强化学习的数学原理学习笔记 - Actor-Critic
文章目录
本系列文章介绍强化学习基础知识与经典算法原理,大部分内容来自西湖大学赵世钰老师的强化学习的数学原理课程(参考资料1),并参考了部分参考资料2、3的内容进行补充。
系列博文索引:
- 强化学习的数学原理学习笔记 - RL基础知识
- 强化学习的数学原理学习笔记 - 基于模型(Model-based)
- 强化学习的数学原理学习笔记 - 蒙特卡洛方法(Monte Carlo)
- 强化学习的数学原理学习笔记 - 时序差分学习(Temporal Difference)
- 强化学习的数学原理学习笔记 - 值函数近似(Value Function Approximation)
- 强化学习的数学原理学习笔记 - 策略梯度(Policy Gradient)
- 强化学习的数学原理学习笔记 - Actor-Critic
参考资料:
*注:【】内文字为个人想法,不一定准确
概览:RL方法分类
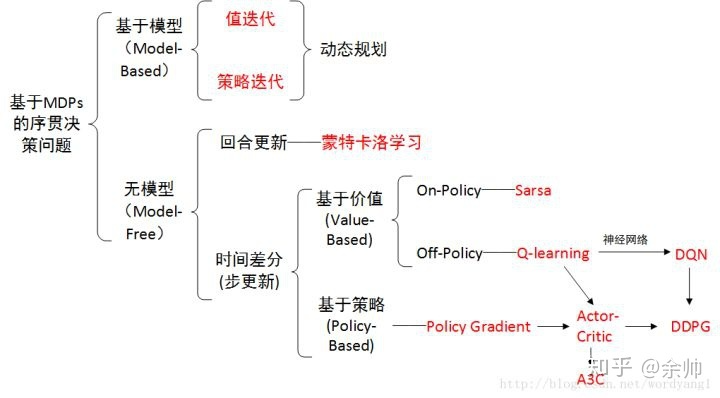
*图源:https://zhuanlan.zhihu.com/p/36494307
Actor-Critic
Actor-Critic属于策略梯度(PG)方法,实际上是将值函数近似和策略梯度方法进行了结合。
- Actor:策略更新,Actor用来执行动作与环境交互
- Critic:策略评估 / 值估计,Critic用来评估Actor的好坏
Basic actor-critic / QAC
与策略梯度算法对应,Actor即为策略梯度算法中执行策略更新的部分(通过更新参数 θ \theta θ),而Critic是估计 q t ( s t , a t ) q_t(s_t,a_t) qt?(st?,at?)的算法。QAC(Q actor-critic)是最简单的actor-critic算法,也是一种on-policy方法。
QAC vs. REINFOCE:估计 q t ( s t , a t ) q_t(s_t,a_t) qt?(st?,at?)的方法不同
- REINFORCE:蒙特卡洛(MC)
- QAC:时序差分(TD)
QAC算法:【简单理解:QAC = Sarsa with function estimation + Policy Gradient】
- Critic(值更新 / 策略评估):采用Sarsa with function estimation的方法估计
q
t
(
s
t
,
a
t
)
q_t(s_t,a_t)
qt?(st?,at?)
- w t + 1 = w t + α w [ r t + 1 + γ q ( s t + 1 , a t + 1 , w t ) ? q ( s t , a t , w t ) ] ? w q ( s t , a t , w t ) w_{t+1} = w_t + \alpha_w [r_{t+1} + \gamma {q}(s_{t+1}, a_{t+1}, w_t) - {\color{blue} {q}(s_t, a_t, w_t)}] {\color{blue} \nabla_w {q}(s_t, a_t, w_t)} wt+1?=wt?+αw?[rt+1?+γq(st+1?,at+1?,wt?)?q(st?,at?,wt?)]?w?q(st?,at?,wt?)
- Actor(策略更新 / 策略提升):采用策略梯度(PG)的方法(同REINFROCE)更新策略
- θ t + 1 = θ t + α θ ? θ ln ? π ( a t ∣ s t , θ t ) q t ( s t , a t , w t + 1 ) \theta_{t+1} = \theta_t + \alpha_\theta \nabla_\theta \ln\pi (a_t|s_t, \theta_t) {\color{blue} q_t(s_t, a_t, w_{t+1}) } θt+1?=θt?+αθ??θ?lnπ(at?∣st?,θt?)qt?(st?,at?,wt+1?)
🟦A2C (Advantage actor-critic)
A2C的基本思想:在QAC中引入baseline来减少估计的方差(variance)。
理论基础:引入baseline b ( S ) b(S) b(S)后,策略梯度(期望)不会发生改变,但其方差会减小(推导略),即 ? θ J ( θ ) = E S ~ η , A ~ π [ ? θ ln ? π ( A ∣ S , θ ) q π ( S , A ) ] = E S ~ η , A ~ π [ ? θ ln ? π ( A ∣ S , θ ) ( q π ( S , A ) ? b ( S ) ) ] \nabla_\theta J (\theta) = \mathbb{E}_{S\sim\eta,A\sim\pi} [\nabla_\theta \ln\pi (A|S, \theta) q_\pi(S, A) ] = \mathbb{E}_{S\sim\eta,A\sim\pi} [\nabla_\theta \ln\pi (A|S, \theta) (q_\pi(S, A) {\color{blue} - b(S))} ] ?θ?J(θ)=ES~η,A~π?[?θ?lnπ(A∣S,θ)qπ?(S,A)]=ES~η,A~π?[?θ?lnπ(A∣S,θ)(qπ?(S,A)?b(S))] 其中, b ( S ) b(S) b(S)为关于 S S S的标量函数。
使得方差最小的最优baseline形式为: b ? ( s ) = E A ~ π [ ∥ ? θ ln ? π ( A ∣ s , θ t ) ∥ 2 q ( S , A ) ] E A ~ π [ ∥ ? θ ln ? π ( A ∣ s , θ t ) ∥ 2 ] b^*(s) = \frac{ \mathbb{E}_{A\sim\pi} [ {\color{blue} \| \nabla_\theta \ln\pi (A|s, \theta_t) \|^2} {\color{red} q(S,A)} ] }{ \mathbb{E}_{A\sim\pi} [ {\color{blue} \| \nabla_\theta \ln\pi (A|s, \theta_t) \|^2} ] } b?(s)=EA~π?[∥?θ?lnπ(A∣s,θt?)∥2]EA~π?[∥?θ?lnπ(A∣s,θt?)∥2q(S,A)]?
但直接应用此式过于复杂,因此在实际中选择次优baseline,去掉权重项 ∥ ? θ ln ? π ( A ∣ s , θ t ) ∥ 2 \| \nabla_\theta \ln\pi (A|s, \theta_t) \|^2 ∥?θ?lnπ(A∣s,θt?)∥2,有: b ( s ) = E A ~ π [ q ( S , A ) ] = v π ( s ) b(s) = \mathbb{E}_{A\sim\pi} [q(S,A)] = v_\pi(s) b(s)=EA~π?[q(S,A)]=vπ?(s)
即将 s s s的状态值作为baseline。
在actor(策略更新)中引入状态值作为baseline,即:
θ
t
+
1
=
θ
t
+
α
E
[
?
θ
ln
?
π
(
A
∣
S
,
θ
t
)
[
q
π
(
S
,
A
)
?
v
π
(
S
)
]
]
=
θ
t
+
α
E
[
?
θ
ln
?
π
(
A
∣
S
,
θ
t
)
δ
π
(
S
,
A
)
]
\begin{aligned} \theta_{t+1} &= \theta_t + \alpha \mathbb{E} \Big[ \nabla_\theta \ln\pi (A|S, \theta_t) [{\color{blue} q_\pi(S, A) - v_\pi (S)}] \Big] \\ &= \theta_t + \alpha \mathbb{E} \Big[ \nabla_\theta \ln\pi (A|S, \theta_t) {\color{blue} \delta_\pi(S, A)} \Big] \end{aligned}
θt+1??=θt?+αE[?θ?lnπ(A∣S,θt?)[qπ?(S,A)?vπ?(S)]]=θt?+αE[?θ?lnπ(A∣S,θt?)δπ?(S,A)]?
其中,
δ
π
(
S
,
A
)
=
q
π
(
S
,
A
)
?
v
π
(
S
)
\delta_\pi(S, A) = q_\pi(S, A) - v_\pi (S)
δπ?(S,A)=qπ?(S,A)?vπ?(S)是优势函数(advantage function),表示当前状态下的特定动作相对于当前策略的优势。对应的随机采样公式为:
θ
t
+
1
=
θ
t
+
α
?
θ
ln
?
π
(
a
t
∣
s
t
,
θ
t
)
[
q
t
(
s
t
,
a
t
)
?
v
t
(
s
t
)
]
=
θ
t
+
α
?
θ
ln
?
π
(
a
t
∣
s
t
,
θ
t
)
δ
t
(
s
t
,
a
t
)
\begin{aligned} \theta_{t+1} &= \theta_t + \alpha \nabla_\theta \ln\pi (a_t|s_t, \theta_t) [ {\color{blue} q_t(s_t, a_t) - v_t(s_t)} ] \\ &= \theta_t + \alpha \nabla_\theta \ln\pi (a_t|s_t, \theta_t) {\color{blue} \delta_t(s_t, a_t)} \end{aligned}
θt+1??=θt?+α?θ?lnπ(at?∣st?,θt?)[qt?(st?,at?)?vt?(st?)]=θt?+α?θ?lnπ(at?∣st?,θt?)δt?(st?,at?)?
进一步地,优势函数可以由TD error近似(推导略),好处是只需要一个神经网络近似
v
t
v_t
vt?即可,不需要再近似
q
t
q_t
qt?。这就是A2C(也称为TD actor-critic)算法,其优势函数的具体形式为:
δ
t
=
r
t
+
1
+
γ
v
t
(
s
t
+
1
)
?
v
t
(
s
t
)
\delta_t = r_{t+1} + \gamma v_{t} (s_{t+1}) - v_t (s_t)
δt?=rt+1?+γvt?(st+1?)?vt?(st?)
*注:
- 优势函数在文献中通常记作 A A A
- 这里的直觉是,动作值的相对值比其绝对值更重要
A2C的完整算法(on-policy):
- TD error(优势函数): δ t = r t + 1 + γ v t ( s t + 1 ) ? v t ( s t ) {\color{darkred} \delta_t} = r_{t+1} + \gamma v_{t} (s_{t+1}) - v_t (s_t) δt?=rt+1?+γvt?(st+1?)?vt?(st?)
- Critic(值更新 / 策略评估):
w
t
+
1
=
w
t
+
α
w
δ
t
?
w
v
(
s
t
,
w
t
)
w_{t+1} = w_t + \alpha_w {\color{darkred} \delta_t} {\nabla_w {v}(s_t, w_t)}
wt+1?=wt?+αw?δt??w?v(st?,wt?)
- *注意这里与QAC的区别:QAC用的是Sarsa,A2C用的是TD,因此这里用状态值而非动作值
- Actor(策略更新 / 策略提升): θ t + 1 = θ t + α θ δ t ? θ ln ? π ( a t ∣ s t , θ t ) \theta_{t+1} = \theta_t + \alpha_\theta {\color{darkred} \delta_t} \nabla_\theta \ln\pi (a_t|s_t, \theta_t) θt+1?=θt?+αθ?δt??θ?lnπ(at?∣st?,θt?)
Off-policy AC
AC算法本身是on-policy的,但是可以通过重要性采样(Importance Sampling) 将其转为off-policy算法。
*实际上,重要性采样可以应用于任何需要求期望的算法(如MC、TD等)。
🟡重要性采样(Importance Sampling)
重要性采样:基于概率分布
p
1
p_1
p1?上对随机变量
X
X
X的采样,估计概率分布
p
0
p_0
p0?上
X
X
X的期望
E
[
X
]
\mathbb{E}[X]
E[X]。
*应用场景:难以直接在
p
0
p_0
p0?上计算
X
X
X的期望,但可以很容易在
p
1
p_1
p1?上对进行
X
X
X采样。例如:
p
0
p_0
p0?是连续分布,或
p
0
p_0
p0?的形式未知(如其为神经网络)。
E
X
~
p
0
[
X
]
=
∑
x
p
0
(
x
)
x
=
∑
x
p
1
(
x
)
p
0
(
x
)
p
1
(
x
)
x
?
f
(
x
)
=
E
X
~
p
1
[
f
(
X
)
]
{\color{red} \mathbb{E}_{X\sim p_0} [X] } = \sum_x p_0(x) x = \sum_x {\color{blue} p_1(x)} \underbrace{\frac{p_0(x)}{\color{blue} p_1(x)} x}_{f(x)} = {\color{red} \mathbb{E}_{X\sim p_1} [f (X)] }
EX~p0??[X]=x∑?p0?(x)x=x∑?p1?(x)f(x)
p1?(x)p0?(x)?x??=EX~p1??[f(X)]
其中,
E
X
~
p
1
[
f
(
X
)
]
\mathbb{E}_{X\sim p_1} [f (X)]
EX~p1??[f(X)]可以由对
f
(
X
)
f(X)
f(X)的采样均值直接估计(大数定律),即:
E
X
~
p
0
[
X
]
≈
f
ˉ
=
1
n
∑
i
=
1
n
f
(
x
i
)
=
1
n
∑
i
=
1
n
p
0
(
x
i
)
p
1
(
x
i
)
x
i
{\color{red} \mathbb{E}_{X\sim p_0} [X] } \approx \bar{f} = \frac{1}{n} \sum_{i=1}^{n} f(x_i) {\color{red} = \frac{1}{n} \sum_{i=1}^{n} {\color{blue} \frac{p_0(x_i)}{p_1(x_i)} } x_i }
EX~p0??[X]≈fˉ?=n1?i=1∑n?f(xi?)=n1?i=1∑n?p1?(xi?)p0?(xi?)?xi?
其中,
p
0
(
x
i
)
p
1
(
x
i
)
\frac{p_0(x_i)}{p_1(x_i)}
p1?(xi?)p0?(xi?)?是重要性权重(importance weight),其大于1表明
x
i
x_i
xi?在
p
0
p_0
p0?下被采样的概率更高,小于1表明在
p
1
p_1
p1?下被采样的概率更高。
Off-policy PG
由行为策略
β
\beta
β生成经验采样,目标是最大化下式:
J
(
θ
)
=
∑
s
∈
S
d
β
(
s
)
v
π
(
s
)
=
E
S
~
d
β
[
v
π
(
S
)
]
J(\theta) = \sum_{s \in \mathcal{S}} d_\beta (s) v_\pi (s) = \mathbb{E}_{S \sim d_\beta} [v_\pi (S)]
J(θ)=∑s∈S?dβ?(s)vπ?(s)=ES~dβ??[vπ?(S)]
其中,
d
β
d_\beta
dβ?为策略
β
\beta
β下的平稳分布。(*注意此式与策略梯度中
J
(
θ
)
J(\theta)
J(θ)为平均状态值
v
ˉ
π
\bar{v}_\pi
vˉπ?时公式的区别)
对应的梯度为:
?
θ
J
(
θ
)
=
E
S
~
ρ
,
A
~
β
[
π
(
A
∣
S
,
θ
)
β
(
A
∣
S
)
?
θ
ln
?
π
(
A
∣
S
,
θ
)
q
π
(
S
,
A
)
]
\nabla_\theta J(\theta) = \mathbb{E}_{S \sim \rho, A \sim \beta} \Big[ \frac{\pi(A|S, \theta)}{\beta(A|S)} \nabla_\theta \ln \pi (A|S, \theta) q_\pi (S, A) \Big]
?θ?J(θ)=ES~ρ,A~β?[β(A∣S)π(A∣S,θ)??θ?lnπ(A∣S,θ)qπ?(S,A)]
式中
ρ
\rho
ρ是一个状态分布,
π
(
A
∣
S
,
θ
)
β
(
A
∣
S
)
\frac{\pi(A|S, \theta)}{\beta(A|S)}
β(A∣S)π(A∣S,θ)?是重要性权重。注意
A
~
β
A \sim \beta
A~β而非
A
~
π
A \sim \pi
A~π。
Off-policy AC
基于前文分析,Off-policy AC的算法为:
θ
t
+
1
=
θ
t
+
α
θ
π
(
a
t
∣
s
t
,
θ
t
)
β
(
a
t
∣
s
t
)
?
θ
ln
?
π
(
a
t
∣
s
t
,
θ
t
)
[
r
t
+
1
+
γ
v
t
(
s
t
+
1
)
?
v
t
(
s
t
)
]
=
θ
t
+
α
θ
π
(
a
t
∣
s
t
,
θ
t
)
β
(
a
t
∣
s
t
)
?
θ
ln
?
π
(
a
t
∣
s
t
,
θ
t
)
δ
t
(
s
t
,
a
t
)
\begin{aligned} \theta_{t+1} &= \theta_t + \alpha_\theta \frac{\pi(a_t|s_t, \theta_t)}{\beta(a_t|s_t)} \nabla_\theta \ln\pi (a_t|s_t, \theta_t) [ {r_{t+1} + \gamma v_{t} (s_{t+1}) - v_t (s_t)} ] \\ &= \theta_t + \alpha_\theta \frac{\pi(a_t|s_t, \theta_t)}{\beta(a_t|s_t)} \nabla_\theta \ln\pi (a_t|s_t, \theta_t) {\delta_t(s_t, a_t)} \end{aligned}
θt+1??=θt?+αθ?β(at?∣st?)π(at?∣st?,θt?)??θ?lnπ(at?∣st?,θt?)[rt+1?+γvt?(st+1?)?vt?(st?)]=θt?+αθ?β(at?∣st?)π(at?∣st?,θt?)??θ?lnπ(at?∣st?,θt?)δt?(st?,at?)?
算法步骤及伪代码类似于A2C,主要是多了重要性权重 π ( a t ∣ s t , θ t ) β ( a t ∣ s t ) \frac{\pi(a_t|s_t, \theta_t)}{\beta(a_t|s_t)} β(at?∣st?)π(at?∣st?,θt?)?。
🟦DPG (Deterministic AC)
先前的PG及AC算法均为随机性(stochastic)策略,实际上也存在确定性(deterministic)策略的AC算法,即DPG(Deterministic Policy Gradient)。
确定性策略相对于随机性策略的优势:随机性策略只能处理有限个动作的情况(比如,神经网络的输出是有限的),而确定性策略可以处理连续的动作空间。
确定性策略记作:
a
=
μ
(
s
,
θ
)
a = \mu (s, \theta)
a=μ(s,θ),也可以简记为
μ
(
s
)
\mu (s)
μ(s)。
μ
\mu
μ是从状态空间
S
\mathcal{S}
S到动作空间
A
\mathcal{A}
A的映射,可以由神经网络表示。
DPG为off-policy方法(动作不依赖于具体策略),其梯度计算如下:
?
θ
J
(
θ
)
=
∑
s
∈
S
ρ
μ
(
s
)
?
θ
μ
(
s
)
(
?
a
q
μ
(
s
,
a
)
)
∣
a
=
μ
(
s
)
=
E
S
~
ρ
μ
[
?
θ
μ
(
s
)
(
?
a
q
μ
(
s
,
a
)
)
∣
a
=
μ
(
s
)
]
\begin{aligned} \nabla_\theta J (\theta) &= \sum_{s \in \mathcal{S}} \rho_\mu (s) \nabla_\theta \mu(s) (\nabla_a q_\mu (s, a)) |_{a = \mu (s)} \\ & = \mathbb{E}_{S \sim \rho_\mu} [\nabla_\theta \mu(s) (\nabla_a q_\mu (s, a)) |_{a = \mu (s)}] \end{aligned}
?θ?J(θ)?=s∈S∑?ρμ?(s)?θ?μ(s)(?a?qμ?(s,a))∣a=μ(s)?=ES~ρμ??[?θ?μ(s)(?a?qμ?(s,a))∣a=μ(s)?]?
其中,
ρ
μ
\rho_\mu
ρμ?是一个状态分布。
(
?
a
q
μ
(
s
,
a
)
)
∣
a
=
μ
(
s
)
(\nabla_a q_\mu (s, a)) |_{a = \mu (s)}
(?a?qμ?(s,a))∣a=μ(s)?表示先对
q
μ
(
s
,
a
)
q_\mu(s,a)
qμ?(s,a)求关于
a
a
a的梯度,再将其中
a
a
a的替换为
μ
(
s
)
\mu(s)
μ(s)。
对应的随机梯度上升算法为:
θ
t
+
1
=
θ
t
+
α
θ
?
θ
μ
(
s
t
)
(
?
a
q
μ
(
s
t
,
a
)
)
∣
a
=
μ
(
s
)
\theta_{t+1} = \theta_t + \alpha_\theta \nabla_\theta \mu(s_t) (\nabla_a q_\mu (s_t, a)) |_{a=\mu(s)}
θt+1?=θt?+αθ??θ?μ(st?)(?a?qμ?(st?,a))∣a=μ(s)?
DPG算法步骤(伪代码):
初始化:行为策略
β
(
a
∣
s
)
\beta (a|s)
β(a∣s);确定性目标策略
μ
(
s
,
θ
0
)
\mu(s, \theta_0)
μ(s,θ0?),其中
θ
0
\theta_0
θ0?为初始参数向量;值函数
v
(
s
,
w
0
)
v(s, w_0)
v(s,w0?),其中
w
0
w_0
w0?为初始参数向量。(*
β
\beta
β也可以被替换为
μ
\mu
μ+噪音)
目标:最大化
J
(
θ
)
J(\theta)
J(θ)
步骤:在每个episode的第
t
t
t个时间步中,遵循行为策略
β
\beta
β产生动作
a
t
a_t
at?并获得
r
t
+
1
r_{t+1}
rt+1?和
s
t
+
1
s_{t+1}
st+1?
- TD error(优势函数): δ t = r t + 1 + γ q ( s t + 1 , μ ( s t + 1 , θ t ) , w t ) ? q ( s t , a t , w t ) {\color{darkred} \delta_t} = r_{t+1} + \gamma q(s_{t+1}, \mu(s_{t+1}, \theta_t), w_t) - q(s_t, a_t, w_t) δt?=rt+1?+γq(st+1?,μ(st+1?,θt?),wt?)?q(st?,at?,wt?)
- Critic(值更新 / 策略评估): w t + 1 = w t + α w δ t ? w q ( s t , a t , w t ) w_{t+1} = w_t + \alpha_w {\color{darkred} \delta_t} \nabla_w q(s_t, a_t, w_t) wt+1?=wt?+αw?δt??w?q(st?,at?,wt?),即TD+值函数估计
- Actor(策略更新 / 策略提升): θ t + 1 = θ t + α θ ? θ μ ( s t , θ t ) ( ? a q ( s t , a , w t + 1 ) ) ∣ a = μ ( s t ) \theta_{t+1} = \theta_t + \alpha_\theta \nabla_\theta \mu(s_t, \theta_t) (\nabla_a q (s_t, a, w_{t+1})) |_{a=\mu(s_t)} θt+1?=θt?+αθ??θ?μ(st?,θt?)(?a?q(st?,a,wt+1?))∣a=μ(st?)?
注意到DPG中包含了 q ( s , a , w ) q(s,a,w) q(s,a,w),其可以由两种方式确定:
- 线性函数: q ( s , a , w ) = ? T ( s , a ) w q(s,a,w) = \phi^T (s,a) w q(s,a,w)=?T(s,a)w,其中 ? ( s , a ) \phi(s,a) ?(s,a)是特征向量。这是DPG原论文中采用的方法,缺陷在于特征向量的选择比较困难,且线性函数的拟合能力有限
- 神经网络:即后续的DDPG(Deep deterministic policy gradient)方法
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux调试工具—gdb
- 进程间通信-共享内存
- 【华为OD机试真题2023C&D卷 JAVA&JS】5G网络建设
- 多线程技术学习笔记(尚学堂-百战)
- 在基于 Android 相机预览的 CV 应用程序中使用 OpenCL
- 数据中心母线监测系统应用及产品监控选型
- SQL命令---带关系运算符的条件查询
- 联表查询(重难点)
- 大模型学习笔记07——大模型之Adaptation
- Java中Collections详解