基于 LightGBM 的系统访问风险识别
基于 LightGBM 的系统访问风险识别
文章目录
一、课题来源
分类预测/回归预测相关内容,从阿里天池或datafountain下载作业数据datafountain:系统访问风险识别
二、任务描述
系统访问风险识别
(1)本赛题中,参赛团队将基于用户历史的系统访问日志及是否存在风险标记等数据,结合行业知识,构建必要的特征工程,建立机器学习、人工智能或数据挖掘模型,并用该模型预测将来的系统访问是否存在风险。
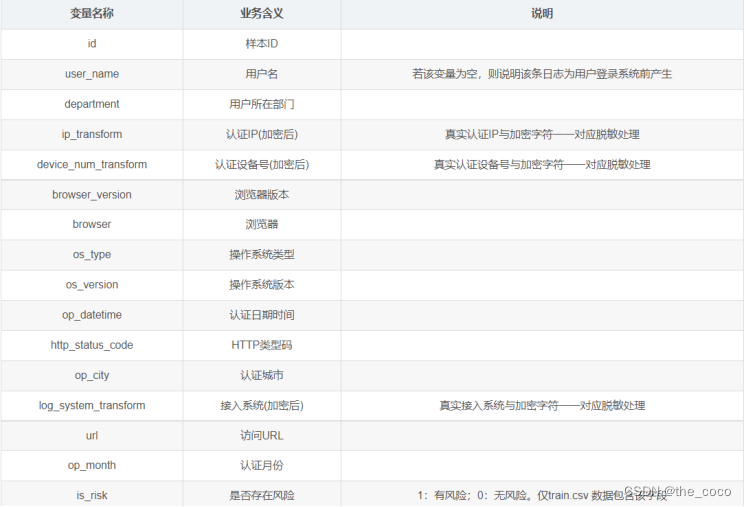
(2)本赛题数据是从竹云日志库中抽取某公司一定比例的员工从2022年1月到6月的系统访问日志数据,主要涉及认证日志与风险日志数据。部分字段经过一一对应脱敏处理,供参赛队伍使用。其中认证日志是用户在访问应用系统时产生的行为数据,包括用户名、认证时间、认证城市、接入系统、访问URL等关键信息。
三、课题背景
随着国家、企业对安全和效率越来越重视,作为安全基础设施之一——统一身份管理(IAM,Identity and Access Management)系统也得到越来越多的关注。 在IAM领域中,其主要安全防护手段是身份鉴别,身份鉴别主要包括账密验证、扫码验证、短信验证、人脸识别及指纹验证等方式。这些身份鉴别方式一般可分为三类,即用户所知(如口令)、所有(如身份证)、特征(如人脸识别及指纹验证)。这些鉴别方式都有其各自的缺点——比如口令,强度高了不容易记住,强度低了又容易丢;又比如人脸识别,做活体验证用户体验不好,静默检测又容易被照片、视频、人脸模型绕过。也因此,在等保2.0中对于三级以上系统要求必须使用两种及以上的鉴别方式对用户进行身份鉴别,以提高身份鉴别的可信度,这种鉴别方式也被称为双因素认证。
对用户来说,双因素认证在一定程度上提高了安全性,但也极大地降低了用户体验。也因此,IAM厂商开始参考用户实体行为分析(UEBA,User and Entity Behavior Analytics)、用户画像等行为分析技术,来探索一种既能确保用户体验,又能提高身份鉴别可信度的方法。而在当前IAM的探索过程中,目前最容易落地的方法是基于规则的行为分析技术,因为它可理解性较高,且容易与其它身份鉴别方式进行联动。
但基于规则的行为分析技术局限性也很明显,首先这种技术是基于经验的,有“宁错杀一千,不放过一个”的特点,其次它也缺少从数据层面来证明是否有人正在尝试窃取或验证非法获取的身份信息,又或者正在使用窃取的身份信息。鉴于此,我们举办这次竞赛,希望各个参赛团队利用竞赛数据和行业知识,建立机器学习、人工智能或数据挖掘模型,来弥补传统方法的缺点,从而解决这一行业难题。
四、数据获取分析及说明
本赛题数据是从竹云日志库中抽取某公司一定比例的员工从2022年1月到6月的系统访问日志数据,主要涉及认证日志与风险日志数据。部分字段经过一一对应脱敏处理,供参赛队伍使用。其中认证日志是用户在访问应用系统时产生的行为数据,包括用户名、认证时间、认证城市、接入系统、访问URL等关键信息。
(1)登录https://www.datafountain.cn并获取相关数据
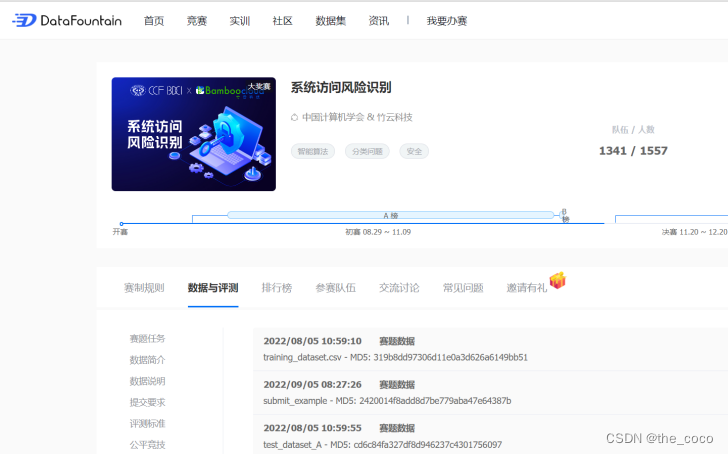
(2)数据集文件说明

(3)训练集和测试集含义说明
五、实验过程详细描述及程序清单
(1)数据处理
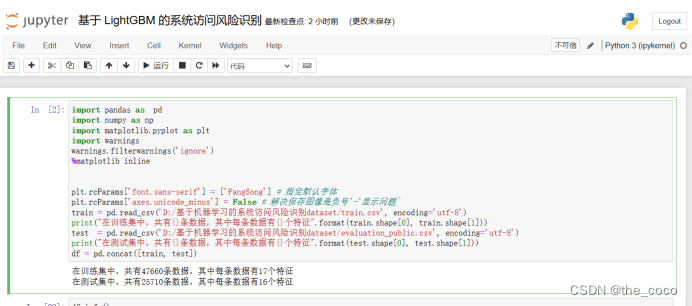
读取数据
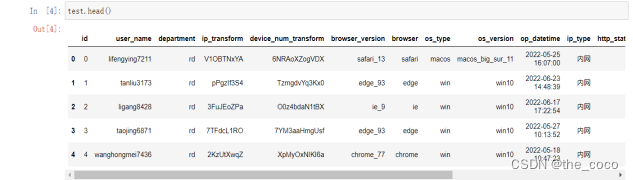
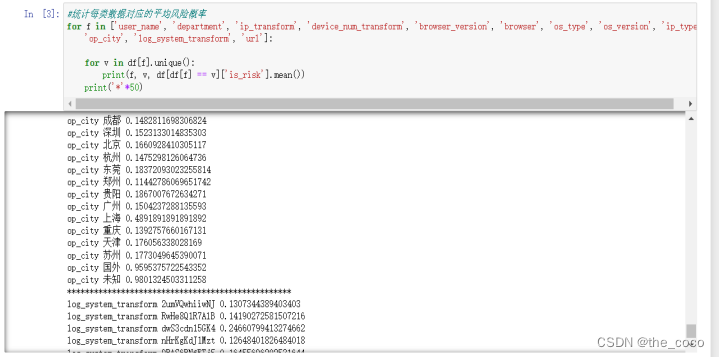
统计每类数据的平均风险概率
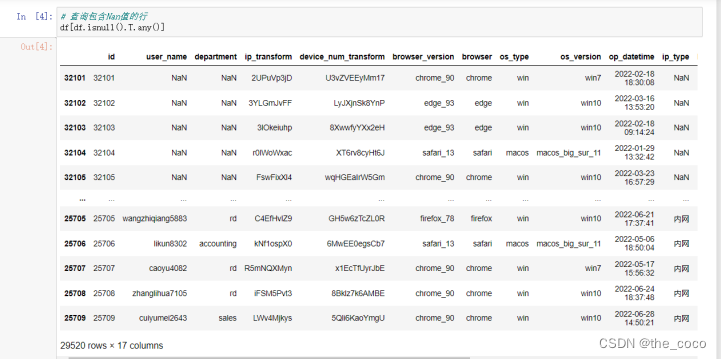
查询包含Nan值的行
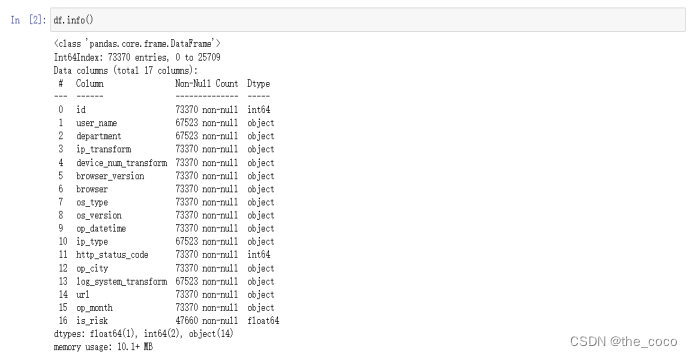
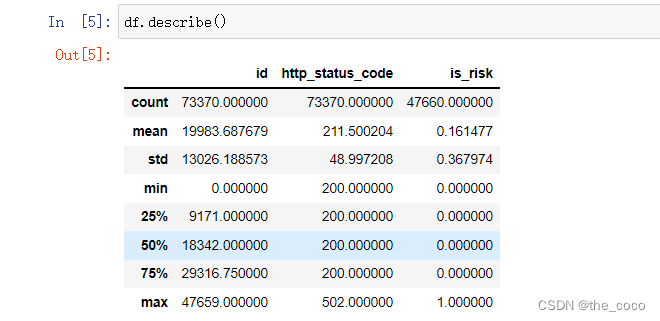
查看数据描述
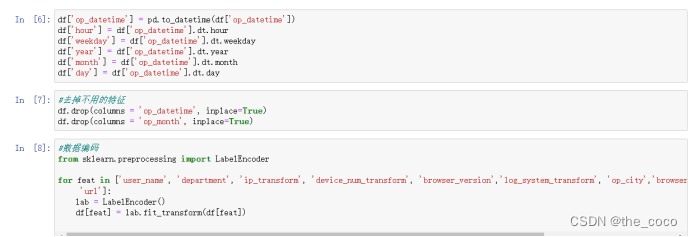
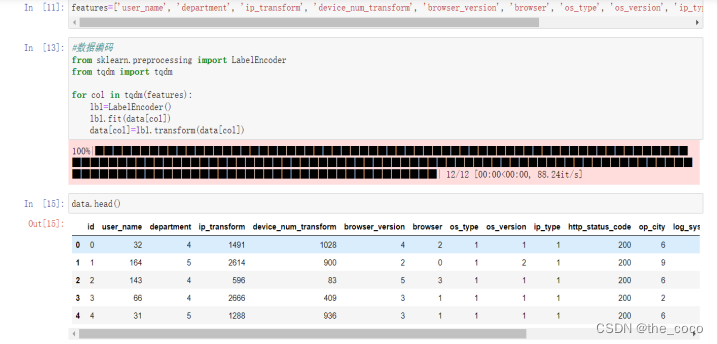
进行一定的数据处理以及数据初始化,调用Sklearn库中的特征预处理API sklearn.preprocessing 进行特征预处理使用labelEncoder函数将离散型的数据转换成 0 到 n ? 1 之间的数,这里 n 是一个列表的不同取值的个数,可以认为是某个特征的所有不同取值的个数。
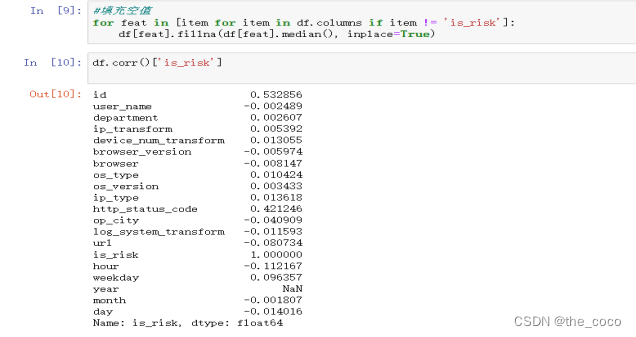
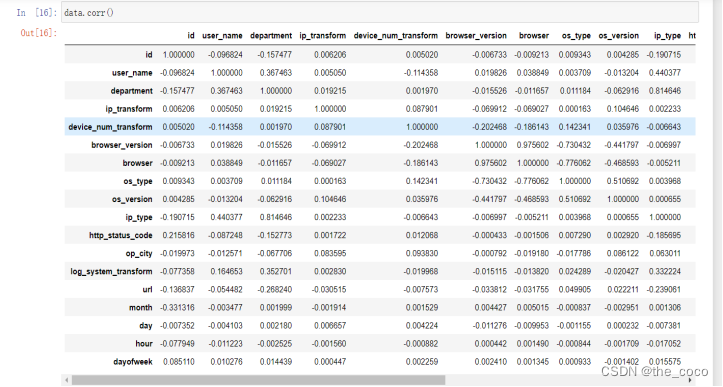
填充空值并使用Corr函数,使用相关系数来衡量两个数据集合是否在一条线上面,即针对线性数据的相关系数计算,针对非线性数据便会有误差。默认空参情况下传入值为Pearson
继续处理数据并将后续数据归一化,通过对原始数据进行变换把数据映射到(0,1)之间
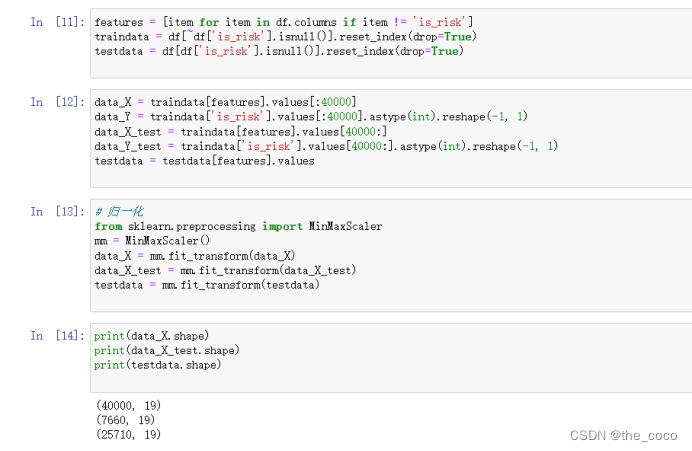
(2)特征抽取
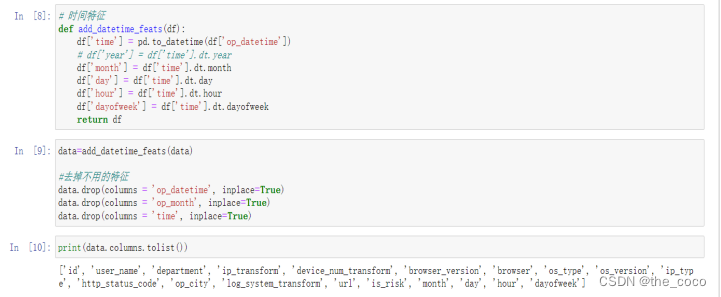
1.时间特征提取
2.离散数据处理
3.数据集分割

(3)模型训练
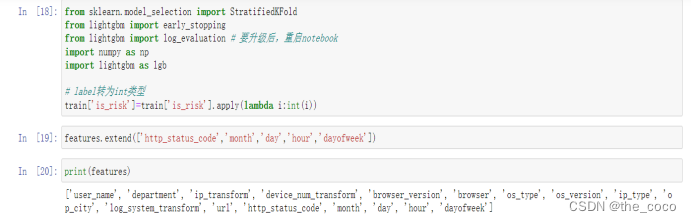
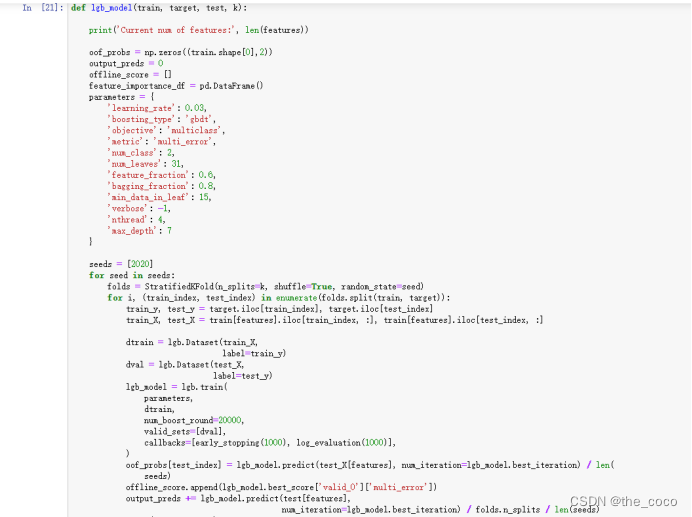
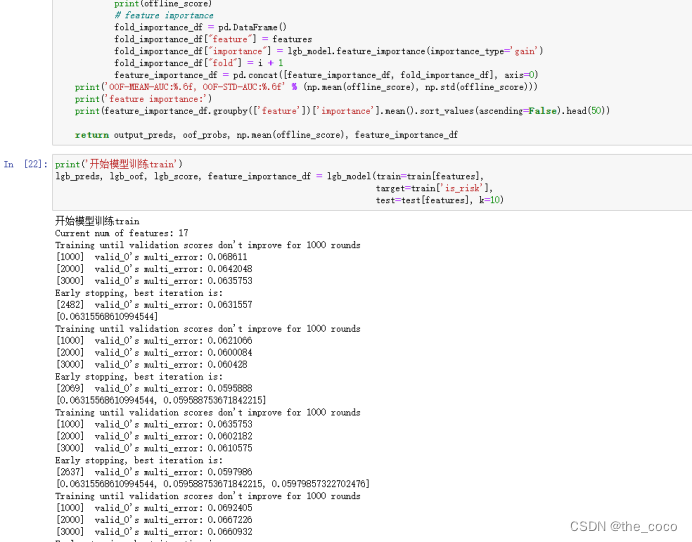
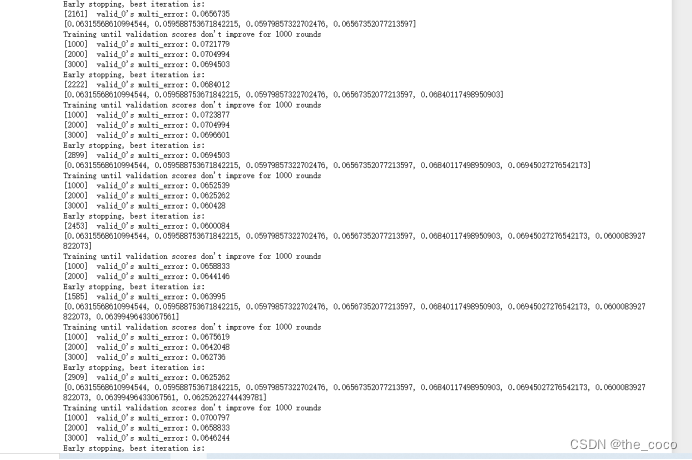
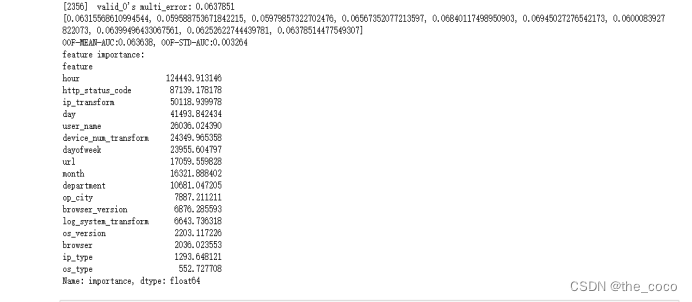
(4)预测
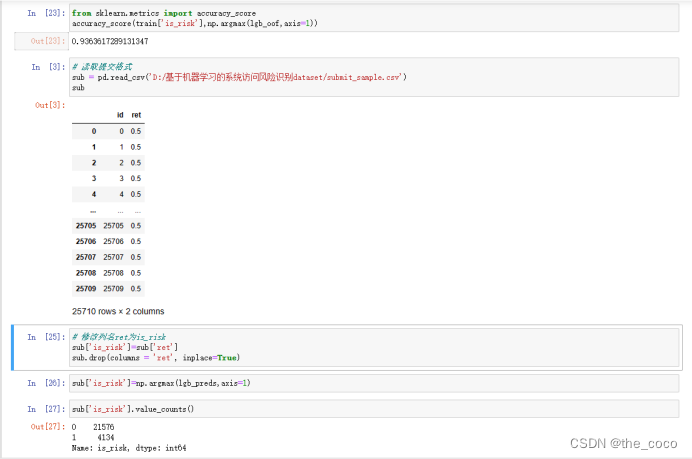
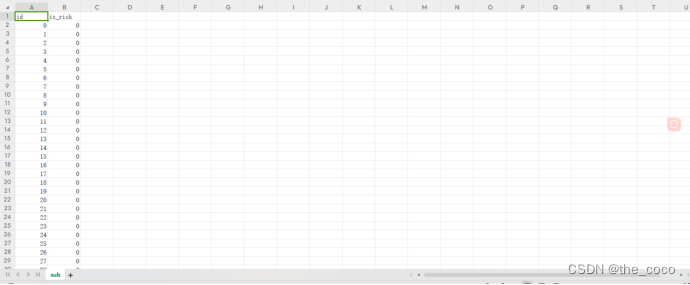
保存至相应csv文件

1表示有风险,0表示没有风险
六、个人总结
这次大作业让我对数据挖掘和分析这门课程有了更深一步的了解,学习利用机器学习算法中的LightGBM算法对离散数据进行分析,同时也对Python代码有了更深层次的认识,认识了机器学习算法的优势,通过这次大作业的学习学会了建模分析方法,同时也学会了如何用Python代码实现对数据的删除和清洗,对模型本身的算法、适用范围、参数、优劣性有充分的了解。同时掌握了离散型数据的特征处理和时间处理,表格数据也可以轻易解决了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!