语音合成技术简介
最近由于工作需要,对语音合成技术进行了一些研究,总结一下。
语音合成技术又称为文本转语音技术,简单来说就是把一段文字按照一定的需求转化为对应的音频。文本转语音是一项包含了语义学、声学、数字信号处理以及机器学习的等多项学科的交叉任务。相对于英语的语音合成,中文博大精深,存在多音字,一字多义等各种情况,想把一段中文文本转换为正确的音频绝非易事。
更广义的语音合成又包括语音转换和歌唱合成,语音转换是把当前音频按照需求进行转换,例如说话人转换、语音到歌唱转换、语音情感转换、口音转换等;歌唱合成包括歌词到歌唱转换、可视语音合成等。
1. 发展历史
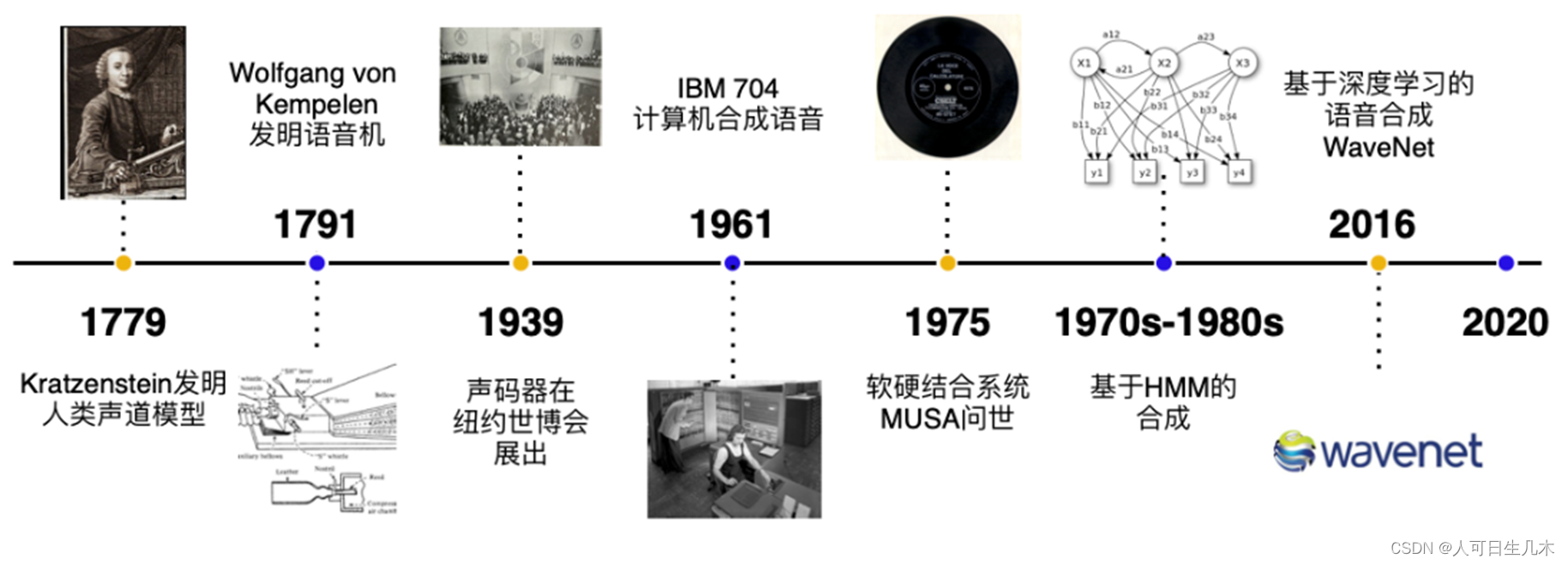
1779年,德裔丹麦科学家 Christian Gottlieb Kratzenstein 建造了人类的声道模型,使其可以产生五个长元音。
1791年, Wolfgang von Kempelen 添加了唇和舌的模型,使其能够发出辅音和元音。
贝尔实验室于20世纪30年代发明了声码器(Vocoder),将语音自动分解为音调和共振,此项技术由 Homer Dudley 改进为键盘式合成器并于 1939年纽约世界博览会展出。第一台基于计算机的语音合成系统起源于20世纪50年代。
1961年,IBM 的 John Larry Kelly,以及 Louis Gerstman 使用 IBM 704 计算机合成语音,成为贝尔实验室最著名的成就之一。
1975年,第一代语音合成系统之一 —— MUSA(MUltichannel Speaking Automation)问世,其由一个独立的硬件和配套的软件组成。
1978年发行的第二个版本也可以进行无伴奏演唱。
90 年代的主流是采用 MIT 和贝尔实验室的系统,并结合自然语言处理模型。
2016年,谷歌发布了WavNet,这是第一个能生成人类自然语音的深度神经网络。随着WavNet的面世,对我们来说以端对端(来自声音记录本身)的方式来生成未处理的声音样本成为可能,可以简单的修饰声音,更重要的是和现存的语音处理方式相比,得到的声音明显的更加自然。所有的一切都要感谢深度学习的出现。
随后国内大厂商百度和阿里先后发布了中文语音合成模型PaddleSpeech和Sambert-Hifigan。
基于深度学习的语音合成流水线包含 文本前端(Text Frontend)、声学模型(Acoustic Model) 和 声码器(Vocoder) 三个主要模块。
2、PaddleSpeech
采用了易用、高效、灵活以及可扩展的实现,旨在为工业应用、学术研究提供更好的支持,实现的功能包含训练、推断以及测试模块,以及部署过程,主要包括
| 语音合成模块类型 | 模型类型 | 数据集 | 脚本 |
| 文本前端 | ? | ||
| 声学模型 | Tacotron2 | LJSpeech / CSMSC | |
| Transformer TTS | LJSpeech | ||
| SpeedySpeech | CSMSC | ||
| FastSpeech2 | LJSpeech / VCTK / CSMSC / AISHELL-3 | fastspeech2-ljspeech?/?fastspeech2-vctk?/?fastspeech2-csmsc?/?fastspeech2-aishell3 | |
| 声码器 | WaveFlow | LJSpeech | |
| Parallel WaveGAN | LJSpeech / VCTK / CSMSC / AISHELL-3 | ||
| Multi Band MelGAN | CSMSC | ||
| Style MelGAN | CSMSC | ||
| HiFiGAN | LJSpeech / VCTK / CSMSC / AISHELL-3 | HiFiGAN-ljspeech?/?HiFiGAN-vctk?/?HiFiGAN-csmsc?/?HiFiGAN-aishell3 | |
| WaveRNN | CSMSC | ||
测试
from paddlespeech.cli.tts.infer import TTSExecutor
tts = TTSExecutor()
tts(text="今天天气十分不错,我们出去玩吧!", output="output.wav")3、Sambert-Hifigan
整体框架:

拼接法和参数法是两种Text-To-Speech(TTS)技术路线。近年来参数TTS系统获得了广泛的应用,故此处仅涉及参数法。
参数TTS系统可分为两大模块:前端和后端。 前端包含文本正则、分词、多音字预测、文本转音素和韵律预测等模块,它的功能是把输入文本进行解析,获得音素、音调、停顿和位置等语言学特征。 后端包含时长模型、声学模型和声码器,它的功能是将语言学特征转换为语音。其中,时长模型的功能是给定语言学特征,获得每一个建模单元(例如:音素)的时长信息;声学模型则基于语言学特征和时长信息预测声学特征;声码器则将声学特征转换为对应的语音波形。
系统结构:

前端模块我们采用模型结合规则的方式灵活处理各种场景下的文本,后端模块则采用SAM-BERT + HIFIGAN提供高表现力的流式合成效果。
from modelscope.outputs import OutputKeys
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
text = '今天天气十分不错,我们出去玩吧!'
model_id = 'damo/speech_sambert-hifigan_tts_zh-cn_16k'
sambert_hifigan_tts = pipeline(task=Tasks.text_to_speech, model=model_id)
output = sambert_hifigan_tts(input=text, voice='zhitian_emo')
wav = output[OutputKeys.OUTPUT_WAV]
with open('output.wav', 'wb') as f:
f.write(wav)利用两种框架分别做了简单测试,发现结果还是存在一定差异。
合成的音频文件目前都是机器声,已经有人利用提供的原始音频合成特定人员的音频文件,但还是有所差异,想要合成特定人员的音频就需要大量的原始音频进行音频特征提取和模型训练。此外,模拟声音相似度提高又将引发安全问题,不法分子难免会利用合成音频进行诈骗等违法行为,所以,如何在提高音频合成技术成熟度的前提下保证安全合理应用,也是需要解决的问题。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- stable diffusion 基础教程-必备插件
- 网络安全:SSRF+XXE漏洞挖掘笔记
- 深入理解Vue生命周期钩子及其应用
- kafka之消费者(Consumer)
- 探索无限创意的先锋之选——Resolume Arena VJ音视频软件
- 【百科物理】-2.重力与浮力
- HarmonyOS 属性动画
- 第一次在RUST官方论坛上留言发布我的Rust板箱
- 文件批量管理,按单值大小归类保存,提升工作效率与便捷性!
- 虐杀原形2闪退、prototype2打开闪退,无法运行解决办法