【深度学习-目标检测】04 - SSD 论文学习与总结
发布时间:2023年12月26日
论文地址:SSD: Single Shot MultiBox Detector
论文学习
1. 摘要
-
单一深度神经网络用于对象检测:SSD方法使用一个单一的深度神经网络来直接检测图像中的对象,这与传统的需要先生成 对象提议(区域提议)再进行分类的方法不同。(传统的目标检测网络是”Two Stage“算法,SSD 是”One Stage“算法)
-
离散化的输出空间:SSD通过将边界框(Bounding Boxes)的输出空间离散化为一组宽高比和尺度的默认框,来实现对对象的检测。
离散化的输出空间理解:
- ”连续化“的输出空间:对于传统的目标检测算法,生成的候选框其实是不确定的,是以选择性搜索(Selective Search)方法或者RPN网络计算得出的,这些候选框可能生成任何位置,任何大小,任何尺寸(有无限种可能),因此基于这些框的预测输出也就是”连续化“的输出空间。
- ”离散化“的输出空间:对于SSD算法,生成的候选框是确定的,是预先定义好的,在图像的什么位置、什么大小、什么尺寸,这些都是以及定义好的,不需要使用候选框生成算法来生成(有限种可能),因此基于这些框的预测输出也就是”离散化“的输出空间。
- 预测时的处理:在预测时,网络会为每个默认框生成对象类别的分数,并且调整框的位置和大小以更好地匹配对象地形状。(分类+框调整)
- 多尺度特征图地结合:SSD结合了来自网络不同层地多尺度特征图的预测,这使得它能够自然地处理不同大小地对象。(以上一个特征图为基础生成下一个特征图,且在每个特征图上都会进行目标检测的预测,因为不同尺寸的特征图适用于不同尺寸目标的检测)
- 简化地方法:与需要对象提议(区域提议)的方法相比,SSD简化了流程,因为它完全消除了提议生成和后续的像素或者特征重采样阶段,所有计算都在一个网络中完成。(省略了生成区域提议的算法过程)
- 训练和继承的便利性:SSD易于训练,并且可以直接集成到需要对象检测的系统中。
- 性能和实验结果:在PASCAL VOC、COCO等数据集上的结果显示,SSD在准确性上与使用额外对象提议(区域提议)的网络方法相当,但是速度会更快。(准确性相当,速度加快)
2. 引言
- 当前对象检测系统的方法:
- 当前最先进的对象检测系统主要基于以下流程:首先假设(或生成)一系列边界框(bounding boxes),然后对每个框重新采样像素或特征,并应用高质量的分类器。
- 这种方法自选择性搜索(Selective Search)工作以来,在对象检测基准测试中一直占据主导地位。最新的成果,如基于Faster R-CNN的PASCAL VOC、COCO和ILSVRC检测,都采用了这种方法,但使用了更深层次的特征。
- 挑战:
- 尽管这些方法在准确性方面表现出色,但它们对计算资源的需求很高,对于嵌入式系统来说过于复杂,甚至在高端硬件上也难以实现实时应用。
- SSD的优势:
- 与需要生成对象提议的方法相比,SSD方法简单得多。它完全消除了提议生成和后续的像素或特征重采样阶段,将所有计算封装在单个网络中。
- 这使得SSD易于训练,并且可以直接集成到需要对象检测组件的系统中。
- 性能:
- 实验结果表明,SSD在PASCAL VOC、COCO和ILSVRC数据集上与使用额外对象提议步骤的方法在准确性上具有竞争力,同时速度更快。
- 对于300×300的输入,SSD在VOC2007测试集上达到了74.3%的平均精度(mAP),在Nvidia Titan X上的速度为每秒59帧;对于512×512的输入,SSD的mAP达到了76.9%,超过了类似的最先进的Faster R-CNN模型。
- 与其他单阶段方法相比,即使在较小的输入图像尺寸下,SSD也展现出更好的准确性。
3. SSD 方法
-
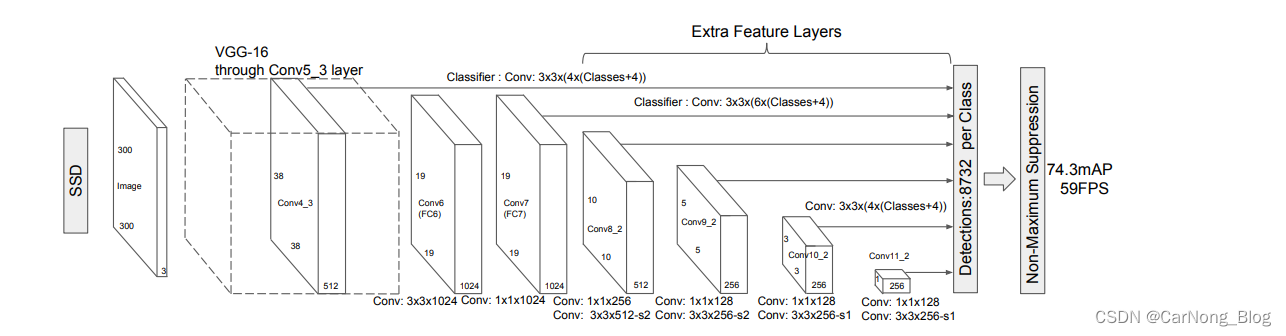
SSD模型
- 基于前馈卷积网络:SSD是一个基于前馈卷积网络的框架,它生成一组固定大小的边界框和这些框中对象类别实例的分数,然后通过非极大值抑制(non-maximum suppression)步骤产生最终的检测结果。
- 基础网络:早期网络层基于用于高质量图像分类的标准架构(如VGG-16),在分类层之前截断。
- 辅助结构:在基础网络的末端添加了卷积特征层,这些层的尺寸逐渐减小,允许在多个尺度上进行检测预测。
-
多尺度特征图和卷积预测器
- 多尺度特征图:通过在截断的基础网络末端添加卷积特征层,实现在不同尺度上的检测。
- 卷积预测器:每个添加的特征层(或基础网络中的现有特征层)可以使用一组卷积滤波器产生一组固定的检测预测。
-
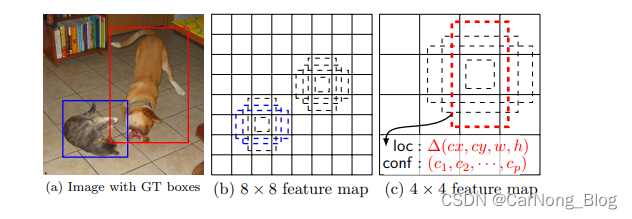
默认框和宽高比
- 默认框和宽高比:在网络顶部的多个特征图的每个单元格上关联一组默认边界框。这些默认框以卷积方式覆盖特征图,每个框的位置相对于其对应单元格是固定的。
- 预测:在每个特征图单元格上,预测相对于单元格中默认框形状的偏移量,以及表明每个框中类实例存在的每类分数。
-
训练
- 训练与典型检测器的区别:训练SSD与使用区域提议的典型检测器训练不同,需要将地面真实信息分配给检测器输出的固定集合。
- 损失函数和反向传播:一旦确定了这种分配,就应用损失函数和端到端的反向传播。
- 训练涉及的选择:训练还涉及选择用于检测的默认框和尺度,以及硬负采样(hard negative mining)和数据增强策略。
4. 实验结果
- 基础网络
- 实验基于VGG16网络,预训练在ILSVRC CLS-LOC数据集上。
- 对VGG16进行了修改,包括将fc6和fc7转换为卷积层,改变pool5层的结构,并使用atrous算法填充“空洞”。
- 训练使用SGD,初始学习率为10^-3,动量为0.9,权重衰减为0.0005,批量大小为32。
- PASCAL VOC2007
- 在VOC2007测试集(4952张图片)上,与Fast R-CNN和Faster R-CNN进行比较。
- SSD300模型使用conv4_3、conv7 (fc7)、conv8_2、conv9_2、conv10_2和conv11_2进行位置和置信度预测。
- SSD300在VOC2007 trainval上的表现已经超过Fast R-CNN,SSD512在更大的输入图像尺寸下表现更好,超过Faster R-CNN。
- 模型分析
- 通过控制实验来理解SSD的每个组件对性能的影响。
- 使用多种设计选择和组件,如数据增强、不同的默认框形状和尺寸,以及使用atrous算法。
- PASCAL VOC2012
- 使用与VOC2007相同的设置,但在更大的数据集上进行训练和测试。
- SSD300和SSD512在VOC2012测试集上的表现与VOC2007测试集上观察到的性能趋势一致。
- COCO
- 在COCO数据集上训练SSD300和SSD512架构。
- 由于COCO中的对象倾向于更小,因此使用更小的默认框。
- SSD300在COCO test-dev2015上的表现优于Fast R-CNN,SSD512在更大的图像尺寸下表现更好。
- ILSVRC结果
- 将相同的网络架构应用于ILSVRC DET数据集。
- SSD300在ILSVRC2014 DET train和val1上的训练结果达到了43.4 mAP。
- 推理时间
- 考虑到方法生成的大量框,高效执行非极大值抑制(NMS)是必要的。
- SSD300和SSD512在速度和准确性方面均优于Faster R-CNN和YOLO。
8. 针对小对象准确性的数据增强
- 数据增强的重要性:
- SSD方法在没有后续特征重采样步骤的情况下,对小对象的分类任务相对较难。
- 作者提出的数据增强策略显著提高了性能,尤其是在像PASCAL VOC这样的小数据集上。
- 随机裁剪策略:
- 数据增强策略中包括随机裁剪,这可以被视为一种“放大”操作,生成更多较大的训练样本。
- “缩小”操作:
- 为了实现“缩小”操作,即创建更多小训练样本,作者首先在填充有均值的画布上随机放置图像,画布大小为原始图像大小的16倍。
- 然后在进行任何随机裁剪操作之前进行处理。
- 训练迭代次数的调整:
- 由于引入了新的“扩展”数据增强技巧,导致训练图像数量增加,因此需要加倍训练迭代次数。
- 性能提升:
- 使用这种新的数据增强方法,作者在多个数据集上观察到了2%-3%的mAP(平均精度)一致提升。
- 未来工作:
- 作者提出,改进SSD的另一种方法是设计更好的默认框平铺,使其位置和尺度更好地与特征图上每个位置的感受野对齐。
- 这一点留待未来工作进一步探索。
10. 相关工作
- 对象检测方法的两大类:
- 基于滑动窗口:这类方法在图像中滑动一个窗口,对每个窗口位置进行对象检测。
- 基于区域提议分类:这类方法首先生成对象的候选区域(区域提议),然后对这些区域进行分类。
- 卷积神经网络(CNN)之前:
- 在CNN广泛应用之前,滑动窗口方法(如可变形部件模型,DPM)和基于选择性搜索的方法性能相当。
- R-CNN的出现:
- R-CNN结合了选择性搜索区域提议和基于卷积网络的后分类,显著提高了检测精度,使得基于区域提议的对象检测方法变得流行。
- R-CNN的改进:
- SPPnet加速了R-CNN,引入了空间金字塔池化层,使分类层能够重用在多个图像分辨率上生成的特征图。
- Fast R-CNN扩展了SPPnet,可以端到端微调所有层,同时最小化置信度和边界框回归的损失。
- 提议生成的改进:
- 最新的工作,如MultiBox,用深度神经网络直接生成区域提议,替代了基于低级图像特征的选择性搜索提议。
- Faster R-CNN用区域提议网络(RPN)替代选择性搜索提议,并提出了一种方法将RPN与Fast R-CNN集成。
- 直接预测方法:
- OverFeat和YOLO等方法跳过提议步骤,直接预测多个类别的边界框和置信度。
- SSD方法也属于这一类,但使用了不同尺度和宽高比的默认框,使其比现有方法更灵活
11. 结论
- SSD模型介绍:
- 论文介绍了SSD,这是一种快速的单次射击多类别对象检测器。
- SSD的关键特性是在网络顶部的多个特征图上使用多尺度卷积边界框输出。
- 模型特点:
- 这种表示允许高效地建模可能的框形状空间。
- SSD模型至少比现有方法(如YOLO、MultiBox)在位置、尺度和宽高比方面有更多数量级的框预测。
- 性能比较:
- SSD在保持相同VGG-16基础架构的情况下,与最先进的对象检测器在精度和速度方面相比有优势。
- SSD512模型在PASCAL VOC和COCO数据集上的精度显著优于Faster R-CNN,同时速度更快。
实时性能: - 实时SSD300模型以每秒59帧的速度运行,比当前实时的YOLO模型更快,同时提供显著更高的检测精度。
- 模型的应用潜力:
- SSD模型作为一个单一且相对简单的模块,为包含对象检测组件的更大系统提供了有用的构建块。
- 一个有前景的未来方向是探索将其作为使用循环神经网络同时检测和跟踪视频中对象的系统的一部分。
这篇论文《SSD: Single Shot MultiBox Detector》的主要创新点和贡献可以总结如下:
- 单次检测(Single Shot)方法:
- SSD是一种单次检测方法,它在单个网络传递中直接预测对象的边界框和类别,与需要两步处理(先生成区域提议,再分类)的方法不同。
- 多尺度特征图用于检测:
- SSD利用多个尺度的特征图来进行对象检测,这允许网络在不同分辨率的图像区域上有效地检测不同大小的对象。
- 默认框(Default Boxes)机制:
- SSD引入了默认框的概念,这些框在多个特征图的每个位置都有预定义的不同尺寸和宽高比。这种方法简化了候选区域的生成过程,并提高了检测的效率和准确性。
- 端到端的训练:
- SSD可以端到端地训练,不需要复杂的多阶段训练过程或单独的区域提议网络,这使得训练过程更加简洁和高效。
- 实时检测性能:
- SSD在保持高检测精度的同时实现了实时的处理速度,这对于需要快速响应的应用场景(如自动驾驶车辆和视频监控)非常重要。
- 在多个标准数据集上的优异表现:
- SSD在多个标准数据集(如PASCAL VOC和COCO)上展示了优异的性能,与当时的最先进方法(如Faster R-CNN)相比,在准确性和速度上都有显著提升。
SSD
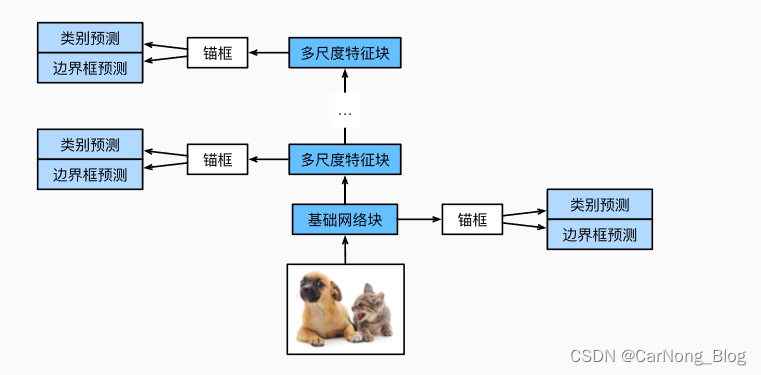
- 输入图像:
- 接收图像:SSD接收一张输入图像,准备进行对象检测。
- 特征提取:
- 基础卷积网络:使用一个预训练的基础网络(如VGG-16)对输入图像进行特征提取。这些网络通常在大型图像数据集上进行预训练。
- 截断和修改:基础网络可能会被修改或截断,以适应对象检测任务。
- 添加额外的卷积层:
- 多尺度特征图:在基础网络的顶部添加额外的卷积层,用于在不同尺度上捕捉特征,以便检测不同大小的对象。(底层特征图用于拟合小物体,顶部特征图用于拟合大物体)
- 默认框和预测:
- 定义默认框:在每个特征图的单元格上定义一组默认框,这些框具有不同的尺寸和宽高比。
- 类别和位置预测:对于每个默认框,网络预测对象类别的分数和边界框的位置偏移量。
- 非极大值抑制(NMS):
- 选择最佳检测:应用NMS来选择最佳检测结果,过滤掉重叠度高的低分边界框。
- 输出检测结果:
- 最终检测:输出最终的检测结果,包括边界框的位置、对象的类别和置信度分数。
- 训练过程:
- 损失函数:使用损失函数来训练模型,该函数同时考虑类别预测的准确性和边界框位置的精确性。
- 数据增强:采用数据增强技术来提高模型的泛化能力,尤其是对小对象的检测能力。
以上内容旨在记录自己的学习过程以及复习,如有错误,欢迎批评指正,谢谢阅读。
文章来源:https://blog.csdn.net/qq_43513394/article/details/135206203
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!