);
tmp->next = p->next;
p->next = tmp;
}
//遍历链表
template<typename T, typename V>
void Walk(Node<T> *p, const V &vistor) {
while(p != nullptr) {
vistor(p);
p = p->next;
}
}
int main() {
auto p = new Node<int>(1);
Insert(p, 2);
int sum = 0;
Walk(p, [&sum](const Node<int> *p) -> void { sum += p->data; });
cout << sum << endl;
Remove(p);
sum = 0;
Walk(p, [&sum](const Node<int> *p) -> void { sum += p->data; });
cout << sum << endl;
return 0;
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!