菜鸟初进stable diffusion
不知道是不是玩novelai被boss看到了,推荐了我学stable diffusion
扩散模型
DALL E
Midjourney
stable diffusion
latent diffusion
说是改进点在于“给输入图片压缩降低维度,所以有个latent,从而减少计算量”,类似于下采样吧,编码后在特征空间搞动作,而不是像diffusion那样直接在像素上搞动作。当然减少计算量的代价就是细节的丢失。
-》stable diffusion
diffusion
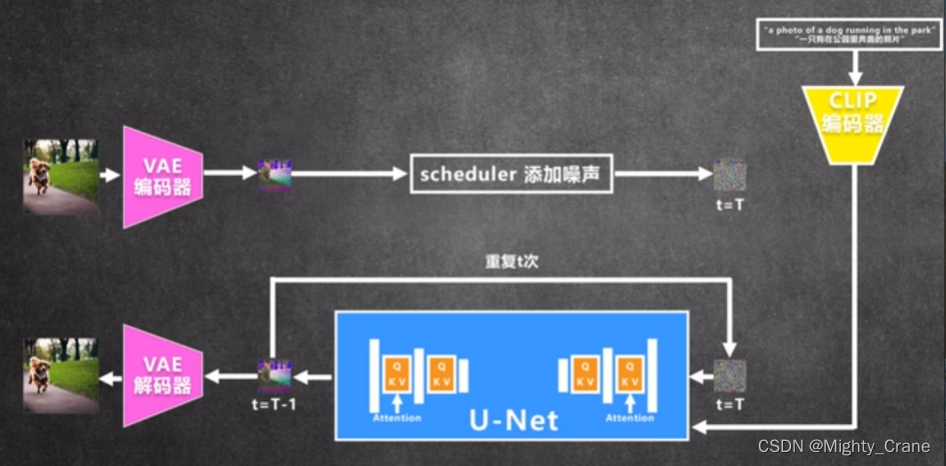
文本-》CLIP的文本编码器-》diffusion(unet+scheduler)-》VAE的解码器
关于图像生成,提到了“给原始图片逐渐加入噪声,然后再逐步去除噪声以还原图片”这个过程,可以理解为生成模块学习到了哪些像素是必需的,哪些像素是无关紧要的,识别和保留那些对于图像的整体结构和识别最为重要的特征,同时忽略或去除那些不影响图像识别或结构的变化。这对于生成图像、图像编辑、图像压缩等任务特别有用,因为它使模型能够创造出既精确又具有视觉上可信度的结果。

有文本提示生成的噪声和无文本提示生成的噪声相减,得到文本带来的噪声变化,将这个噪声变化视作信号放大(这个放大倍数7.5就是UI上的guidance scale参数)后,再附加到无提示的噪声上就得到了一个心仪的噪声
其中50是个噪声步长scheduler,相当于指示加入噪声的程度,刚才得到的心仪噪声是50对应的噪声变化量加到49对应的无提示噪声上,从而这样一步步重构原图去除噪声
所以负向提示其实就是让正向提示噪声-负向提示噪声,从而原理负向提示
VAE
sd的训练其实就是基于VAE编码器的结果作为输入的
其他模型
dreambooth
直接拿新的图文数据去微调unet
当然图文是先分别过一下VAE和CLIP的编码器得到特征的
相当于只不冻结unet部分的微调
不过保存的模型是一整个,会很大
LORA
只是在unet那一部分加入一些新的层,训练也只训练这些新层,保存文件比较小
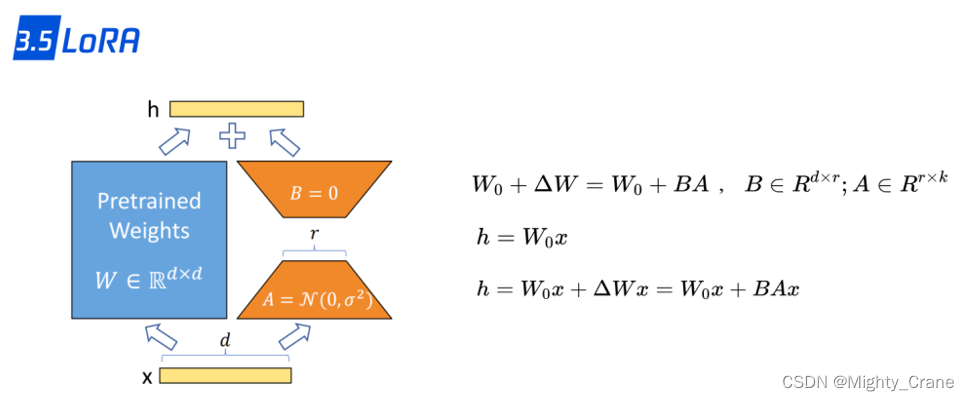
其实和大模型参数高效微调中的lora一样,因为不修改原有网络结构,所以是可以实现的操作
对在每个密集层逼近更新矩阵施加了低秩约束,以减少适应下游任务的可训练参数。考虑优化参数矩阵 W 的情况。更新过程可以写成一般形式:W ← W + ΔW。LoRA的基本思想是冻结原始矩阵 W ∈ Rm×n,同时通过低秩分解矩阵逼近参数更新 ΔW,即 ΔW = A · B?,其中 A ∈ Rm×k 和 B ∈ Rn×k 是任务适应的可训练参数,k ? min(m, n) 是降秩。LoRA 的主要优点是它可以在很大程度上节省内存和存储使用(例如,VRAM)。
textual inversion
调整CLIP得到适应新的图片的文本特征
相当于冻结视觉编码器,微调文本编码器
保存模型更小
controlnet
输入骨骼等辅助信息
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Radzen Blazor Studio 脚手架框架解读
- 【无标题】
- 【HarmonyOS4.0】第二篇-鸿蒙开发介绍
- 考研真题c语言
- Mysql 数据库DML 数据操作语言—— 对数据库表中的数据进行增删改
- 云风网(www.niech.cn)个人网站搭建(二)服务器域名配置
- 【leetcode100-018】【矩阵】矩阵置零
- Python单元测试框架:pytest常用测试报告类型
- crfclust.bdb文件过大处理
- K8S--安装metrics-server,解决error: Metrics API not available问题