基于InternLM和LangChain搭建你的知识库

InternLM是一个自然语言处理工具,主要用于文本分类、实体识别、情感分析等任务,而LangChain则是一个基于深度学习的自然语言处理框架。这两种工具都可以用于构建知识库,使知识库的创建和更新变得更加容易和高效。基于InternLM和LangChain搭建知识库的含义就是利用这两种工具来创建和组织一个系统化的知识库,提高其准确性和可维护性,降低维护成本,同时使知识库更加易于使用。
一、大模型开发范式
1.LLM的局限性
LLM的局限性包括知识时效性受限、专业能力有限和定制化成本高。
- 知识时效性受限:LLM的局限性之一是知识时效性受限。由于语言模型的学习数据主要来源于互联网和大型文本库,这些数据可能无法涵盖最新的知识和信息。因此,LLM在处理实时事件、新闻热点等方面的能力有限,需要不断更新和迭代模型以保持其准确性和可靠性。
- 专业能力有限:语言模型的能力取决于其训练的数据、算法的准确性和问题的明确性。然而,对于某些专业领域,如医学、法律等,LLM可能无法达到人类专家的水平。这是因为专业领域的术语、概念和知识体系可能非常复杂,超出了LLM的处理能力。
- 定制化成本高:目前LLM主要依赖于大规模的语料库进行训练,而定制化LLM需要大量的数据、计算资源和时间。此外,由于LLM的算法和模型非常复杂,调试和优化模型需要专业的技能和经验。因此,定制化LLM的成本非常高,对于小型企业和个人用户来说可能不太实际。?

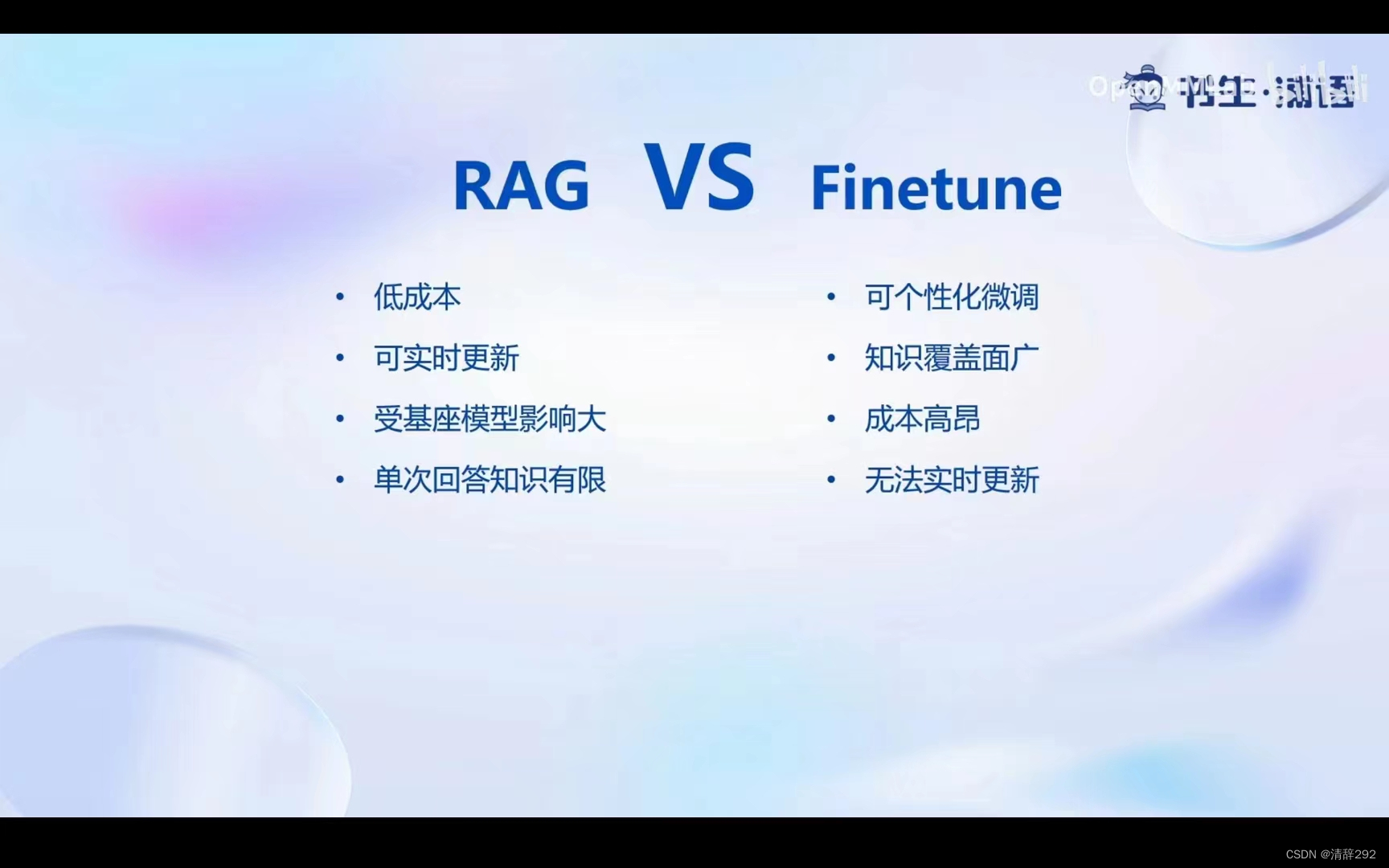
2.RAG VS Finetune?
RAG(Retrieval-Augmented Generation)是一种将检索与生成结合的模型。它的主要优势在于能够利用预训练的语言模型,结合检索到的信息,生成更加丰富和准确的内容。
Finetune是一种针对特定任务对预训练模型进行微调的方法。通过在特定数据集上对模型进行训练,Finetune能够使模型更好地适应特定任务的需求。
RAG和Finetune各有特点。RAG结合检索和生成,适用于多领域,通用性强;而Finetune针对特定任务优化,性能更出色。RAG受基座模型影响大,而Finetune训练成本高。选择应根据任务需求和资源限制。
3.RAG检索增强生成的流程
- 用户输入文本;
- 对输入的文本进行向量化处理;
- 匹配到RAG模型,利用模型预测相似文本段;
- 通过Prompt技术,将检索到的信息与生成的内容结合,形成最终输出。
 ?
?
二、LangChain简介
1.LangChain框架简介
LangChain框架是一个开源工具,旨在通过为各种LLM(Large Language Model)提供通用接口来简化应用程序的开发流程。它帮助开发者自由构建LLM应用,使得开发过程更加便捷高效。LangChain框架通过提供通用接口和核心组成模块“链(Chains)”的设计,简化了LLM应用程序的开发流程,提高了开发效率。

2.基于LangChain搭建RAG应用?
使用LangChain搭建RAG应用的流程如下:
- 数据准备:首先,需要准备一定量的本地文档数据,这些数据可以是结构化的文本文件,也可以是非结构化的文本块。
- 文档加载:使用Local Unstructured Text Documents Loader将本地文档加载到系统中。
- 文档分割:使用Splitter将加载的文档分割成多个文本块或句子。
- 句子嵌入:使用Sentence Embedding Transformer对每个句子进行嵌入,生成句子向量。
- 查询生成:根据特定的查询条件或用户输入,生成查询向量。
- 检索增强:使用LangChain的Chroma Similarity Vector进行相似度计算,找到与查询向量相似的相关文本块或句子。
- 中间模型预测:利用中间模型InterIM对相关文本块或句子进行预测,得到初步的答案。
- 生成最终答案:根据中间模型的预测结果,结合Prompt技术,生成最终的答案。
- 测试与评估:使用Test System对生成的答案进行测试和评估,确保答案的准确性和有效性。
- 优化与迭代:根据测试结果,对流程进行优化和迭代,不断提升RAG应用的性能和效果。
 ?
?
三、构建向量数据库
构建向量数据库的流程
构建向量数据库的流程主要包括以下几个步骤:
- 加载源文件:确定源文件类型,并针对不同类型源文件选用不同的加载器。核心在于将带有格式的文本转化为无格式字符串。
- 文档分块:由于单个文档往往超过模型上下文上限,需要对加载的文档进行切分。一般按字符串长度进行分割,可以手动控制分割块的长度和重叠区间长度。
- 文档向量化:可以使用任一种Embedding模型来进行向量化,将文档转化为向量形式存入向量数据库。向量数据库用于支持语义检索,可以使用多种支持语义检索的向量数据。
 ?
?
四、搭建知识库助手
1. 将InternLM接入LangChain
将InternLm接入LangChain的意义在于,它可以使开发者更加专注于应用程序的业务逻辑和功能实现,而无需过多关注底层的自然语言处理细节。通过使用LangChain提供的通用接口,开发者可以轻松地调用InternLm的功能,从而实现各种自然语言处理任务,如文本分类、情感分析、问答系统等。

2.构建检索·问答链?
构造检索问答链需要经过以下几个步骤:
- 确定查询(Query):这是检索问答链的起点,用户的问题将被转化为查询。
- 知识检索:利用LangChain提供的检索问答链接版,可以自动实现知识检索。
- Prompt嵌入:在获取到知识库中的相关信息后,将这些信息嵌入到Prompt中。
- LLM(Large Language Model)回答:利用LLM模型对查询进行回答。
- 调用检索问答链:将基于InternLM的自定义LLM和已构建的向量数据库接入到检索问答链的上游,调用检索问答链,即可实现知识库助手的核心功能。
- 生成答案(Answer):基于LLM的回答和Prompt嵌入的信息,生成最终的答案。

3.RAG方案优化建议?
RAG方案优化建议可以总结为以下几点:
- 检索精度优化:可以通过基于语义进行分割,保证每一个块(chunk)的语义完整。为每一个块生成概括性索引,以提高检索时的匹配精度。
- Prompt性能优化:迭代优化Prompt策略,以提高LLM回答的准确性和效率。
 ?
?
五、Web Demo部署
Web Demo部署通常指的是将Web Demo应用程序部署到生产环境的过程。这个过程涉及到一系列的步骤,以确保应用程序能够稳定运行并满足性能和安全性的要求。

六、动手实践环节
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 专业130+总400+哈尔滨工业大学803信号与系统和数字逻辑电路考研经验哈工大,电子信息,信息与通信工程,信通
- postman后端测试时invalid token报错+token失效报错解决方案
- 【VS】NETSDK1045 当前 .NET SDK 不支持将 .NET 6.0 设置为目标。
- RediSearch vs. Elasticsearch vs. solr
- QMessageBox自定义按钮文本中文显示,按钮个数等
- 【JavaEE进阶】 Spring Boot?志
- GEE:面对对象(斑块/超像素)尺度的随机森林回归预测教程
- 手机卡分销平台企业分析
- typedef用法汇总和代码实战
- 基于ssm个人日常事务管理系统论文