【LLM】Prompt微调
发布时间:2024年01月16日
Prompt
在机器学习中,Prompt通常指的是一种生成模型的输入方式。生成模型可以接收一个Prompt作为输入,并生成与该输入相对应的输出。Prompt可以是一段文本、一个问题或者一个片段,用于指导生成模型生成相应的响应、续写文本等。
Prompt优化
一般大模型蕴含的训练数据量往往是百亿级别甚至万亿级别。大模型通常无法在小数据上微调。因此,基于Prompt的微调技术便成为了首要选择。
Prompt优化方式
有两种方向上的优化方式:
-
从Prompt结构上
- Few-Shot(FS):模型推理时给予少量样本,但不允许进行权重更新。
- One-Shot(1S):模型推理时只给予一个样本。
- Zero-Shot(0S):模型推理时不允许提供样本。
-
从Prompt内容上
- Role Prompt:与大模型玩
角色扮演游戏。让大模型想象自己是某方面的专家、因而获得更好的任务效果。 - Instruction Prompt:指令形式的Prompt。
- Chain-of-Thought(CoT)Prompt:常见于推理和计算任务中,通过让大模型给出
推理或计算步骤来解决较难的推理问题,比如进行应用数学计算。 - Multimodal Prompt:多模态Prompt。顾名思义,输入不再是单一模态的Prompt,而是包含了众多模态的信息。比如同时输入文本和图像与多模态大模型进行交互。
- Role Prompt:与大模型玩
比较重要的是Few-Shot Prompt和Chain-of-Thought Prompt。它们对后续人们构建AI Agent应用以及各项大模型产品落地起到了关键的作用。
Few-Shot Prompt
eg:尝试给宠物狗取个名字
- Zero-Shot

- Few-Shot
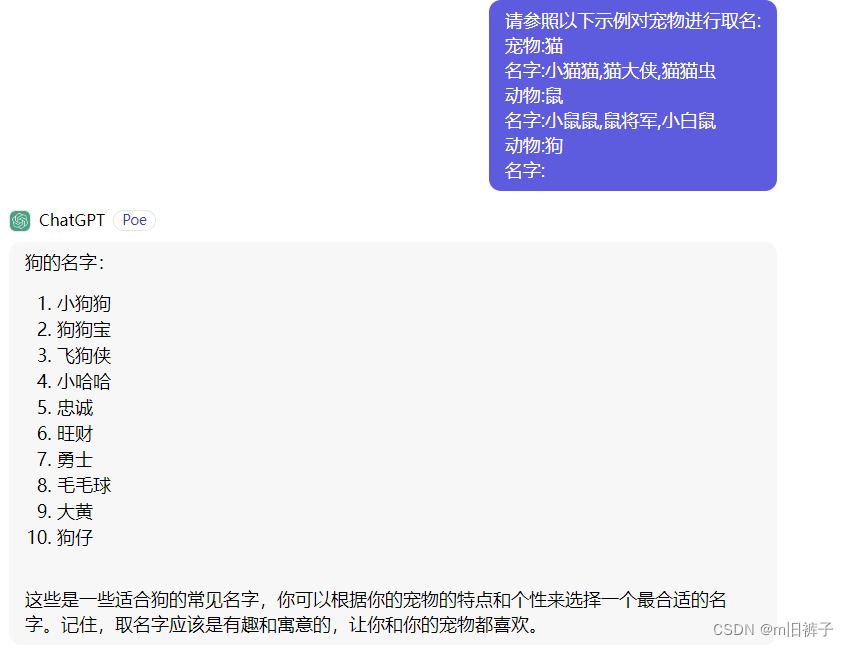
可以看到示例中,Zero-Shot的Prompt中,大模型给出的名字比较泛化,只是一种可能的比较合理的解释。Few-Shot的Prompt中,大模型能够了解我们的取名倾向,并给出和示例风格一致的名字。
Chain-of-Thought Prompt
CoT Prompt则能够大幅提高大模型的多步推理能力:
- 不推理

- Cot推理
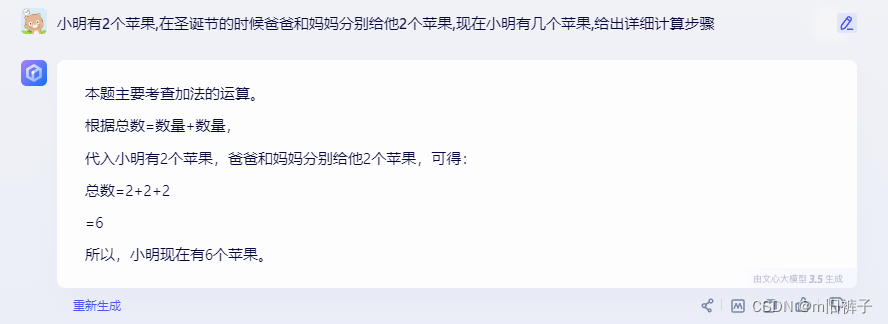
可以看出,大模型在直接给出结果时,有时候答案明显是错误的,但我们只需要改动一下Prompt,使用Cot Prompt,让他输出详细的计算过程或者思考过程,大模型就能够给出正确的结果。
CRISPE框架
有时合理组合使用这些Prompt优化方法,就可以让Prompt效果更好,整体框架结构:
- CR:Capacity and Role(能力和角色),你希望AI扮演怎样的角色。
- I:Insight(洞察),提供背景信息和上下文。
- S:Statement(陈述),你希望AI做什么。
- P:Personality(个性),你希望AI以什么风格或方式回答你。
- E:Experiment(实验),要求AI为你提供多个答案。
假设我们的目标是获取一个浅显易懂的关于导数的解释方式,第一种方式是:

第二种方式我们来应用一下框架:

Prompt的持续优化
Prompt的优化并不是一蹴而就的,而是一个持续的过程,使用上述方式和框架也不能够保证每次都可以一次就拿到满意的结果,尤其是当我们需要大模型完成一些比较复杂的工作时。但是遵循这些方法,我们可以有更高的可能性能够通过较少的调整次数得到一个满意的结果,并且能够在这个结果上进行微调,比如润色,适当地增加图表等。
Prompt 除了人工调节,也可以让机器自动调节,也就是由机器自动生成 Prompt,这就是 Prompt Tuning。
文章来源:https://blog.csdn.net/m0_53328239/article/details/135621754
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 游戏中小地图的制作__unity基础开发教程
- Linux系统操作——tcping安装与使用
- 从数据角度解析抖音商品详情API在电商应用中的重要性
- 数据结构 模拟实现ArrayList顺序表
- 多线程简要理解
- 快麦ERP退货借助APPlink快速同步CRM
- CNAS中兴新支点——性能测试的定义
- 【解刊】1个月录用,18天见刊!CCF-A类顶刊,中科院基金委主办,国人占比97%!
- 单目测距(yolo-目标检测+标定+测距代码)
- 模型之掷骰子问题