机器学习之特征工程
一、背景
什么是特征?在机器学习中,特征是一个现象的个别可测量的属性或特征。让我们观察一束阳光,直接看的话,它是白光,但是我们使用三菱镜,它就是七种颜色的光。所以,选取的事物的特征不同,我们观测的结果就会不一样。

二、定义
- 特征工程(Feature Engineering)特征工程是将原始数据转化成更好的表达问题本质的特征的过程,使得将这些特征运用到预测模型中能提高对不可见数据的模型预测精度。
- 特征工程简单讲就是发现对因变量y有明显影响作用的特征,通常称自变量x为特征,特征工程的目的是发现重要特征。
- 如何能够分解和聚合原始数据,以更好的表达问题的本质?这是做特征工程的目的。
三、特征工程的流程
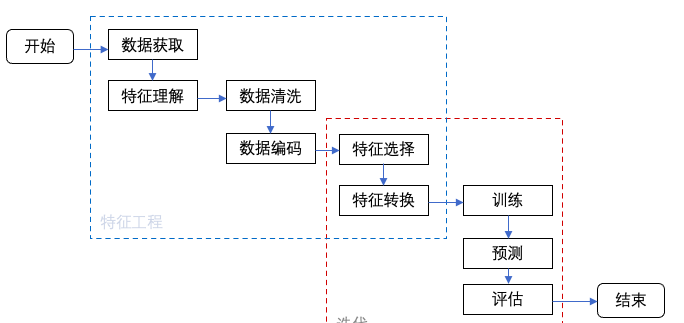
?四、特征设计原理
新特征设计应与目标高度相关,要考虑的问题:
- 这个特征是否对目标有实际意义?
- 如果有用,这个特征重要性如何?
- 这个特征的信息是否在其他特征上体现过?
新构建特征验证其有效性要考虑的问题:
- 需要领域知识、直觉、行业经验以及数学知识综合性考量特征的有效性,防止胡乱构造没有意义的特征。
- 要反复与模型进行迭代验证其是否对模型有正向促进作用。
- 或者进行特征选择判定新构建特征的重要性来衡量其有效性。
五、特征转换
通常情况下,合理的数据变换能帮助现有模型更好的理解样本中的信息。比如年龄特征,收入特征等数据参差不齐,需要做离散化,分为老,中,幼,高收入,中等收入,低收入等。
连续数据离散化
有些时候我们需要对数据进行粗粒度、细粒度划分,以便模型更好的学习到特征的信息,比如:
- 粗粒度划分(连续数据离散化):将年龄段0~100岁的连续数据进行粗粒度处理,也可称为二值化或离散化或分桶法
- 细粒度划分:在文本挖掘中,往往将段落或句子细分具体到一个词语或者字,这个过程称为细粒度划分
方法
- 特征二值化
设定一个划分的阈值,当数值大于设定的阈值时,就赋值为1;反之赋值为0。典型例子:划分年龄段
- 无监督离散化
分箱法:等宽(宽度)分箱法、等频(频数)分箱法 聚类划分:使用聚类算法将数据聚成几类,每一个类为一个划分
典型例子
年龄、收入
优缺点
优点:(1)降低数据的复杂性 (2)可在一定程度上消除多余的噪声
离散数据编码化
很多算法模型不能直接处理字符串数据,因此需要将类别型数据转换成数值型数据
方法
- 序号编码
通常用来处理类别间具有大小关系的数据,比如成绩(高中低)
- 独热编码(One-hot Encoding)
通常用于处理类别间不具有大小关系的特征,比如血型(A型血、B型血、AB型血、O型血), 独热编码会把血型变成一个稀疏向量,A型血表示为(1,0,0,0),B型血表示为(0,1,0,0), AB型血表示为(0,0,1,0),O型血表示为(0,0,0,1)
- 二进制编码
二进制编码主要分为两步,先用序号编码给每个类别赋予一个类别ID,然后将类别ID对应的二进制编码作为结果。 以A、B、AB、O血型为例,A型血表示为00,B型血表示为01, AB型血表示为10,O型血表示为11
优缺点
缺点:有些模型不支持离散字符串数据,离散编码便于模型学习
函数变换法
方法 简单常用的函数变换法(一般针对于连续数据):平方(小数值—>大数值)、开平方(大数值—>小数值)、指数、对数、差分
典型例子
对时间序列数据进行差分
数据不呈正态分布时可运用
当前特征数据不利于被模型捕获时
优缺点
优点:
- 将不具有正态分布的数据变换成具有正态分布的数据
- 对于时间序列分析,有时简单的对数变换和差分运算就可以将非平稳序列转换成平稳序列
.算术运算构造法
根据实际情况需要,结合与目标相关性预期较高的情况下,由原始特征进行算数运算而形成新的特征。
解读概念为几种情况:
- 原始单一特征进行算术运算:类似于无量纲那样处理,比如:X/max(X), X+10等
- 特征之间进行算术运算:X(featureA)/X(featureB),X(featureA)-X(featureB)等
自由发挥
在特征构造这一块是没有什么明文规定的方法,特征构造更多的是结合实际情况,有针对性的构造与目标高度相关的特征,只要构造的新特征能够解释模型和对模型具有促进作用,都可以作为新指标新特征。
六、特征选择
从哪些方面来选择特征呢?
当数据处理好之后,我们需要选择有意义的特征输入机器学习的模型进行训练,通常来说要从两个方面考虑来选择特征,如下:
1、特征是否发散
如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
2、特征与目标的相关性
这点比较显见,与目标相关性高的特征,应当优先选择。
区别:特征与特征之间相关性高的,应当优先去除掉其中一个特征,因为它们是替代品。
为什么要进行特征选择?
- 减轻维数灾难问题; 2. 降低学习任务的难度
处理高维数据的两大主流技术
特征选择和降维
特征选择有哪些方法呢?
- Filter 过滤法
- Wrapper 包装法
- Embedded 嵌入法
七、总结
特征工程做的好,后期的模型调参更容易甚至不用调参,模型的稳定性,可解释性也要更好。如果特征工程做得不好,模型评估怎么调参都调不到理想的效果,那么就需要大量消耗时间继续重复处理、筛选特征,直到模型达到理想的效果。
参考:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 前缀和和差分
- ARM AArch64的虚拟化(virtualization)详解(上)
- PFA试剂瓶进口氟塑料取样瓶有哪几种口径?
- 网站被篡改怎么办,如何进行有效的防护
- 详解Med-PaLM 2,基于PaLM 2的专家级医疗问答大语言模型
- 多个描述文件对开发者证书有影响吗
- flutter中使用有状态组件时,初始化状态注意事项
- LeetCode 1. 两数之和
- 2025年考研数学备考和复习的五个建议(适用于数学一二三)
- C++创建窗口程序