MySQL之基于代价的慢查询优化建议
1.背景
慢查询是指数据库中查询时间超过指定阈值(美团设置为 100ms)的 SQL,它是数据库的性能杀手,也是业务优化数据库访问的重要抓手。
如何优化慢查询呢?最直接有效的方法就是选用一个查询效率高的索引。关于高效率的索引推荐,主要在日常工作中,基于经验规则的推荐随处可见,对于简单的、SQL,如
select * from sync_test1 where name like 'Bobby%',
直接添加索引 IX(name) 就可以取得不错的效果;但对于稍微复杂点的 SQL,如
select from sync_test1 where name like 'Bobby%' and dt > '2021-07-06'
到底选择 IX(name)、IX(dt)、IX(dt,name) 还是 IX(name,dt),该方法也无法给出准确的回答。更别说像多表 Join、子查询这样复杂的场景了。所以采用基于代价的推荐来解决该问题会更加普适,因为基于代价的方法使用了和数据库优化器相同的方式,去量化评估所有的可能性,选出的是执行 SQL 耗费代价最小的索引。
2.基于代价的优化器介绍
2.1 SQL 执行与优化器
一条 SQL 在 MySQL 服务器中执行流程主要包含:SQL 解析、基于语法树的准备工作、优化器的逻辑变化、优化器的代价准备工作、基于代价模型的优化、进行额外的优化和运行执行计划等部分。具体如下图所示:

2.2 代价模型介绍
而对于优化器来说,执行一条 SQL 有各种各样的方案可供选择,如表是否用索引、选择哪个索引、是否使用范围扫描、多表 Join 的连接顺序和子查询的执行方式等。如何从这些可选方案中选出耗时最短的方案呢?这就需要定义一个量化数值指标,这个指标就是代价 (Cost),我们分别计算出可选方案的操作耗时,从中选出最小值。
代价模型将操作分为 Server 层和 Engine(存储引擎)层两类,Server 层主要是CPU 代价,Engine 层主要是 IO 代价,比如 MySQL 从磁盘读取一个数据页的代价io_block_read_cost 为 1,计算符合条件的行代价为 row_evaluate_cost 为 0.2。除此之外还有:
memory_temptable_create_cost (default 2.0) 内存临时表的创建代价。
memory_temptable_row_cost (default 0.2) 内存临时表的行代价。
key_compare_cost (default 0.1) 键比较的代价,例如排序。
disk_temptable_create_cost (default 40.0) 内部 myisam 或 innodb 临时
表的创建代价。
disk_temptable_row_cost (default 1.0) 内部 myisam 或 innodb 临时表的行
代价。
在 MySQL 5.7 中,这些操作代价的默认值都可以进行配置。为了计算出方案的总代价,还需要参考一些统计数据,如表数据量大小、元数据和索引信息等。MySQL 的代价优化器模型整体如下图所示:
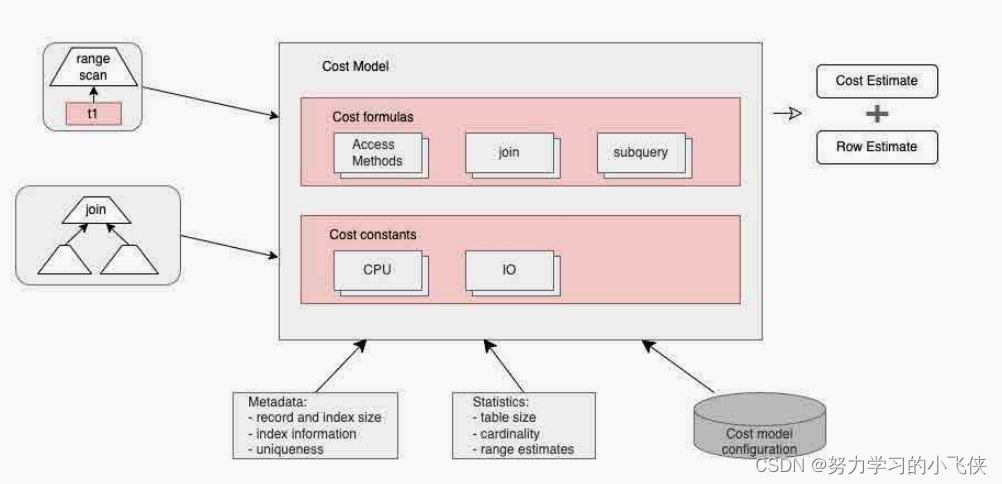
2.3 基于代价的索引选择
还是继续拿上述的 SQL
select * from sync_test1 where name like 'Bobby%' and dt > '2021-07-06'
为例,我们看看 MySQL 优化器是如何根据代价模型选择索引的。
首先,我们直接在建表时加入四个候选索引
Create Table: CREATE TABLE `sync_test1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`cid` int(11) NOT NULL,
`phone` int(11) NOT NULL,
`name` varchar(10) NOT NULL,
`address` varchar(255) DEFAULT NULL,
`dt` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `IX_name` (`name`),
KEY `IX_dt` (`dt`),
KEY `IX_dt_name` (`dt`,`name`),
KEY `IX_name_dt` (`name`,`dt`)
) ENGINE=InnoDB
通过执行 explain 看出 MySQL 最终选择了 IX_name 索引。
mysql> explain select * from sync_test1 where name like ‘Bobby%’and dt > ‘2021-07-06’;
+----+-------------+------------+------------+-------+-------------------------------------+----
-----+---------+------+------+----------+------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key
| key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+-----------------------------------
-----+---------+------+------+----------+------------------------------------+
| 1 | SIMPLE | sync_test1 | NULL | range | IX_name,IX_dt,IX_dt_name,IX_name_dt | IX_
name | 12 | NULL | 572 | 36.83 | Using index condition; Using where |
+----+-------------+------------+------------+-------+-----------------------------------
-----+---------+------+------+----------+------------------------------------+
然后再打开 MySQL 追踪优化器 Trace 功能。可以看出,没有选择其他三个索引的原因均是因为在其他三个索引上使用 range scan 的代价均 >= IX_name。
mysql> select * from INFORMATION_SCHEMA.OPTIMIZER_TRACE\G;
*************************** 1. row ***************************
TRACE: {
...
“rows_estimation”: [
{
“table”:“`sync_test1`”,
“range_analysis”: {
“table_scan”: {
“rows”: 105084,
“cost”: 21628
},
...
“analyzing_range_alternatives”: {
“range_scan_alternatives”: [
{“index”:“IX_name”,
“ranges”: [
“Bobby\u0000\u0000\u0000\u0000\u0000 <= name <= Bobby?????”
],
“index_dives_for_eq_ranges”: true,
“rowid_ordered”: false,
“using_mrr”: false,
“index_only”: false,
“rows”: 572,
“cost”: 687.41,
“chosen”: true
},
{
“index”:“IX_dt”,
“ranges”: [
“0x99aa0c0000 < dt”
],
“index_dives_for_eq_ranges”: true,
“rowid_ordered”: false,
“using_mrr”: false,
“index_only”: false,
“rows”: 38698,
“cost”: 46439,
“chosen”: false,
“cause”:“cost”
},
{
“index”:“IX_dt_name”,
“ranges”: [
“0x99aa0c0000 < dt”
],
“index_dives_for_eq_ranges”: true,
“rowid_ordered”: false,
“using_mrr”: false,
“index_only”: false,
“rows”: 38292,
“cost”: 45951,
“chosen”: false,
“cause”:“cost”
},
{
“index”:“IX_name_dt”,
“ranges”: [
“Bobby\u0000\u0000\u0000\u0000\u0000 <= name <= Bobby?????”
],
“index_dives_for_eq_ranges”: true,
“rowid_ordered”: false,
“using_mrr”: false,
“index_only”: false,“rows”: 572,
“cost”: 687.41,
“chosen”: false,
“cause”:“cost”
}
],
“analyzing_roworder_intersect”: {
“usable”: false,
“cause”:“too_few_roworder_scans”
}
},
“chosen_range_access_summary”: {
“range_access_plan”: {
“type”:“range_scan”,
“index”:“IX_name”,
“rows”: 572,
“ranges”: [
“Bobby\u0000\u0000\u0000\u0000\u0000 <= name <= Bobby?????”
]
},
“rows_for_plan”: 572,
“cost_for_plan”: 687.41,
“chosen”: true
}
...
}
1.走全表扫描的代价:io_cost + cpu_cost = (数据页个数 * io_block_read_cost)+ ( 数 据 行 数 * row_evaluate_cost + 1.1) = (data_length / block_size + 1)+ (rows * 0.2 + 1.1) = (9977856 / 16384 + 1) + (105084 * 0.2 + 1.1) = 21627.9。
2.走二级索引 IX_name 的代价:io_cost + cpu_cost = ( 预估范围行数 * io_block_read_cost + 1) + ( 数据行数 * row_evaluate_cost + 0.01) = (572 * 1 + 1) + (5720.2 + 0.01) = 687.41。
3.走二级索引 IX_dt 的代价:io_cost + cpu_cost = ( 预估范围行数 * io_block_read_cost + 1) + ( 数据行数 * row_evaluate_cost + 0.01) = (38698 * 1 + 1) + (386980.2 + 0.01) = 46438.61。4.走二级索引 IX_dt_name 的代价 : io_cost + cpu_cost = ( 预估范围行数 * io_block_read_cost + 1) + ( 数 据 行 数 * row_evaluate_cost + 0.01) = (38292 * 1 + 1) + (38292 * 0.2 + 0.01) = 45951.41。
5.走二级索引 IX_name_dt 的代价:io_cost + cpu_cost = ( 预估范围行数 * io_block_read_cost + 1) + ( 数 据 行 数 * row_evaluate_cost + 0.01) = (572 * 1 + 1) + (572*0.2 + 0.01) = 687.41。
2.4 基于代价的索引推荐思路
如果想借助 MySQL 优化器给慢查询计算出最佳索引,那么需要真实地在业务表上添加所有候选索引。对于线上业务来说,直接添加索引的时间空间成本太高,是不可接受的。MySQL 优化器选最佳索引用到的数据是索引元数据和统计数据,所以我们想否可以通过给它提供候选索引的这些数据,而非真实添加索引的这种方式来实现。
通过深入调研 MySQL 的代码结构和优化器流程,我们发现是可行的:一部分存在于Server 层的 frm 文件中,比如索引定义;另一部分存在于 Engine 层中,或者通过调用 Engine 层的接口函数来获取,比如索引中某个列的不同值个数、索引占据的页面大小等。索引相关的信息,如下图所示:
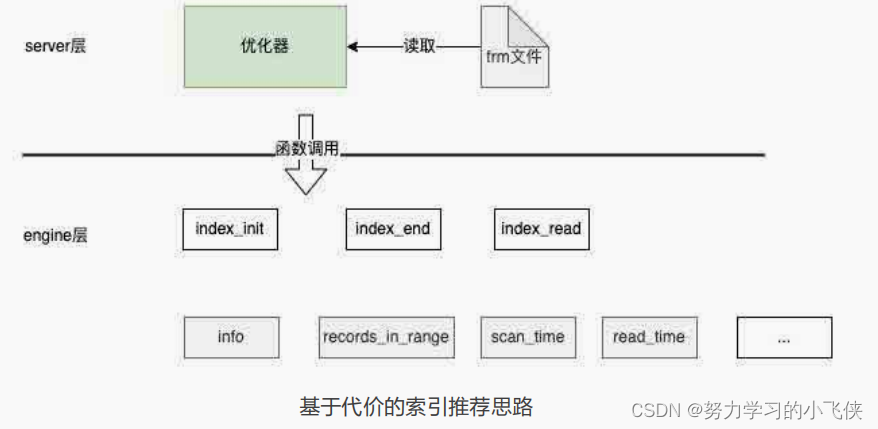
因为 MySQL 本身就支持自定义存储引擎,所以索引推荐思路是构建一个支持虚假索引的存储引擎,在它上面建立包含候选索引的空表,再采集样本数据,计算出统计数据提供给优化器,让优化器选出最优索引,整个调用关系如下图所示:

3.索引推荐实现
因为存储引擎本身并不具备对外提供服务的能力,直接在 MySQL Server 层修改也难以维护,所以我们将整个索引推荐系统拆分成支持虚假索引的 Fakeindex 存储引擎和对外提供服务的 Go-Server 两部分,整体架构图如下:
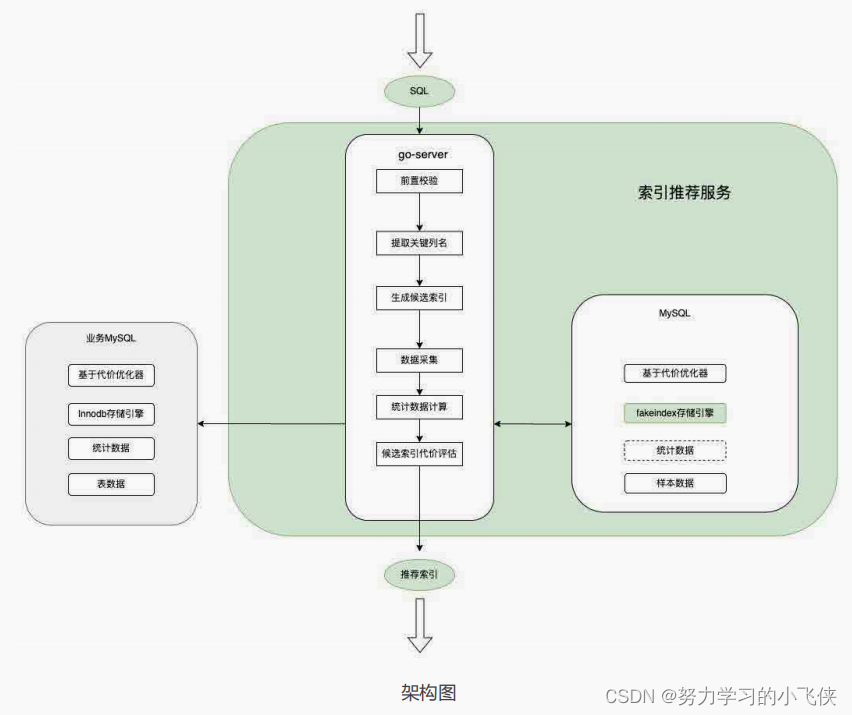
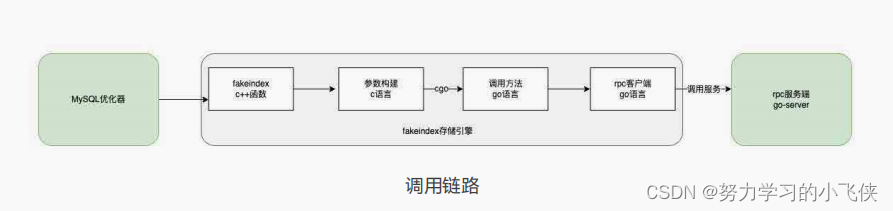
首先简要介绍一下 Fakeindex 存储引擎,这是一个轻量级的存储引擎,负责将索引的相关接口透传到 Go-Server 部分。因为它必须采用 C++ 实现,与 Go-Server 间存在跨语言调用的问题,我们使用了 Go 原生的轻量级 RPC 技术 +cgo 来避免引入重量级的 RPC 框架,也不必引入第三方依赖包。函数调用链路如下所示,MySQL优化器调用 Fakeindex 的 C++ 函数,参数转换成 C 语言,然后通过 cgo 调用到Go 语言的方法,再通过 Go 自带的 RPC 客户端向服务端发起调用。
4.慢查询治理运营
我们主要从时间维度的三个方向将慢查询接入索引推荐,推广治理:

4.1 过去 - 历史慢查询
这类慢查询属于过去产生的,并且一直存在,数量较多,治理推动力不足,可通过收集历史慢查询日志发现,分成两类接入:
● 核心数据库:该类慢查询通常会被周期性地关注,如慢查询周报、月报,可直
接将优化建议提前生成出来,接入它们,一并运营治理。
● 普通数据库:可将优化建议直接接入数据库平台的慢查询模块,让研发自助地
选择治理哪些慢查询。
4.2 现在 - 新增慢查询
这类慢查询属于当前产生的,数量较少,属于治理的重点,也可通过实时收集慢查询日志发现,分成两类接入:
● 影响程度一般的慢查询:可通过实时分析慢查询日志,对比历史慢查询,识别出新增慢查询,并生成优化建议,为用户创建数据库风险项,跟进治理。
● 影响程度较大的慢查询:该类通常会引发数据库告警,如慢查询导致数据库Load 过高,可通过故障诊断根因系统,识别出具体的慢查询 SQL,并生成优化建议,及时推送到故障处理群,降低故障处理时长。
4.3 未来 - 潜在慢查询
这类查询属于当前还没被定义成慢查询,随着时间推进可能变成演变成慢查询,对于
一些核心业务来说,往往会引发故障,属于他们治理的重点,分成两类接入:
● 未上线的准慢查询:项目准备上线而引入的新的准慢查询,可接入发布前的集成测试流水线,Java 项目可通过 agentmain 的代理方式拦截被测试用例覆盖到的 SQL,再通过经验 +explain 识别出慢查询,并生成优化建议,给用户在需求管理系统上创建缺陷任务,解决后才能发布上线。
● 已上线的准慢查询:该类属于当前执行时间较快的 SQL,随着表数据量的增 加,会演变成慢查询,最常见的就是全表扫描,这类可通过增加慢查询配置参 数 log_queries_not_using_indexes 记录到慢日志,并生成优化建议,为用户创建数据库风险项,跟进治理。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!