邂逅Node.JS的那一夜
邂逅Node.JS的那一夜🌃
本篇文章,学习记录于:尚硅谷🎢
本篇文章,并不完全适合小白,需要有一定的HTML、CSS、JS、HTTP、Web等知识及基础学习:
🆗,紧接上文,学习了:JavaScript 快速入门手册、新特性 之后,让我们来认识一个新的盆友 Node.JS
那是一个满是星星的夜晚,正把玩JS的我,想到一个问题,一个个单独的.JS文件,如何组合在一起成为一个项目
看网上好多大佬,使用 JS 像Java一样导包、写脚本、甚至连接服务器写后端….,这是如何做到的呢🤔?经过一番查找认识了它🎉
Node.js 与 JavaScript
Node.js是什么: 学习NodeJS首先就是要掌握 JavaScript(这里不介绍了)
Node.js(简称Node)是一个基于Chrome V8引擎的开源、跨平台的JavaScript运行时环境:
Node.js提供了一系列的库和工具,它扩展了 JavaScript 的用途,使得开发者能够编写服务器端应用程序,使JS更为强大和灵活;
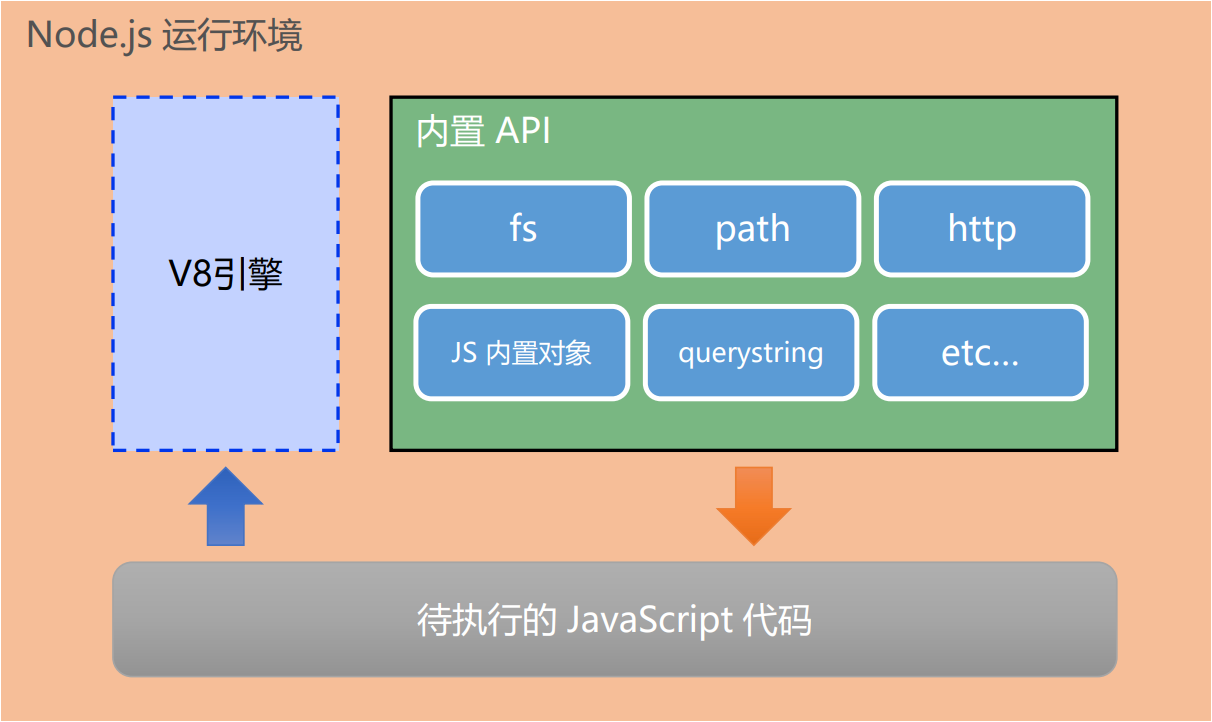
JavaScript运行环境:
最早JavaScript 主要用于网页开发—>前端页面交互,所以运行环境主要是浏览器
- 提供了JavaScript的运行环境:解释器(浏览器中的V8引擎)、DOM(文档对象模型)、BOM(浏览器对象模型)
随着Node.js的出现,JavaScript获得了一种全新的运行环境,使其可以在服务器端运行:
- Node.js建立在Chrome V8引擎之上,以及内置模块:FS(文件模块)、path(处理文件资源路径)、http(HTTP 服务器)
Node 和 浏览器运行环境的区别:
二者环境有一些关键的区别,主要体现在它们的设计目标、提供的功能、核心模块等方面:
Node.js: 设计用于服务器端应用程序的运行环境,它的目标是提供高性能、非阻塞I/O的能力
- Node.js: 提供了一些特定于服务器端的全局对象,如
global对象,核心模块,如HTTP、FS(文件系统)等 - Node.js: 使用CommonJS模块系统,允许开发者使用
require和module.exports来导入和导出模块 - Node.js: 具有强大的网络通信能力,可以轻松创建HTTP服务器、客户端,并支持其他协议
浏览器环境: 设计用于在浏览器中执行JavaScript,实现网页交互和动态内容,主要关注于与用户界面的交互和浏览器特定的APl
-
浏览器环境: 全局对象通常是
window、DOM(文档对象模型)、BOM(浏览器对象模型)相关的API,例如document、window -
浏览器环境: 可以使用ES6的
import和export语法,以及浏览器原生的模块系统 -
浏览器环境: 主要通过XMLHttpRequest对象或Fetch API来进行与服务器的通信
二者都是JavaScript运行的地方,它们在设计目标、提供的功能、核心模块等方面有很大的差异,使得它们适用于不同的应用场景
基于 Node.js 提供的这些基础能,很多强大 的工具和框架如雨后春笋,层出不穷:
① 基于 Express 框架(http://www.expressjs.com.cn/),可以快速构建 Web 应用
② 基于 Electron 框架(https://electronjs.org/),可以构建跨平台的桌面应用
③ 基于 restify 框架(http://restify.com/),可以快速构建 API 接口项目
④ 读写和操作数据库、创建实用的命令行工具辅助前端开发、etc…
Node.js的初体验:
安装NodeJS环境:
NodeJS 是一个服务应用程序,需要安装在服务器|设备上,使JavaScript可以直接在服务器上运行,不同的操作系统版本:Node官网🔗
各位,JYM可以到官网下载,也可以选择对应的版本:Other Dowloads其他版本🔗
区分 LTS 版本和 Current 版本的不同:
-
LTS 为长期稳定版,对于追求稳定性的企业级项目来说,推荐安装 LTS 版本的 Node
-
Current 为新特性尝鲜版,对热衷于尝试新特性的用户来说,推荐安装 Current 版本的 Node.js
Current 版本中可 能存在隐藏的 Bug 或安全性漏洞,因此不推荐在企业级项目中使用 Current 版本的 Node
Hello World
Windows安装Node服务,一般会默认配置环境变量:win+R 输入cmd:node -v 查看服务版本,确认安装成功!
随便编写一个:HelloWorld.JS
/** Node.js
* Node.js(简称Node)是一个基于Chrome V8引擎的开源、跨平台的JavaScript运行时环境
* 因为和浏览器的内置API不同所以存在一些区别,没有: windwo、document...对象 同时拥有自己的模块 */
console.log("node Hello World");
在文件目录中:node 文件路径\名.js + Enter 回车 运行JS代码,对于执行时间长的命令使用:ctrl+c 终止运行
🆗到这里,恭喜你已经入门了! 🎉🎉 下面让我们深入了解Node.JS吧👇
Buffer 缓冲器:
JavaScript 语言没有用于读取或操作二进制数据流的机制,NodeJS提供了一个Buffer内置对象对二进制数据的操作:
- Buffer 是一个类似于数组的对象 ,
固定长度的字节序列,每个元素的大小为1字节byte=8bit - Buffer 本质是一段内存空间,专门用来处理
二进制数据:因此:Buffer性能较好,可以直接对计算机内存进行操作
Buffer的创建:
/** Buffer的创建: */
const b1 = Buffer.alloc(10); //从内存上获取一段长度为10byte空间赋值Buffer
console.log(b1); //<Buffer 00 00 00 00 00 00 00 00 00 00> 十六进制
const b2 = Buffer.allocUnsafe(10); //随机获取内存上一段长度为10byte空间赋值Buffer,所以可能存在内存空间上的旧数据
console.log(b2); //<Buffer 59 8c 75 0b 6a 02 00 00 20 00> 有可能都是00 十六进制
//通过字符|数组...参数创建Buffer
const b3 = Buffer.from('Node.js');
const b4 = Buffer.from([11, 54, 68, 37]);
console.log(b3); //直接console则展示每个字节元素对应的ASCLL码值的十六进制
console.log(b4); //默认其实是UNICODE码表,ASCLL完全兼容UNICODE,所以查询直接查找ASCLL
Buffer的操作:
Buffer是一个类似于数组的对象,所以可以像数组一样操作元素的操作:
/** Buffer是一个类似于数组的对象,所以可以像数组一样操作元素的操作: */
const b3 = Buffer.from('Node.js');
// b3[0] = 110; //对应ASCLL小写n
console.log(b3[0]); //[下标] 获取字节元素
console.log(b3.length); //length Buffer内存字节长度
console.log(b3.toString()); //toString() 查看元素内容,默认 UTF-8编码格式
console.log(b3[0].toString(2)); //toString(2) 查看元素内容,并以二进制形式展示
//Buffer是一段固定长度连续的内存空间,因为是连续的内存空间所以快,也不方便删减内存元素...
/** Buffer关于中文的操作 */
const bus = Buffer.from('你好'); //中文一个字节占用3字节
console.log(bus);
console.log(bus.length); //6
console.log(bus.toString()); //你好
Buffer的溢出: Buffer是一个类字节数组,我们都知道一个:1byte字节===8bit 也就是:28 = 256 也就是:最大长度不能大于 255
const bu = Buffer.alloc(1);
bu[0] = 255;
console.log(bu); //<Buffer ff>
bu[0] = 256;
console.log(bu); //<Buffer 00> ???怎么编成0了
/** 对于超出字节长度是赋值并不会报错,而是进行溢出操作:赋值元素二进制大于8位的内容舍弃(仅保留从右-左8位长度bit)
* 255的二进制:1111 1111 =>保留结果: 11111111
* 256的二进制: 0001 0000 0000 =>保留结果: 00000000 */
FS 文件系统模块
FS 全称为 file system 文件系统 ,是 Node.js 中的内置模块,可以对计算机中的磁盘进行操作
它提供了一组方法,使得你能够在文件系统中执行各种操作,如读取文件、写入文件、获取文件信息、创建目录等
模块导入:
FS是Node中的一个内置模块,内置|外部模块使用前都需要导入:require
require 是 Node.js 环境中的’全局’变量,用来导入模块,导入FS的模块名就是fs:不同模块导入,对应不同的模块名
const fs = require('fs'); //require导入FS模块: fs变量接收模块对象
文件|写入|读取…操作:
文件写入
文件写入在计算机中是一个非常常见的操作:
- 下载文件、安装软件、保存程序日志,如 Git、编辑器保存文件、视频录制,都用到了文件写入
writeFile异步写入
语法:fs.writeFile(file, data,[options], callback)
- file: 路径+文件名,文件不存在则默认创建|存在则清空内容、data: 写入的文件内容,可以是字符|对象参数
- [options]:可选参数: 根据一些参数配置完成,追加等功能、callback: 回调函数对象,当文件写入成功|失败执行函数
{
//file: 相对|绝对文件路径: 文件不存在默认创建,路径不存在则目录拼接至文件名上...找不到盘符则报错;
fs.writeFile('.\www.txt','你好呀~',err =>{
//写入成功|失败执行函数,并传入错误对象:写入成功err=null
if (err) { return console.log('文件写入失败'); }
console.log('文件写入成功');
});
console.log('异步写入文件:不阻塞继续执行下面log');
}
writeFileSync同步写入
语法:fs.writeFileSync(file, data,[options]) 函数名比异步多了 Sync,参数和上述类似,同步方法没有回调函数
/** fs.writeFileSync(file, data,[options])
* 参数和上述类似:同步方法没有回调函数,报错就直接报错了... */
{
fs.writeFileSync('.\wsm.txt','你好呀Sync~');
console.log('同步写入阻塞程序文件写入完毕继续执行下面log');
fs.writeFileSync('.\wsm.txt',"\nflag参数实现文件追加...",{flag:'a'}); //{flag:'a'} 文件内容追加
}
[options] 常用参数设置: flag 、 mode、 encoding …
-
flag: 选项表示以何种方式打开文件:
r 只读模式、w 写入模式(默认)、a 追加模式 -
mode: 选项表示要设置的文件权限,控制文件的可读、可写、可执行属性的数字
-
encoding: 选项表示要使用的编码方式:
utf-8(默认)、ascii、base64
异步|同步Sync:
- 异步: 异步函数|代码块执行,代码并不会阻塞,继续执行下面的代码,异步代码执行完毕,自动执行回调函数获取运行结果.
- 同步: 代码执行到这里,程序会阻塞等待代码块执行完毕,之后才继续下面操作,对于比较耗时的程序,同步比较影响执行效率,比如文件写入
appendFile/Sync追加文件
appendFile 作用是在文件尾部追加内容,语法与 writeFile 完全相同,writeXxx可以设置options?追加内容📑
语法:fs.appendFile(file, data,[options],callback) 异步追加写入
{
//语法与writeFile语法完全相同
fs.appendFile('./www.txt','123\n',err=>{
if(err) { return console.log('文件写入失败'); }
console.log('文件写入成功'); });
fs.appendFile('./www.txt','456\n',err=>{
if(err) { return console.log('文件写入失败'); }
console.log('文件写入成功'); });
console.log('异步写入文件:不阻塞继续执行下面');
}
语法:fs.appendFileSync(file, data,[options]) 同步追加写入
/** fs.appendFileSync(file, data,[options])
* 参数和上述类似:同步方法没有回调函数,报错就直接报错了... */
{
fs.appendFileSync('.\wsm.txt','123\n');
fs.appendFileSync('.\wsm.txt','456\n');
console.log('同步写入阻塞程序文件写入完毕继续执行下面log');
}
createWriteStream流式写入
流式写入: 和追加写入类似,流 更适合用于大文件的写入,性能优于常规的追加写入…
上述的:fs.appendFile 每次写入对象都要创建对应的文件连接、写入、回调处理,这对于大文件的写入会很麻烦、占用资源
{
//1.导入FS模块
//2.根据路径创建对应的文件流对象
const ws = fs.createWriteStream('./wsm.txt', { flags: 'a' });
ws.write('123\n'); //3.使用文件流对象写入文件...
ws.write('456\n');
ws.write('789\n');
ws.end(); //4.文件写入文本关闭文件流资源: nodeJS也会自动关闭资源
}
程序打开一个文件是需要消耗资源的 ,流式写入可以减少打开关闭文件的次数
流式写入方式适用于大文件写入或者频繁写入的场景, writeFile 适合于写入频率较低的场景
文件读取
文件读取顾名思义,就是通过程序从文件中取出其中的数据:
- 电脑开机、程序运行、编辑器打开文件、查看图片、播放视频、播放音乐、Git 查看日志、上传文件、查看聊天记录
readFile异步读取
语法: fs.readFile(path,[options],callback)
/** fs.readFile(path,[options],callback)
* path: 路径+文件名,文件不存在则读取失败
* [options]: 可选参数配置,读取文件编码格式
* callback(err,data){ 回调函数当文件数据全读取,回调执行: data数据默认buffer类型 } */
{
//Demo:建议提前准备好要读取的文件;
fs.readFile('./wsm.txt', (err, data) => {
if (err) { return console.log('文件读取异常...'); }
console.log(data);
console.log(data.toString()); //buffer.toString(); 转UTF-8
});
}
readFileSync同步读取
语法:fs.readFileSync(path,[options])
/** 同步读取:
* fs.readFileSync(path,[options]) 返回值:String|Buffer*/
{
const rb = fs.readFileSync('./wsm.txt');
const sb = fs.readFileSync('./wsm.txt', 'utf-8'); //[options]设置读取文件编码格式;
console.log(rb);
console.log(sb);
console.log('同步读取文件: 读取结束继续执行下面log');
}
createReadStream流式读取
语法:fs.createReadStream(path,[options]) 流式读取对于大文件的读取,节省内存,并且是异步的
{
//1 引入FS模块
//2 根据文件路径创建文件读取流对象--这里需要更换自己的文件路径
const rs = fs.createReadStream('./resource/男娘.MP3'); //提前准备大文件: 图片/视频...
//3 给读取流对象 绑定data事件
rs.on('data', chunk => {
console.log(chunk); //默认块: 65536字节byte => 64KB 最后一块不满足会比较小;
//这样每次读取一块数据,对每块数据进行操作用完即回收减少内存开销,提高程序性能...
});
//4 [可选]:文件读取完成
rs.on('end', () => { console.log('文件读取结束'); })
}
普通读取 和 流式读取的区别:
-
普通读取: 是一种同步或异步的操作
它会一次性地读取文件的全部内容,然后执行回调函数或返回结果 -
流式读取: 是一种异步的操作,
它可以分段地读取文件,不需要等待文件完全加载到内存中流式读取可以节省内存空间,提高性能,适合处理大文件或网络数据
对于大文件,普通读取一次性读取是直接读进内存的,如果文件1G则等于1G内存,很容易内存溢出?
常用方法:
删除
在 Node.js 中,我们可以使用 unlink 或 unlinkSync 来删除文件,node14.4新增:rm|rmSync 语法:
删除时候要确认要删除的文件存在,不然会报错:Error: ENOENT: no such file or directory
fs.unlink(path, callback)fs.unlinkSync(path)
rm它有一些额外的选项|并支持对文件夹操作:
recursive (递归删除),force (强制删除),maxRetries (重试次数),retryDelay(重试间隔时间) …
fs.rm(path,[options],callback)fs.rmSync(path,[options])
/** 文件的删除:
* fs.unlink(path, callback) 同步删除 如果路径文件不存在则报错
* fs.unlinkSync(path) 异步删除 */
{
fs.unlink('./wsm.txt', err => {
if (err) return console.log('unlink删除失败');
console.log('unlink删除成功');
});
//同步方法并没有回调函数,原地返回相应结果,所以需要传统try-catch捕获异常
try {
fs.unlinkSync('./wsmm.txt');
console.log('unlinkSync删除成功');
} catch (error) { console.log('unlinkSync删除失败'); }
}
/** node14.4新增删除方法
* rm|rmSync 异步|同步的删除方法... */
{
/** 吐槽一下啊:本人想要复刻重复删除成功的过程始终没有实现,求路过的大佬指点一下: */
fs.rm('./wsm', { recursive: true ,maxRetries: 50, retryDelay: 100 }, err => {
if (err) return console.log('rm删除失败');
console.log('rm删除成功');
});
try {
fs.rmSync('./wsmm.txt');
console.log('rmSync删除成功');
} catch (error) { console.log('rmSync删除失败'); }
}
- 吐槽一下: 本人想要复刻:重复删除成功的过程始终没有实现,🧎🧎?♂?🧎?♀?路过的大佬指点一下,已经尝试:
- 网上说需要开启:
recursive: true - 代码执行过程中,创建要删除的文件夹
- 事先创建好文件夹,内部存放文件,系统程序打开占用文件资源,执行程序过程中关闭资源,均失败告终…
- 网上说需要开启:
重命名|剪切
Node.js 中,我们可以使用 rename 或 renameSync 来移动|重命名或文件夹
fs.rename(oldPath, newPath, callback)fs.renameSync(oldPath, newPath)
newPath 文件路径不变就是重命名,文件路径改变就是剪切
/** 文件的重命名|移动
* fs.rename(oldPath, newPath, callback) 异步
* fs.renameSync(oldPath, newPath) 同步
* oldPath :表示要修改的文件资源,不存在则报错;
* newPath :表示修改后的文件地址,单纯文件名发生改变——>重命名,文件路径|名改变——>剪切|重命名; */
{
//异步重命名|移动
fs.rename('./wwsm.txt', './www/wsmup.txt', err => console.log(err)); //移动的路径要存在则报错
//同步重命名|移动
// fs.renameSync('./wwsm.txt', './www/wsmup.txt');
}
文件复制Copy
对于文件的Copy 业务拆分就是:读+写:要Copy A文件,FS读取出来,创建写入新 B文件,就是Copy的过程~
需要注意: 读写文件的过程中,读写流比较节省内存,且效率高…. 对于大文件的Copy,建议使用流式操作
文件夹操作:
借助 Node.js 的能力,我们可以对文件夹进行 创建 、 读取 、 删除 等操作
mkdir 创建文件夹
fs.mkdir(path[, options], callback)异步创建fs.mkdirSync(path[, options])同步创建
/** 创建文件夹
* path: 指点创建的文件路径,文件存在则报错
* options: 可选配置完成特殊操作
* callback: 回调函数... */
fs.mkdir('./wsm',err=>{ console.log(err); }); //同级目录创建wsm文件夹,如果存在会报错;
fs.mkdir('./wsm/sss',{recursive:true},err=>{ console.log(err); }); //配置:可创建多级目录 目录存在并不会报错;
readdir 读取文件夹
fs.readdir(path,[options], callback)异步读取: 回调函数有两个形参;fs.readdirSync(path,[options])同步创建: 函数返回一个数组;
//回调函数接收两个参数: err(异常有值|无异常null)、data(数组数据结构:返回当前路径下所有文件名|目录)
fs.readdir('./wsm',(err,data)=>{
if(err) return console.log(err);
console.log(data);
});
rmdir 删除文件夹
fs.rmdir(path[, options], callback)异步删除fs.rmdirSync(path[, options])同步删除
// 默认:文件夹非空不允许删除
// fs.rmdir('./wwww',err=>{ console.log(err); });
// 设置{recursive:true}递归true 则文件非空|多级目录可以删除;
fs.rmdir('./wwww',{recursive:true},err=>{ console.log(err); });
{recursive:true} 随着node的版本上升后面可能会被淘汰 建议后面删除文件目录操作使用:fs.rm(...)
FS查看文件资源状态:
在 Node.js 中,我们可以使用 stat 或 statSync 来查看资源的详细信息
fs.stat(path,[options], callback)异步查看状态: 回调函数有两个形参;fs.statSync(path,[options])同步查看状态: 函数返回一个对象;
//回调函数接收两个参数: err(异常有值|无异常null)、data(对象数据结构:返回当前文件资源的状态对象)
fs.stat('./resource/男娘.MP3',(err,data)=>{
if(err) console.log(err);
console.log(data);
});
//同步获取文件资源信息:——方法返回文件资源对象
// const statFile = fs.statSync('./resource/男娘.MP3');
// console.log("是否文件夹:" + statFile.isFile());
来查看资源的详细信息,返回一个资源对象,常用属性有:
stats.nlink:文件的硬链接数
stats.mode: 文件的权限和类型
stats.ino: 文件的 inode 号
stats.gid: 文件的所有者的组标识符
stats.uid: 文件的所有者的用户标识符
stats.size: 文件的大小,以字节为单位
stats.dev: 文件所在的设备的数字标识符
stats.blocks: 文件占用的文件系统块的数量
stats.atime: 文件的上次访问时间的 Date 对象
stats.mtime: 文件的上次修改时间的 Date 对象
stats.blksize: 用于 I/O 操作的文件系统块的大小
stats.ctime: 文件的上次状态变更时间的 Date 对象
stats.atimeMs: 文件的上次访问时间的时间戳,以毫秒为单位
stats.mtimeMs: 文件的上次修改时间的时间戳,以毫秒为单位
stats.rdev: 如果文件是特殊文件,表示其设备的数字标识符
stats.ctimeMs: 文件的上次状态变更时间的时间戳,以毫秒为单位
stats.birthtime: 文件的创建时间的 Date 对象
stats.birthtimeMs: 文件的创建时间的时间戳,以毫秒为单位
除了这些属性名,fs.Stats 对象还提供了一些方法,用于判断文件或目录的类型:
stats.isFile(): 如果文件是文件,返回 true
stats.isDirectory(): 如果文件是目录,返回 true
stats.isFIFO(): 如果文件是 FIFO,返回 true
stats.isSocket(): 如果文件是套接字,返回 true
stats.isBlockDevice(): 如果文件是块设备,返回 true
stats.isSymbolicLink(): 如果文件是符号链接,返回 true
stats.isCharacterDevice():如果文件是字符设备,返回 true
相对路径|绝对路径:
fs 模块对资源进行操作时,路径的写法有两种:相对路径|绝对路径
- 相对路径: 指相对于某个基准路径的路径,它通常以
.或..开头,表示当前目录或上级目录 - 绝对路径: 指从根目录开始的完整的路径,它通常以
/或盘符开头,表示系统的根目录或分区
//相对路径指相对于某个基准路径的路径,它通常以 . 或 .. 开头,表示当前目录或上级目录
fs.mkdirSync('./newdire', { recursive: true }); //./创建同级
fs.mkdirSync('../newdire', { recursive: true }); //../创建上一级
fs.mkdirSync('../newdire/dire', { recursive: true }); //上一级递归创建多级目录
//绝对路径指从根目录开始的完整的路径,它通常以 / 或 盘符 开头,表示系统的根目录或分区
fs.mkdirSync('D:/newdire0', { recursive: true }); //D盘创建
fs.mkdirSync('C:/newdire0', { recursive: true }); //C盘创建(系统盘可能因为权限不足获取失败!)
fs.mkdirSync('/newdire2', { recursive: true }); //对于不同的操作系统无法固定盘符: / 默认系统盘路径
Node.js中的相对路径:,指的是命令行的工作目录 ,而并非是文件的所在目录:
-
xx.js文件代码中的相对路径,相对的是:node xxx/xxx/xx.jsnode 命令执行所以在的路径! -
所以当命令行的工作目录与文件所在目录不一致时,会出现一些 BUG
dirName|fileName
Node.js 相对路径会因为,node 启动命令而变化,所以对于一些情况会很麻烦,这时候就可以使用:__dirName|__fileName
__dirName|__fileName 是 Node.js 中每一个模块的局部变量 ,每个模块都有自己的 __filename 和__dirName
它表示当前执行脚本所在的目录的绝对路径:
//获取当前文件的绝对路径|+文件名,实际开发中通过用这个来规定路径完善
console.log(__dirname); //C:\Users\wsm17\Desktop\ls\NodeStudy\01FS模块
console.log(__filename); //C:\Users\wsm17\Desktop\ls\NodeStudy\01FS模块\09相对绝对路径.js
Path系统路径/模块:
Node.js中的 path 目录是一个模块,它提供了一些工具函数
用于处理文件与目录的路径,它可以根据不同的操作系统,使用 Windows 或 POSIX 风格的路径
/** Path系统路径模块 */
const fs = require('fs');
const path = require('path');
//获取当前文件的绝对路径|+文件名,实际开发中通过用这个来规定路径完善
console.log(__dirname); //C:\Users\wsm17\Desktop\ls\NodeStudy\01FS模块
console.log(__filename); //C:\Users\wsm17\Desktop\ls\NodeStudy\01FS模块\09相对绝对路径.js
/** 上述__xxXX局部属性获取的路径是 \ 而我们正常使用的是 /
* 虽然不影响正常使用(系统会自动进行处理操作系统识别的路径) 但这样对路径进行拼接就会不可读 */
{
console.log(__dirname+'/wsm'); //C:\Users\wsm17\Desktop\ls\NodeStudy\01FS模块/wsm
}
Path就是专门为了解决这种问题而出现的:内部有很多方法:
/** Path常用函数: */
{
//path.sep 是 path模块中的一个属性,用于表示操作系统的路径分隔符
console.log(path.sep); //不同的操作系统上文件路径的分隔符是不同的: windows是\ 在 Linux|Unix是/
//path.resolve([...paths]) 解析为绝对路径,相对于当前工作目录
console.log(path.resolve(__dirname,'./wsm')); //C:\Users\wsm17\Desktop\ls\NodeStudy\01FS模块\wsm
console.log(path.resolve(__dirname,'../wsm')); //C:\Users\wsm17\Desktop\ls\NodeStudy\wsm
//path.parse(pathString) 将路径解析为对象包含:目录、根目录、基本名称、扩展名等信息
console.log(path.parse('/path/wsm/qq540.txt'));
}
| 方法 | 描述 |
|---|---|
path.join([...paths]) | 连接路径片段,形成规范化路径。 |
path.resolve([...paths]) | 解析为绝对路径,相对于当前工作目录。 |
path.parse(pathString) | 将路径解析为对象,包含目录、根目录、基本名称、扩展名等信息。 |
path.basename(path[, ext]) | 返回文件名部分,可去除指定扩展名。 |
path.dirname(path) | 返回目录名。 |
path.extname(path) | 返回扩展名。 |
HTTP 网络协议模块
Node.js 中最重要的一个模块,使node可以实现服务器的效果,使JS可以完成后端功能,而这需要掌握了解一些网络知识,下面简单介绍一下:
HTTP 协议
HTTP 是超文本传输协议,也就是HyperText Transfer Protocol,是一种基于TCP/IP的应用层通信协议,它可以拆成三个部分:协议、传输、超文本
-
超文本: 在互联网早期的时候只是简单的字符文字,现在「文本」的涵义已经可以扩展为图片、视频、压缩包等
「超文本」就是超越了普通文本的文本,文字、图片、视频等的混合体,最关键有超链接,能从一个超文本跳转到另外一个超文本
HTML 就是最常见的超文本,它本身只是纯文字文件,但内部用很多标签定义了图片、视频等的链接,经过浏览器解释,呈现的就是有画面的网页了
-
传输: 字面意思,就是把数据从 A💻 点搬到 B🖥 点,或者从 B🖥 点 搬到 A💻 点,HTTP 协议是一个双向协议
-
协议: 指的是一种约定,在生活中我们也能随处可见「协议」,例如:刚毕业时会签一个「三方协议」、找房子时会签一个「租房协议」
HTTP协议就是浏览器和服务器之间的互相通信的规则:
- 客户端:用来向服务器发送数据,可以被称之为**
request请求报文**
- 客户端:用来向服务器发送数据,可以被称之为**
-
服务端:向客户端返回数据,可以被称之为**
response响应报文**报文:可以简单理解为就是一堆字符串
注意: HTTP 并不仅仅从互联网服务器传输超文本到本地浏览器协议,HTTP也可以是==「服务器🖥< – >服务器🖥」==
一般为了方便监听我们需要一些工具:Fidder 安装在客户端的一个服务可以监听所有的请求~、 浏览器+F12开发者模式
HTTP 请求报文
HTTP请求报文由三部分组成:请求行、请求头、空行、请求体
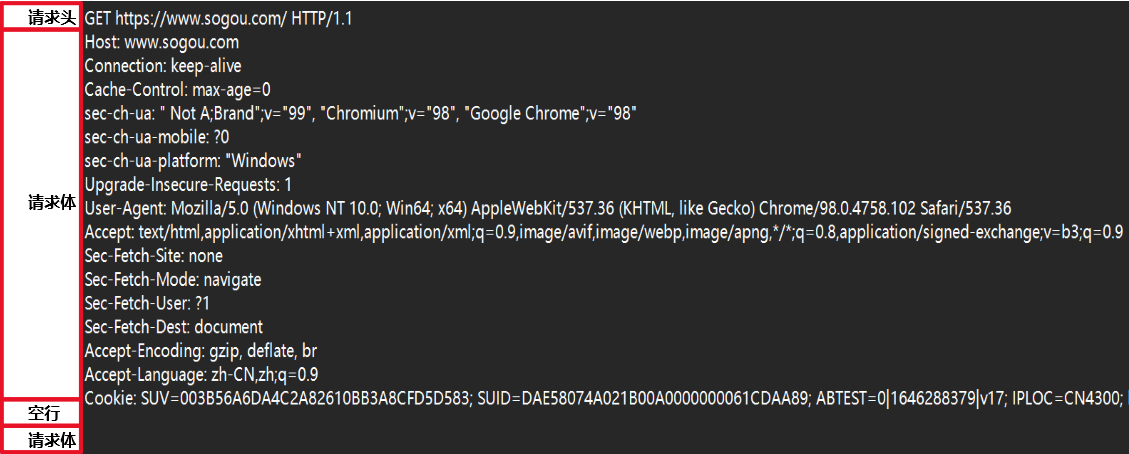
请求行:
请求行: GET https://www.sogou.com/ HTTP/1.1 由: 请求方法 请求URL 请求版本号
-
请求方法: 指定客户端希望服务器对资源执行的操作,常见的请求方法:
GET POST PUT DELETE ... -
请求 URL: 标识请求的资源,
https://www.sogou.com/由:协议、域名、端口、资源路径、参数路径...组成https😕/ search.jd.com : 443 /search ?keyword=oneplus&psort=3 协议名😕/主机名:端口号 资源路径 查询字符串
协议名
scheme: 指定访问资源时要使用的协议,例如http、https、ftp等主机名
host: 指定服务器的主机名或 IP 地址,通常情况下会使用域名代替端口号
port: 指定服务器的端口号,如果未指定则使用协议的默认端口资源路径
path: 指定资源在服务器上的路径,用于定位具体的资源地址查询字符串
query: 包含了请求参数,通常用于向服务器传递额外的信息,服务器判断返回相应的结果 -
请求版本号: 指定所使用的 HTTP 协议版本,
HTTP/1.0,HTTP/1.1,HTTP/2.0等- HTTP/1.0: 于1996年发布,该版本使用简单的请求响应模型,并通过
Connection: keep-alive头部支持持久连接 - HTTP/1.1: 于1999年发布,是目前广泛使用的版本,它引入了持久连接的默认支持,允许多个请求和响应在同一连接上复用HTTP/1.1 还引入了一些其他特性,如管道(pipelining)、块传输编码(chunked transfer encoding)、缓存控制等
- HTTP/2: 于2015年发布,旨在提高性能,它支持多路复用Multiplexing,允许多个请求和响应在同一连接上同时传输,避免了头阻塞,HTTP/2 还使用帧(frames)来传输数据,提高了数据的传输效率
- HTTP/3: 于2020年发布。HTTP/3 采用了基于 UDP 的传输层协议 QUIC
Quick UDP Internet Connections减少连接的时延
- HTTP/1.0: 于1996年发布,该版本使用简单的请求响应模型,并通过
请求头:
HTTP 请求头(HTTP Request Headers)是包含在客户端向服务器发送的 HTTP 请求中的元数据信息
这些头部提供了有关请求的额外信息,帮助服务器理解如何处理请求和提供适当的响应,以下是一些常见的 HTTP 请求头及其作用:
Host: 指定服务器的域名和端口号,标识请求的目标服务器Connection: 控制是否保持持久连接Accept: 指定客户端可以接受的响应内容类型Accept-Language: 指定客户端接受的自然语言、Accept-Encoding: 指定客户端支持的内容编码,如 gzip、deflateAuthorization: 包含用于身份验证的信息,通常在需要访问受保护资源时使用Cookie: 包含客户端的 Cookie 信息,用于保持状态和会话Referer: 表示请求的来源,即引导用户访问当前页面的页面 URLUser-Agent: 标识发起请求的客户端,通常包括浏览器、操作系统Content-Type: 指定请求体的媒体类型,仅在请求中包含主体时使用
请求体:
HTTP 请求体是包含在 HTTP 请求中的可选部分,用于向服务器发送数据
请求体的使用取决于请求的性质和所需传递的数据类型,请求体的内容格式是非常灵活的,可以设置任何内容
- POST 请求中,请求体通常用于提交数据、GET 请求中,数据通常附加在 URL 参数中
表单数据:
Content-Type: application/x-www-form-urlencoded
Content-Type: multipart/form-data
key1=value1&key2=value2
JSON 数据:
Content-Type: application/json
{
"key1": "value1",
"key2": "value2"
}
文件上传(多部分数据):
Content-Type: multipart/form-data; boundary=----WebKitFormBoundary
------WebKitFormBoundary
Content-Disposition: form-data; name="file"; filename="example.txt"
Content-Type: text/plain
... contents of the file ...
------WebKitFormBoundary--
空行:
空行,字面意思,用于区别请求头 请求体
HTTP 响应报文
HTTP 响应报文 和请求报文类似: HTTP 响应报文是由服务器返回给客户端的信息,它包含了有关请求的结果的详细信息
HTTP 响应报文由以下三个部分组成: 响应行、响应头 和 响应体

响应行:
响应行由三部分组成: HTTP/1.1 200 OK HTTP版本号 响应状态码 响应状态消息
-
HTTP 版本号
HTTP-Version: 指定服务器使用的 HTTP 协议版本,常见的:HTTP/1.0、HTTP/1.1、HTTP/2.0、HTTP/3.0 -
响应状态码
Status-Code: 用于表示服务器对请求的处理结果,200成功,404未找到资源,500服务器内部错误…- 1xx: 信息、例如:
100 Continue 服务器已经接收到客户端的部分请求,但还没有最终的响应 - 2xx: 成功、例如:
200 OK 表示成功、201 Created 请求已经被成功处理,并在服务器上创建了新的资源 - 3xx: 重定向、例如:
301 Moved Permanently 表示永久重定向、304 Not Modified 表示资源未被修改,可以使用缓存的版本 - 4xx: 客户端错误、例如:
400 Bad Request 服务器无法理解客户端的请求,请求语法错误、404 Not Found 表示未找到资源 - 5xx: 服务器错误、例如:
500 Internal Server Error 服务器内部错误、502 Bad Gateway 服务器网关代理无效响应
- 1xx: 信息、例如:
-
响应状态消息
Reason-Phrase: 提供对状态码的简要描述,OK表示成功,Not Found表示未找到资,Found表示临时移动状态消息通常是标准的英文短语,用于简要描述与相应状态码相关的情况,为了让开发人员和网络管理员更容易理解服务器对请求的响应结果
响应头:
响应头与请求头类似,HTTP响应头是包含在 HTTP 响应中的元数据信息,提供了关于响应的详细信息
响应头提供有关响应的重要信息,帮助客户端正确处理响应体并执行相应的操作,实际应用中,可以根据需要添加或使用不同的响应头:缓存 安全性 内容解析
这些头部通常位于 HTTP 响应的起始部分,即状态行之后,空行之前,响应头由一个字段名和一个字段值组成,以下是一些常见的HTTP响应头及其作用:
-
Location: 在发生重定向时,指定新的资源位置Location: https://www.example.com/new-location -
Set-Cookie: 响应中设置Cookie,在客户端和服务器之间传递状态信息Set-Cookie: username=JohnDoe;path=/ -
Content-Type: 指定了响应体的媒体类型,告诉客户端如何解析响应体Content-Type: text/html; charset=utf-8 -
Cache-Control: 控制缓存行为,指示响应是否可以被缓存以及缓存的有效期等。Cache-Control: max-age=3600, public -
Content-Length: 指定了响应体的长度(以字节为单位)Content-Length: 1024 -
Server: 指定了响应中使用的服务器软件的信息Server: Apache/2.4.41 (Unix) -
Date: 指定了响应的日期和时间Date: Wed, 01 Dec 2021 12:00:00 GMT -
ETag: 标识资源的唯一标识符,用于支持条件请求ETag: "abc123"
响应体:
响应体与请求体类似,HTTP 响应体是包含在 HTTP 响应中的主体部分,包含了服务器返回给客户端的实际数据
-
响应体的内容和格式,取决于服务器对客户端请求的处理以及服务器返回的资源类型
-
客户端接收到响应体后,根据响应头中的
Content-Type等信息来正确解析和处理响应体的内容 -
Web 开发中,常常使用 JavaScript、CSS、图像等资源作为响应体来构建网页,响应体也可以为空:特别是对于某些重定向或只返回状态码的响应
HTML 文档: Content-Type:text/html
<!DOCTYPE html>
<html>
<head> <title>Example HTML</title> </head>
<body> <h1>Hello, World!</h1> </body>
</html>
JSON 数据: Content-Type:application/json
{ "name": "John Doe", "city": "Example City"}
纯文本数据: Content-Type: text/plain
This is a plain text response.
二进制数据(图片): Content-Type:image/jpeg 二进制数据,通常无法在文本中显示
创建HTTP服务:
Node.js 中的 http 模块是用于创建 HTTP 服务器和客户端的核心模块
通过该模块,你可以轻松地创建一个简单的 HTTP 服务器,处理 HTTP 请求和响应
HTTP模块导入:
const http = require('http'); //require导入HTTP模块: 和FS一样Node.JS使用模块都需要进行导入
创建服务器对象:
http.createServer 函数创建一个服务器对象:方法接受一个回调函数,这个回调函数会在每次有 HTTP 请求时被调用,回调函数接收两个参数
- request: 意为请求,是对请求报文的封装对象,通过request对象可以获得请求报文的数据
- response: 意为响应,是对响应报文的封装对象,通过response对象可以设置响应报文
const server = http.createServer((request, response) => {
response.end('Hello HTTP Server');
});
监听端口, 启动服务:
服务器对象.listen(port,()=>{ 服务启动 }) 函数启动服务,并监听port端口请求
//使用 server服务器对象监听端口,启动服务:
server.listen(5400, () => {
//服务启动成功的描述信息;
console.log('node Server 启动!!');
})
🆗,Node创建本地服务器,并启动端口监听完成:浏览器 http://127.0.0.1:5400/ 就可以请求到了server服务器并获取响应,F12可以更方便查看
HTTP 协议默认端口是 80,HTTPS 协议的默认端口是 443,HTTP 服务开发常用端口有 3000, 8080,8090,9000 等
当服务启动后,更新代码必须重启服务才能生效,监听服务 ctrl + c 停止服务🛑

?注意事项:
一、响应内容中文乱码问题: Node.js HTTP响应默认是UTF-8,但有时候浏览器默认编码格式是ISO-8859-1
所以为了避免,中文乱码,在服务器响应的时候,可以通过response.setHeader指定响应的编码格式
response.setHeader('content-type', 'text/html;charset=utf-8');
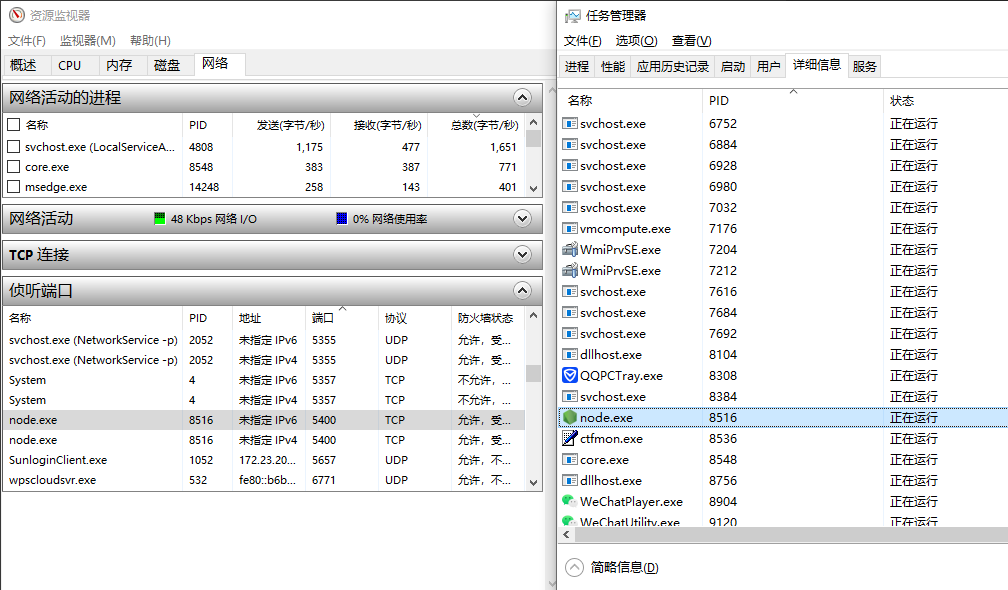
二、服务监听端口启动报错: Error: listen EADDRINUSE: address already in use :::XXX|错误:监听EADDRINUSE:地址已在使用:::XXX
当前server服务器对象listen监听的端口已经被占用… 如何解决(????
-
NodeJS HTTP服务直接修改更换一个端口来监听服务
-
找到本机占用的端口,停止,重启服务,Windows 查询端口服务…
资源资源监视器-网络-侦听端口找到占用端口的程序|PID,到任务管理器-详细信息PID查询对应服务进行关闭
获取HTTP请求报文
http.createServer 函数创建一个服务器对象,方法接受一个回调函数,回调函数接收两个参数: request|response
- request对象可以获取请求报文常用属性|方法、response对象可以设置响应报文
请求头|行|体
request获取请求行|请求头
request.url: 获取请求的 URLrequest.method: 获取请求的 HTTP 方法request.httpVersion: 获取请求的 HTTP 版本request.headers.xxxx: 获取请求头的对象,可以通过属性名获取特定的请求头值
//导入HTTP模块
const http = require('http');
//创建服务器对象
const server = http.createServer((request, response) => {
//request获取请求行
console.log(request.url); //获取请求的 URL
console.log(request.method); //获取请求方法: GET、POST...
console.log(request.httpVersion); //获取请求的HTTP版本: 1.1 2.0
//request获取请求头:
console.log(request.headers); //headers是对象结构属性|值形式展示
console.log(request.headers.host);
console.log(request.headers.connection); //headers.connection 获取对应的属性数值
//response设置响应报文
response.setHeader('content-type', 'text/html;charset=utf-8');
response.end('Hello HTTP Server 服务响应!');
});
//创建监听端口,启动服务:
server.listen(5400, () => {
console.log('node Server 启动!!');
})
request获取请求体:
Node.js 中获取 HTTP 请求体的方式多样化:Web 框架、HTTP 服务器、内置HTTP模块
内置的http模块:可以通过req请求对象监听 data | end 事件获取请求体
-
request.on('data', function(chunk){})监听data事件,当有请求数据可用时,会触发回调函数,将数据块附加到data变量上每当接收到请求体数据的时候,都会触发
data事件,事件可以被多次触发,每次触发时提供一个数据块chunk设计理由:👇-
HTTP 请求体可能很大,不适合一次性将所有数据加载到内存中处理,因此采用分块传输的方式
-
data事件允许你在接收到每个数据块时执行相应的处理,而不必等到整个请求体接收完毕
-
-
request.on('end', function(){});监听end事件,当请求体的所有数据都接收完毕时,触发回调函数,获取完整的请求体;
/** 获取HTTP请求报文 */
const http = require('http');
/** request获取请求体:
* 设置参数body接收请求体
* 绑定data事件:因为请求体大小不确定避免内存过大溢出,分块传输多次监听
* 绑定end 事件:当请求体的所有数据都接收完毕时,触发回调函数,获取完整的请求体 */
const server = http.createServer((request, response) => {
let body = '';
request.on('data', chunk => { body += chunk });
request.on('end', () => { console.log(body); });
//response设置响应报文
response.setHeader('content-type', 'text/html;charset=utf-8');
response.end('Hello HTTP Server 服务响应!');
});
//使用 server服务器对象监听端口,启动服务:
server.listen(5400, () => {
console.log('node Server 启动!!');
})
????注意事项:
- 如果需要测试就不能依靠浏览器了,浏览器的URL直接回车大部分都是
GET请求而GET没有请求体,建议使用:HTML、Postman测试
Web Http请求的形式有很多:
application/x-www-form-urlencoded格式的请求体,通常来自 HTML 表单提交,可以使用内置的querystring模块来解析请求体数据application/json格式的请求体,通常是通过 AJAX 或其他客户端发送 JSON 数据,可以使用JSON.parse解析 JSON 数据- 所以,原生的HTTP接受响应会有很多不方便的操作:
如何处理中文乱码...目前了解即可👍
请求路径|查询字符串
🆗,上面了解了如何从请求报文种获取,请求行|头|体,就可以根据不同的请求体,来做出很多的响应,而 GET请求并不方便携带请求体:
所以,我们还可以从请求路径上获取:路径信息|参数字符串来处理多种响应: 如下我们常见的Demo:
http://127.0.0.1:5400/login客户端请求登录页面http://127.0.0.1:5400/register客户端请求注册页面http://127.0.0.1:5400/register?name=xxx&password=xxx客户端请求带参注册请求
NodeJS HTTP解析请求路径——方式一: 导入url模块解析,简单介绍一下url模块…
url.parse('url') 方法可以将一个 URL 字符串解析成一个 URL 对象,对象包含了 URL 的各个组成部分
url.parse('url',true) :当第二个参数为 true 时,url.parse() 方法会将查询字符串解析为一个对象,查询参数的键值对
/** 模块导入 */
const http = require('http');
const url = require('url');
/** HTTP解析请求路径: url.parse()方法可以将一个URL字符串解析成一个对象,包含了URL的各个组成部分 */
const server = http.createServer((request, response) => {
response.setHeader('content-type', 'text/html;charset=utf-8'); //解决中文乱码;
let res = url.parse(request.url, true);
console.log(res.pathname) //获取请求路径
console.log(res.query) //获取请求参数对象
if (res.pathname == '/login') {
response.end('login登录页面');
} else if (res.pathname == '/register') {
if (Object.keys(res.query).length !== 0) response.end(JSON.stringify(res.query));
else response.end('register注册页面');
} else { response.end('未知路径请求'); }
});
//使用 server服务器对象监听端口,启动服务:
server.listen(5400, () => { console.log('node Server 启动!!'); })
NodeJS HTTP解析请求路径——方式二: 实例化URL的对象解析;
new URL() 方法在浏览器环境和 Node.js 环境中的行为可能有一些差异,具体取决于具体的使用场景
/** 实例化URL的对象解析 */
{
// URL 字符串
const urlString = 'https://www.example.com:8080/path?query=123#fragment';
// 使用 url.parse() 方法解析 URL 字符串并生成 URL 对象
const parsedUrl = new URL(urlString);
// 输出 URL 对象的属性
console.log('hash:', parsedUrl.hash); // '#fragment'
console.log('protocol:', parsedUrl.protocol); // 'https:'
console.log('port:', parsedUrl.port); // '8080'
console.log('host:', parsedUrl.host); // 'www.example.com:8080'
console.log('hostname:', parsedUrl.hostname); // 'www.example.com'
console.log('pathname:', parsedUrl.pathname); // '/path'
console.log('search:', parsedUrl.search); // '?query=123'
console.log('searchParams:', parsedUrl.searchParams); // URLSearchParams{ 'query' => '123' } 对象
}
设置HTTP响应报文
http.createServer 函数创建一个服务器对象,方法接受一个回调函数,回调函数接收两个参数: request|response
- request对象可以获取请求报文常用属性|方法、response对象可以设置响应报文
设置响应头|行|体
在Node.js 中,当你使用 http 模块创建一个服务器时,如果不显式设置响应头,Node会提供一组默认的响应头,Node也提供属性根据需求自定义
res.statusCode获取或设置 HTTP 响应的状态码,必须数字res.statusMessage获取或设置 HTTP 响应的状态消息,必须英文res.getHeader(name)获取指定响应头的值,实例:res.getHeader('Content-Type');res.setHeader(name, value)设置响应头的值,可以使用该方法多次设置多个响应头,示例:res.setHeader('Content-Type', 'text/plain');
/** HTTP 设置响应报文 */
const server = http.createServer((request, response) => {
//设置响应头|行:
response.statusCode = 540;
response.statusMessage = 'WSM'; //随机设置响应:实际开发中Code|Message相互匹配
response.setHeader('content-type', 'text/html;charset=utf-8'); //解决中文乱码;
//设置响应体:
response.write('writerOne');
response.write('writerTwo'); //向响应体中写入数据块
response.end('未知路径请求'); //每个请求结束响应,将响应发送给客户端,必须end 则请求未响应;
});
最终响应体: 会将write 和 end 的响应内容进行拼接合并,全部响应回客户端
res.write(chunk[, encoding][, callback])向响应体中写入数据块res.end([data][, encoding][, callback])结束响应过程,将响应发送给客户端,可携带最终的响应数据
HTTP响应资源类型:
对于一个web项目,通常分为:前端——后端通过HTTP协议:前端发送请求——后端接受请求响应资源——前端接受响应页面渲染:
请求的类型方式有很多,所以响应的资源也有很多类型:HTML、CSS、JS、图片|视频... 浏览器改如何知道,后端响应的是什么类型呢?
HTTP响应中的资源类型主要通过Content-Type标头字段来指定客户端所接收到的数据是什么类型的
以下常见的HTTP响应资源类型,这是 MIME Multipurpose Internet Mail Extensions 类型:
-
text/plain: 纯文本
-
image/gif: GIF图像
-
image/png: PNG图像
-
image/jpeg: JPEG图像
-
text/html: HTML文档
-
video/mp4: MP4视频文件
-
application/xml: XML格式
-
audio/mpeg: MP3音频文件
-
application/json: JSON格式
-
text/css: Cascading Style Sheets (CSS)
-
application/pdf: Adobe Portable Document Format (PDF)
-
对于未知的资源类型,浏览器在遇到该情况自身存在资源自动检测:文件类型进行设置展示;
或选择
application/octet-stream类型,浏览器会对响应体内容进行独立存储,也就是我们常见的下载效果
响应HTML报文信息:
/** HTTP 设置响应资源报文 */
const server = http.createServer((request, response) => {
response.setHeader('Content-Type', 'text/html;charset=utf-8'); //并设置资源的编码格式;
response.write(`
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Node.js HTTP Server</title>
</head>`
);
response.end(`
<body>
<h1>Hello, Node.js!</h1>
<script>
// 嵌入的 JavaScript 代码
alert('This is JavaScript running on the server!');
</script>
</body>
</html>`
);
});
-
HTML中通常默认指定文件编码格式:
<meta charset="UTF-8">😕但 ,Content-Type设置编码格式优先级更高 -
而,
CSS、JS...等资源中的编码格式,则会默认根据当前依附的HTML网页的编码格式而设置; -
实际开发中,文件响应通常使用:
fs进行读取响应,提高代码可读性;
HTTP 模块搭建资源服务器
这个地方了解即可,个人总结存在差异,请指出,现在大部分的框架已经实现了这一块的功能,所以实际开发接触不多😬
Demo资源:
以下是一个简单的HTML页面:
包含一个"Hello World"的文本,使用CSS设置字体并居中,JavaScript实现点击变色效果的例子:initDemo.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Hello World Page</title>
<style>
body {
margin: 0;
height: 100vh;
display: flex;
font-size: 120px;
align-items: center;
justify-content: center;
font-family: Arial, sans-serif; /* 设置字体 */ }
#helloText { cursor: pointer; /* 添加光标指示可点击 */ }
</style>
</head>
<body>
<div id="helloText">Hello World!</div>
<script>
// JavaScript代码,点击文本时变色
document.getElementById('helloText').addEventListener('click', function() {
var randomColor = getRandomColor();
this.style.color = randomColor;
});
// 随机创建文本颜色
function getRandomColor() {
var color = '#';
var letters = '0123456789ABCDEF';
for (var i = 0; i < 6; i++) { color += letters[Math.floor(Math.random() * 16)]; }
return color;
}
</script>
</body>
</html>
文件资源服务器
拆分上述:initDemo.HTML
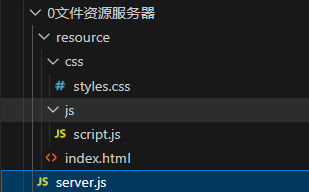
响应页面举例升级: 一个响应报文页面可以由很复杂的文本内容组成,为了方便读取|响应,可以通过FS模块 读取响应
且,一个响应报文页面HTML 由多个资源文件组成:html、css、js、img,通常我们都是 FS 读取HTML文件响应,HTML内部调用资源
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Hello World Page</title>
<link rel="stylesheet" href="css/styles.css">
</head>
<body>
<div id="helloText">Hello World!</div>
<script src="js/script.js" ></script>
</body>
</html>
通过FS模块:
/** 设置HTTP响应报文 */
const fs = require('fs');
const http = require('http');
/** HTTP 设置响应资源报文 */
const server = http.createServer((request, response) => {
response.setHeader('Content-Type', 'text/html;charset=utf-8');
let html = fs.readFileSync(__dirname+'/resource/index.html');
response.end(html);
});
//使用 server服务器对象监听端口,启动服务:
server.listen(5400, () => { console.log('node Server 启动!!'); })
这里通过,FS读取 index.html 响应页面,但有一个问题:突然发现页面的 CSS JS 失效了?
- 经过浏览器
F12排查——原来,是因为服务器的响应固定了 index.html 虽然有CSS | JS的请求,但固定的响应的也都是html
文件资源服务器基础
上述响应存在BUG: 实际开发中我们需要根据请求路径而响应对应的文件,而文件中的资源文件也需要正确响应;
新增需求: http://127.0.0.1:5400/index 正确响应页面及样式资源,非法路径则404
/** 设置HTTP响应报文 */
const fs = require('fs');
const http = require('http');
/** HTTP 设置响应资源报文 */
const server = http.createServer((request, response) => {
//获取请求URL 解析来判断响应页面资源;
let { pathname } = new URL(request.url,'http://127.0.0.1');
if(pathname === '/index' ){
let h5 = fs.readFileSync(__dirname+'/resource/index.html');
response.end(h5);
}else if(pathname === '/js/script.js'){
let js = fs.readFileSync(__dirname+'/resource/js/script.js');
response.end(js);
}else if(pathname === '/css/styles.css'){
let css = fs.readFileSync(__dirname+'/resource/css/styles.css');
response.end(css);
}else{ response.statusCode = 404; response.end('<H1> 404 NOT FOUND </H1>'); }
});
//使用 server服务器对象监听端口,启动服务:
server.listen(5400, () => { console.log('node Server 启动!!'); });
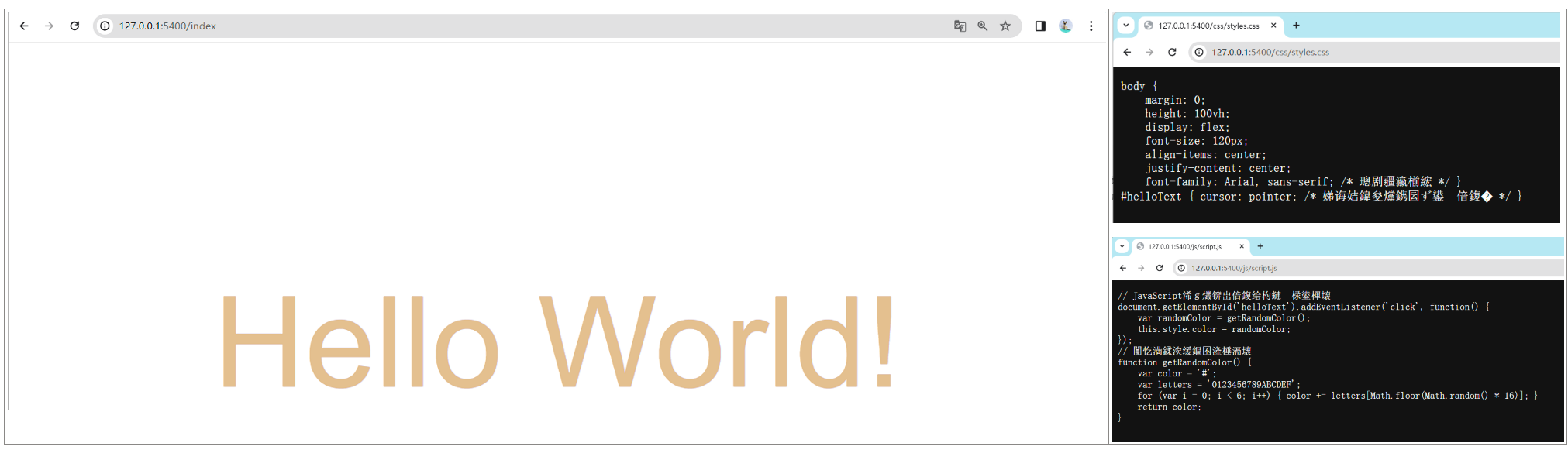
浏览器请求——服务器未匹配的路径则:404 NOT FOUND
文件资源服务器进阶
上述的写法虽然可以实现但是实在是太笨了,如果服务器有千百万不同的文件类型,这对开发|服务器效率性能压力太大了!
??server.js 代码升级:
/** 设置HTTP响应报文 */
const fs = require('fs');
const path = require('path');
const http = require('http');
let mimes = {
html: 'text/html',
css: 'text/css',
png: 'image/png',
mp4: 'video/mp4',
gif: 'image/gif',
jpg: 'image/jpeg',
mp3: 'audio/mpeg',
js: 'text/javascript',
json: 'application/json' } //变量: 常见的文件响应类型,目前的浏览器都有自动识别资源类型的功能了
/** HTTP 设置响应资源报文 */
const server = http.createServer((request, response) => {
//获取请求URL 解析来判断响应页面资源 变量: 服务器资源路径
let { pathname } = new URL(request.url,'http://127.0.0.1');
let filePath = __dirname + '/resource'+pathname;
//读取路径文件 fs 异步 API 是否存在,给予异常捕获
fs.readFile(filePath, (err, data) => {
if(err){ //判断错误的代号
response.setHeader('content-type','text/html;charset=utf-8');
switch(err.code){
case 'ENOENT':
response.statusCode = 404;
return response.end('<h1>404 Not Found</h1>');
case 'EPERM':
response.statusCode = 403;
return response.end('<h1>403 Forbidden</h1>');
default:
response.statusCode = 500;
return response.end('<h1>Internal Server Error</h1>'); }
}
let ext = path.extname(filePath).slice(1); //获取文件的后缀名
let type = mimes[ext]; //获取对应的类型
if(type){
if(ext === 'html'){ response.setHeader('content-type', type + ';charset=utf-8');
}else{ response.setHeader('content-type', type); }
}else{
response.setHeader('content-type', 'application/octet-stream'); //没有匹配到
}
//响应文件内容
response.end(data);
});
});
//使用 server服务器对象监听端口,启动服务:
server.listen(5400, () => { console.log('node Server 启动!!'); });
实际开发,几乎不会设计到服务器的开发,此处了解即可~~
扩展:网页中的 URL
网页中的 URL 主要分为两大类:相对路径与绝对路径
-
绝对路径: 可靠性强,而且相对容易理解,在项目中运用较多
形式 特点 http://wsm.com/Demo直接向目标资源发送请求:某个网站的外链 //wsm.com/Demo 与页面 URL 的协议拼接形成完整 URL 再发送请求 /web 与页面 URL 的协议、主机名、端口拼接形成完整 URL 再发送请求 -
相对路径: 在发送请求时,需要与当前页面 URL 路径进行 计算 ,得到完整 URL 后,再发送请求,学习阶 段用的较多
例如当前网页 url 为:
http://www.wsm.com/course/index.html形式 最终的 URL ./css/app.css http://www.wsm.com/course/css/app.cssjs/app.js http://www.wsm.com/course/js/app.js…/img/logo.png http://www.wsm.com/img/logo.png
如下Demo案例: HTML文件,通过VsCode+插件Live-Server工具可以快速部署前端页面——F12 查看浏览器拼接路径资源
<body>
<!-- 绝对路径 -->
<a href="https://www.baidu.com">百度</a>
<a href="//jd.com">京东</a>
<a href="/search">搜索</a>
<hr>
<!-- 相对路径 -->
<a href="./css/app.css">访问CSS</a>
<a href="js/app.js">访问JS</a>
<a href="../img/logo.png">访问图片</a>
<a href="../../img/logo.png">访问图片</a>
</body>
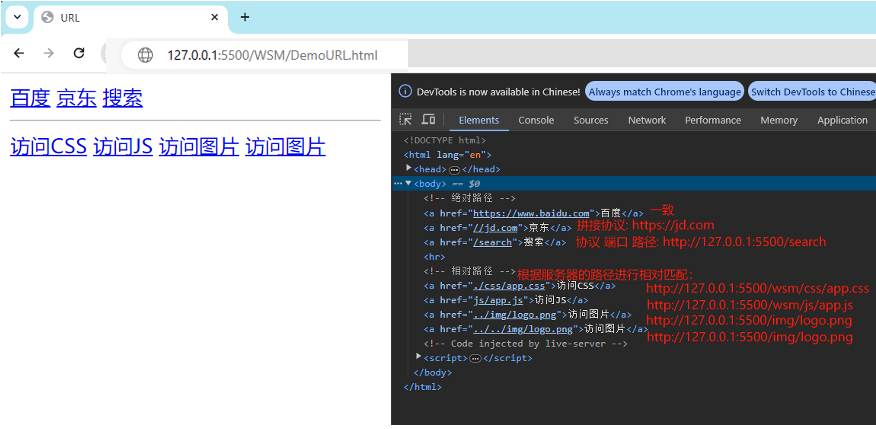
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 博特激光:紫外激光打标机在玻璃行业的应用
- (每日持续更新)jdk api之Console基础、应用、实战
- 基于谷歌Gemini开发一个图片识别网站:我知道你的宠物在想什么!
- Linux CentOS官方文档之U盘安装
- Swift 周报 第四十二期
- iOS UIDatePicker和NSDateFormatter强制设为24小时制显示
- 技术篇,批量提取PDF文档中的信息到Excel,一招搞定!
- AutoSAR(基础入门篇)3.3-Autosar中RTE的数据一致性与Interface接口
- 基于ssm点餐平台系统论文
- Java学习笔记3:Java中 “+” 的使用