nodejs使用nodejieba
Nodejieba是一个基于Node.js平台的中文分词模块,用于将中文文本切分成有意义的词汇。它是结巴中文分词的Node.js版本,结巴分词是一种开源的中文分词工具,广泛应用于中文自然语言处理领域
优点
高性能: Nodejieba的底层实现采用了C++,通过Node.js的插件机制与JavaScript集成,因此具有较高的性能。这使得Nodejieba在处理大规模文本数据时表现出色。
支持多种分词模式: Nodejieba支持多种分词模式,包括精确模式、搜索引擎模式和新词识别模式。这使得它适用于不同的应用场景,可以根据需求选择合适的分词模式。
用户自定义词典: 用户可以通过自定义词典来增加或修改分词器的词汇,以适应特定领域或特定项目的需求。这种灵活性使Nodejieba更适用于定制化的分词任务。
支持关键词提取: Nodejieba提供了关键词提取的功能,可以帮助用户快速了解文本的主题和重要信息,是文本摘要、主题分析等任务的有力工具。
支持词性标注: 除了分词功能外,Nodejieba还支持对词汇进行词性标注,为进一步的语义分析提供了基础。
广泛应用: 作为结巴中文分词的Node.js版本,Nodejieba在中文自然语言处理领域得到了广泛的应用,成为许多项目和应用中的首选分词工具。
开源: Nodejieba是开源项目,用户可以根据需要自由使用、修改和分发,同时也可以参与到项目的开发和改进中。
安装
- 官网地址??GitHub - yanyiwu/nodejieba: "结巴"中文分词的Node.js版本
- 下载命令? ?下载会很慢,建议使用淘宝镜像
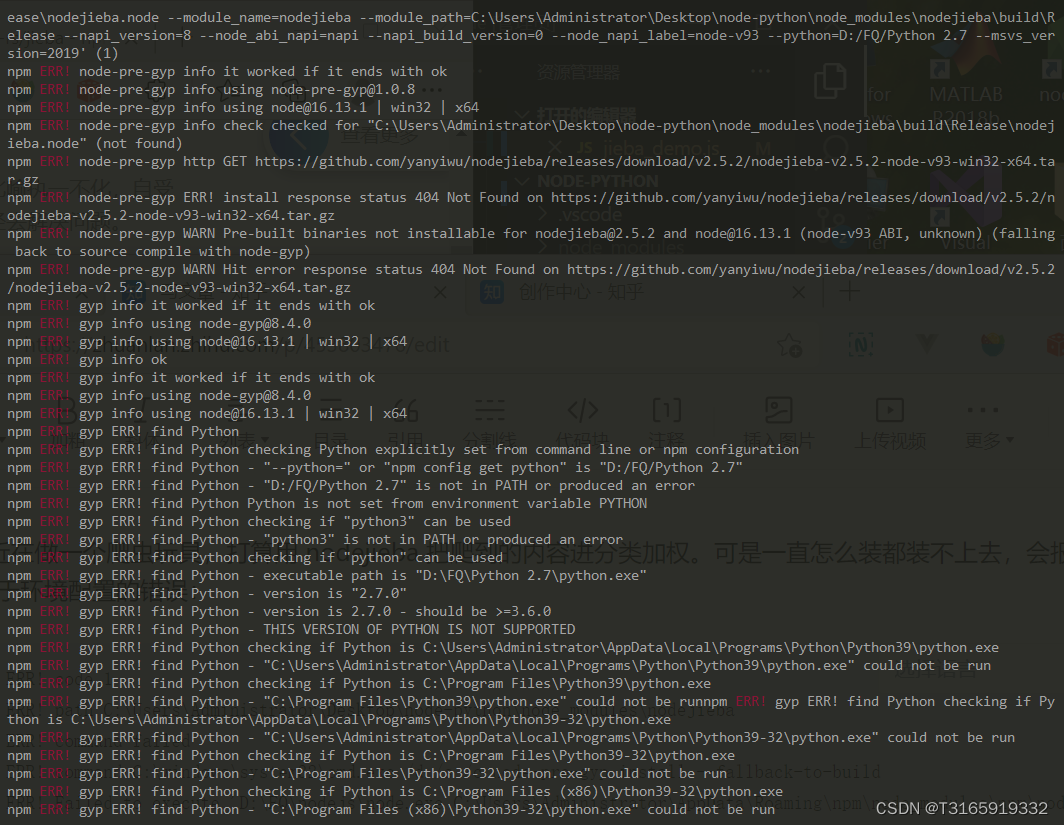
npm install nodejieba- 注意 我这里安装后会抛错 ,由于没有记录,借用一下别人的图,如下:
解决方法:我是按照这个博主的方法在本地编译,编译完成后大概如下图所示
https://www.bilibili.com/video/BV1HH4y1z7Sg?p=1&vd_source=387b3bf6f7293c29f1cf7f181535349d
在vscode里面下载本地文件即可
注意:这个路径为你自己编译后的nodejieba文件路径npm install C:/path/to/nodejieba- 最后,检查是否安装成功
完成安装后,package.json文件中会添加 Nodejieba 作为项目的依赖项,而package-lock.json文件会记录确切的版本和路径信息。
示例package.json?:"dependencies": { "nodejieba": "file:C:/path/to/nodejieba", // 其他依赖项... }示例
package-lock.json:
?"nodejieba": { "version": "file:C:/path/to/nodejieba", "resolved": "C:\\path\\to\\nodejieba", // 其他信息... }, // 其他依赖项...
使用nodejieba
- 引入 Nodejieba 模块: 在你的 Node.js 代码中,引入 Nodejieba 模块:
const nodejieba = require('nodejieba');- 初始化分词器: 在开始分词之前,需要初始化分词器。你可以使用
nodejieba.load()方法初始化默认分词器,以下只是个人用法,可以不用和我一样jieba.load({ userDict: 'C:/path/to/dictionary.txt', // 添加自定义词典 stopWordDict:'C:/path/to/stopwords.txt', //加载停用词文件 });- 进行分词: 使用
nodejieba.cut方法进行分词。该方法接受两个参数,第一个参数是要分词的文本字符串,第二个参数是分词的模式,例如 "cut" 表示精确模式,"cutAll" 表示全模式,"cutForSearch" 表示搜索引擎模式。const text = "我爱自然语言处理"; const result = nodejieba.cut(text); console.log(result);输出结果类似于
?[ '我', '爱', '自然语言', '处理' ]- 其他功能
添加自定义词典: 你可以通过nodejieba.insertWord(word)方法向分词器添加自定义词汇:nodejieba.insertWord('人工智能');关键词提取: Nodejieba 还提供了关键词提取的功能,通过
nodejieba.extract方法实现,第一个参数为要提取的句子,第二个参数为提取几个关键词
?const keywords = nodejieba.extract(text, 5); // 提取前5个关键词 console.log(keywords);比如输入‘怎么获取更多活动积分’,输出结果大概如下,word为关键词,weight为权重
{ word: '积分', weight: 8.28754954559 }, { word: '获取', weight: 6.91781490051 }, { word: '活动', weight: 4.71207177215 }, { word: '怎么', weight: 4.41962335578 }进行词性标注:使用
nodejieba.tag方法进行词性标注。该方法接受一个文本字符串作为参数,并返回一个数组,每个元素是一个对象,包含了词汇和对应的词性。
?const text = "我爱自然语言处理"; const taggedWords = nodejieba.tag(text); console.log(taggedWords);输出结果类似于
?[ { word: '我', tag: 'r' }, { word: '爱', tag: 'v' }, { word: '自然语言', tag: 'l' }, { word: '处理', tag: 'v' } ]释放分词器资源:当不再需要使用分词器时,可以通过
nodejieba.release()方法释放资源:nodejieba.release();
记录一下。。。。?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 电脑内存满了怎么清理内存?试试这6个方法~
- 【Vue2+3入门到实战】(12)自定义指令的基本语法(全局、局部注册)、 指令的值、v-loading的指令封装 详细示例
- Linux--磁盘与文件系统
- vue2 pdfjs-2.8.335-dist pdf文件在线预览功能
- antd时间选择器,设置显示中文
- 进程的介绍及相关命令
- 关于有源电力滤波器在地铁站低压配电系统中的应用分析——安科瑞赵嘉敏
- 2023年度AI技术盘点:突飞猛进的技术进展与未来挑战
- 在mybatis中编写SQL时,提示表名和字段名的设置方法
- 嵌入式软件开发对硬件知识的掌握要求要多高?