数据操作——无类型的转换算子
发布时间:2024年01月19日
无类型的转换算子
-
以下算子有@Test的前置条件
// 1. 创建SparkSession val spark = SparkSession.builder() .appName("trans_test") .master("local[6]") .getOrCreate() // 导入隐式转换 import spark.implicits._ // case样例类 case class Person(name: String, age: Int)
选择
- 选择
-
select
select 用来选择某些列出现在结果集中
@Test def select(): Unit = { val ds = Seq(Person("zhangsan", 20),Person("zhangsan", 18), Person("lisi", 15)).toDS // select from .. // from ..select .. //在Dataset中,select可以在任何位置调用 // select ds.select('name).show() }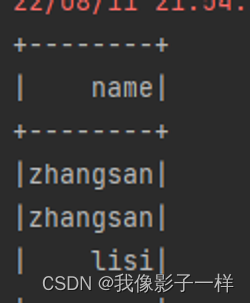
-
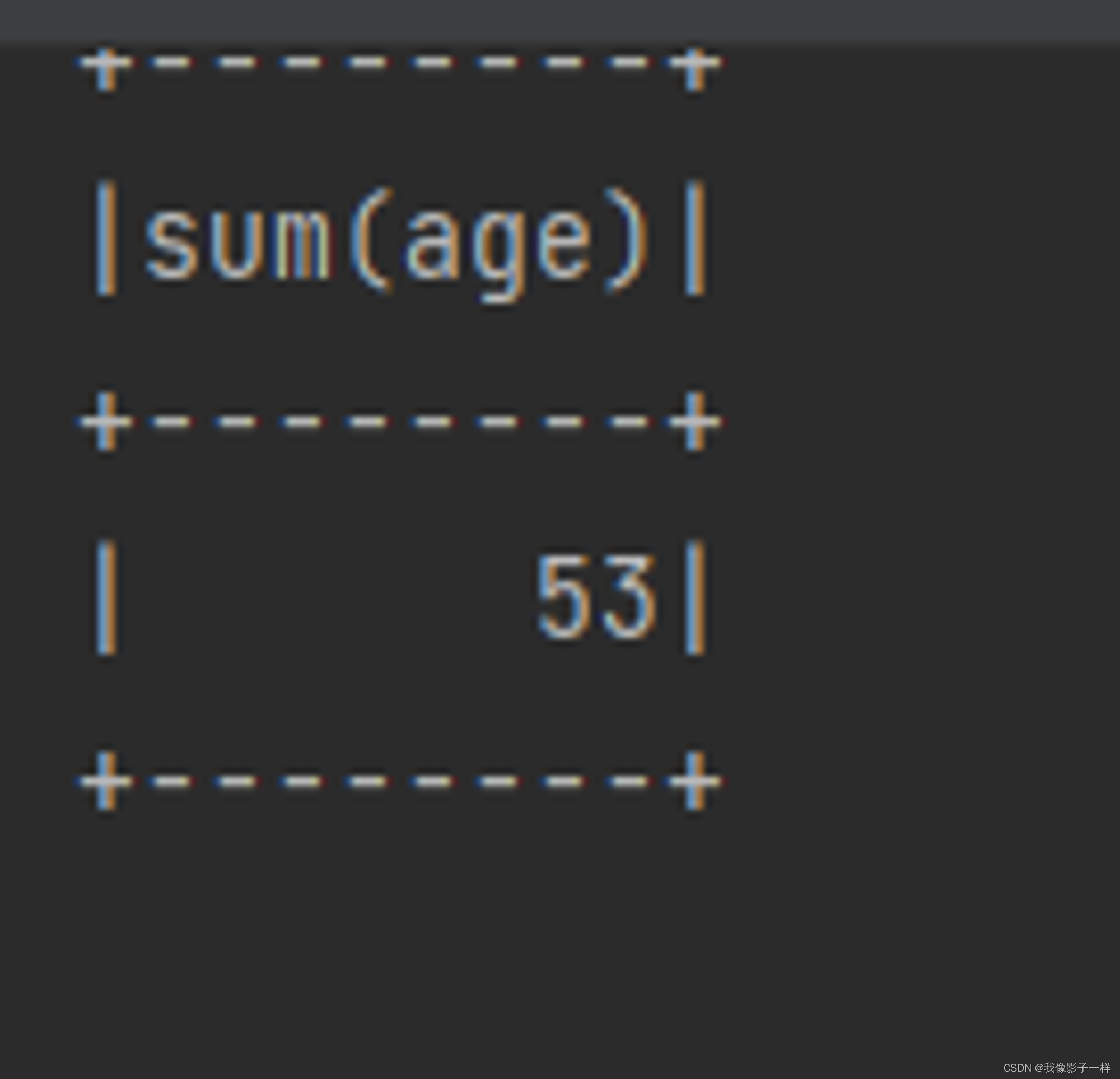
selectExpr
在 SQL 语句中, 经常可以在 select 子句中使用 count(age), rand() 等函数, 在 selectExpr 中就可以使用这样的 SQL 表达式, 同时使用 select 配合 expr 函数也可以做到类似的效果
@Test def select(): Unit = { val ds = Seq(Person("zhangsan", 20),Person("zhangsan", 18), Person("lisi", 15)).toDS // **selectExpr** ds.selectExpr("sum(age)").show() println("----------------") // select count(*) import org.apache.spark.sql.functions._ ds.select(expr("sum(age)")).show() }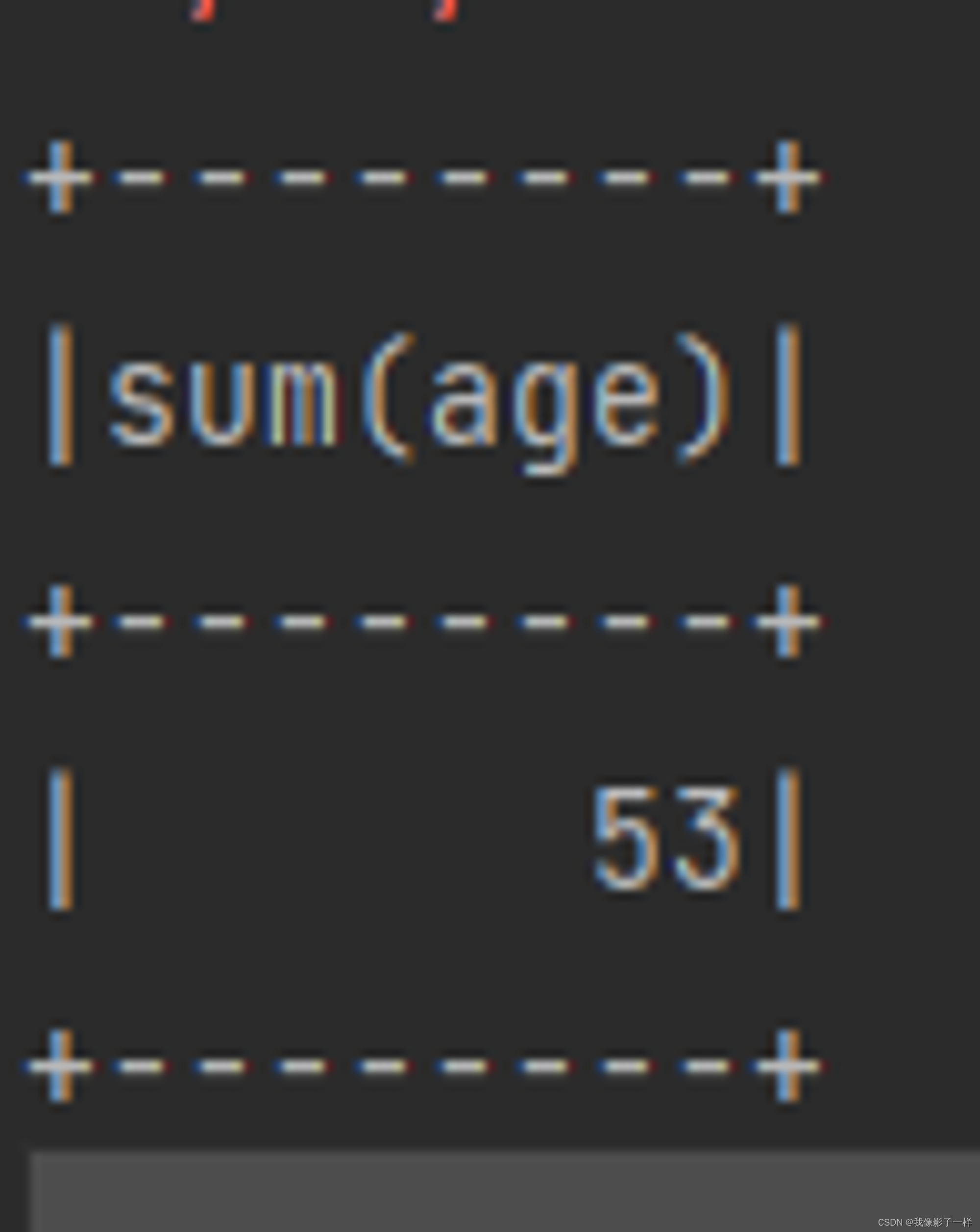
-
withColumn (新增列或修改列名)
通过 Column 对象在 Dataset 中创建一个新的列或者修改原来的列
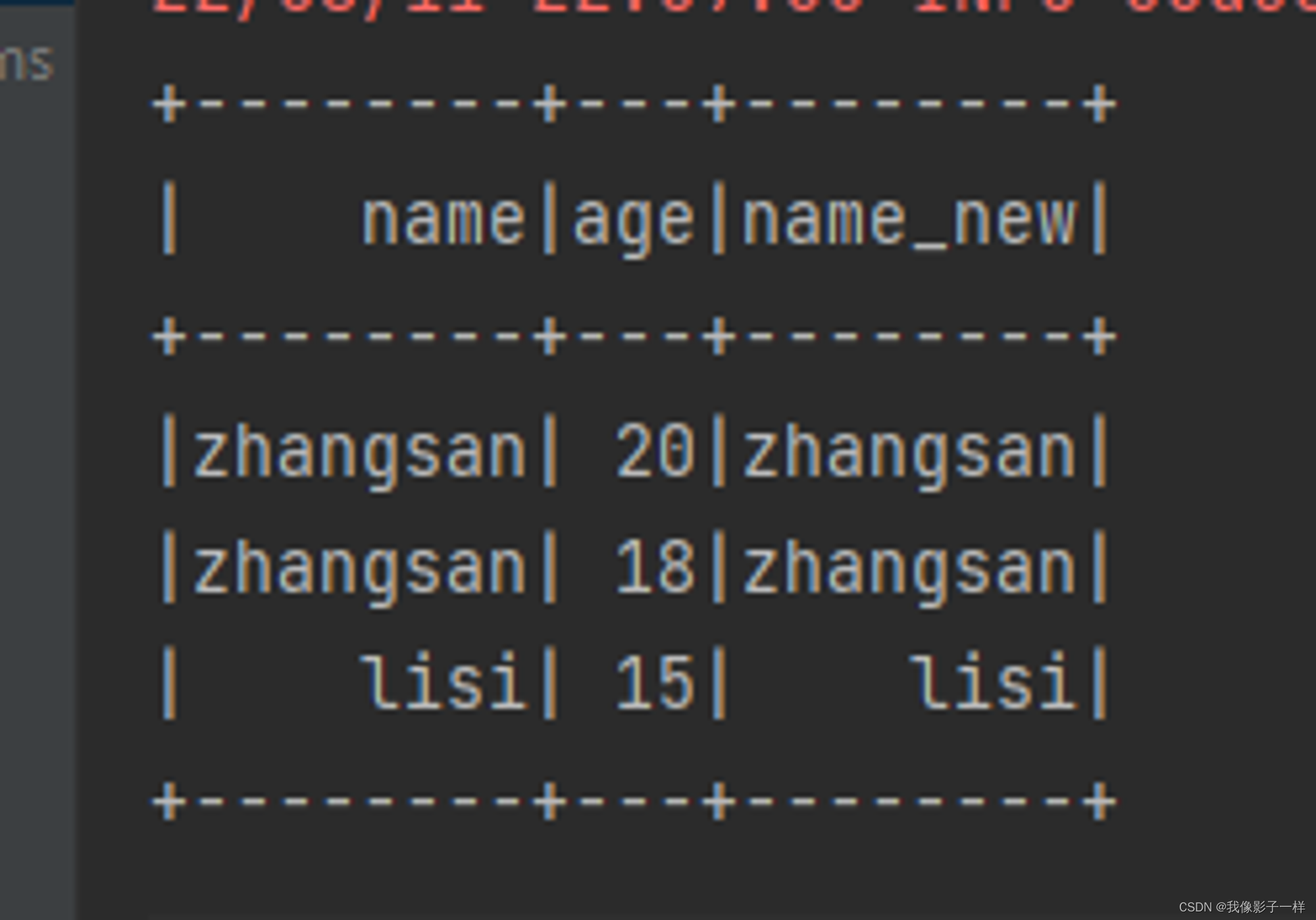
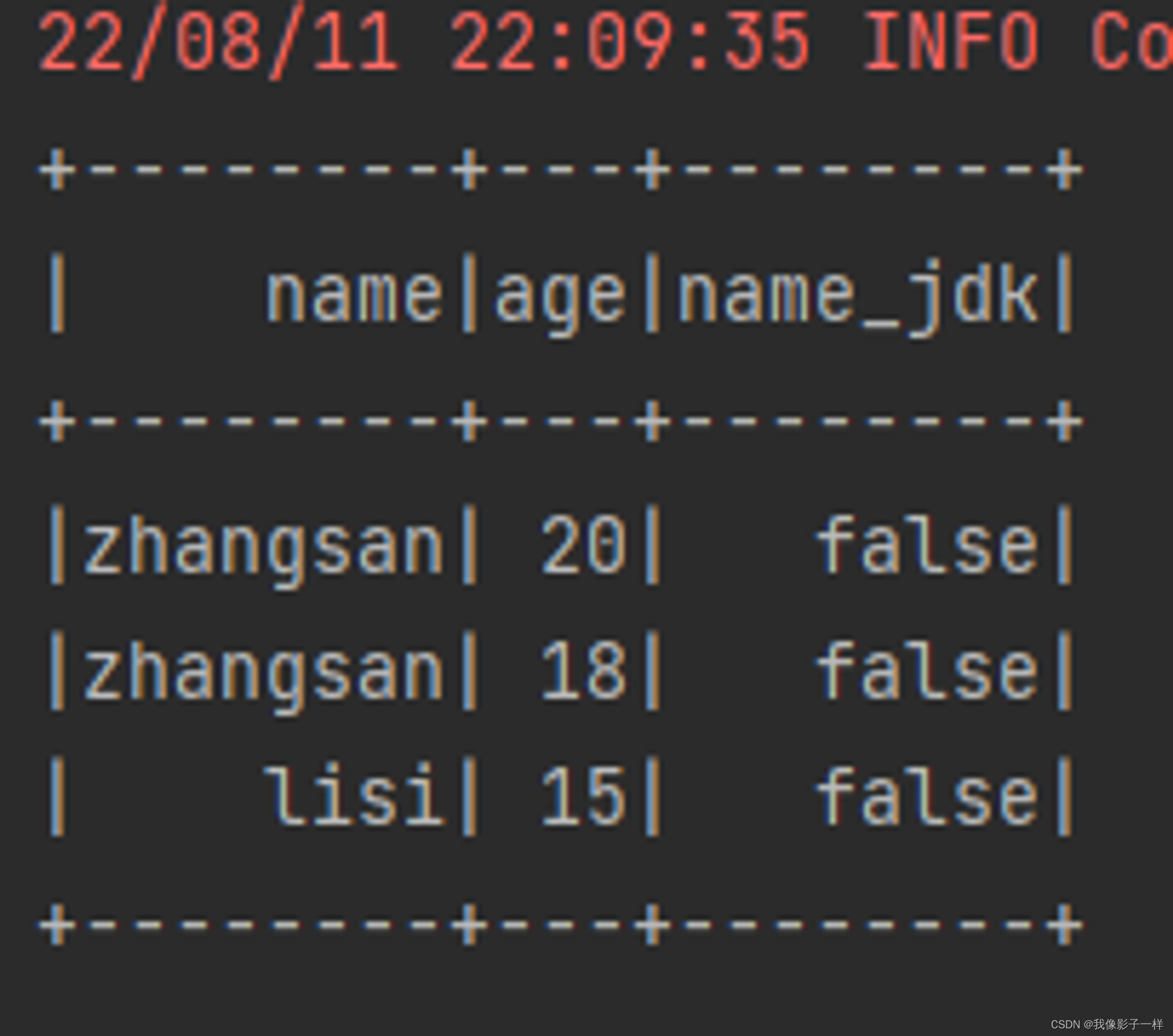
@Test def column(): Unit ={ val ds = Seq(Person("zhangsan", 20),Person("zhangsan", 18), Person("lisi", 15)).toDS //如果想使用函数功能 //1.使用functions.xx //2.使用表达式,可以使用expr("..."),随时随地编写表达式 // import org.apache.spark.sql.functions._ ds.withColumn("random",expr("rand()")).show() ds.withColumn("name_new",'name).show() ds.withColumn("name_jdk",'name === "" ).show() // 返回true 或 false }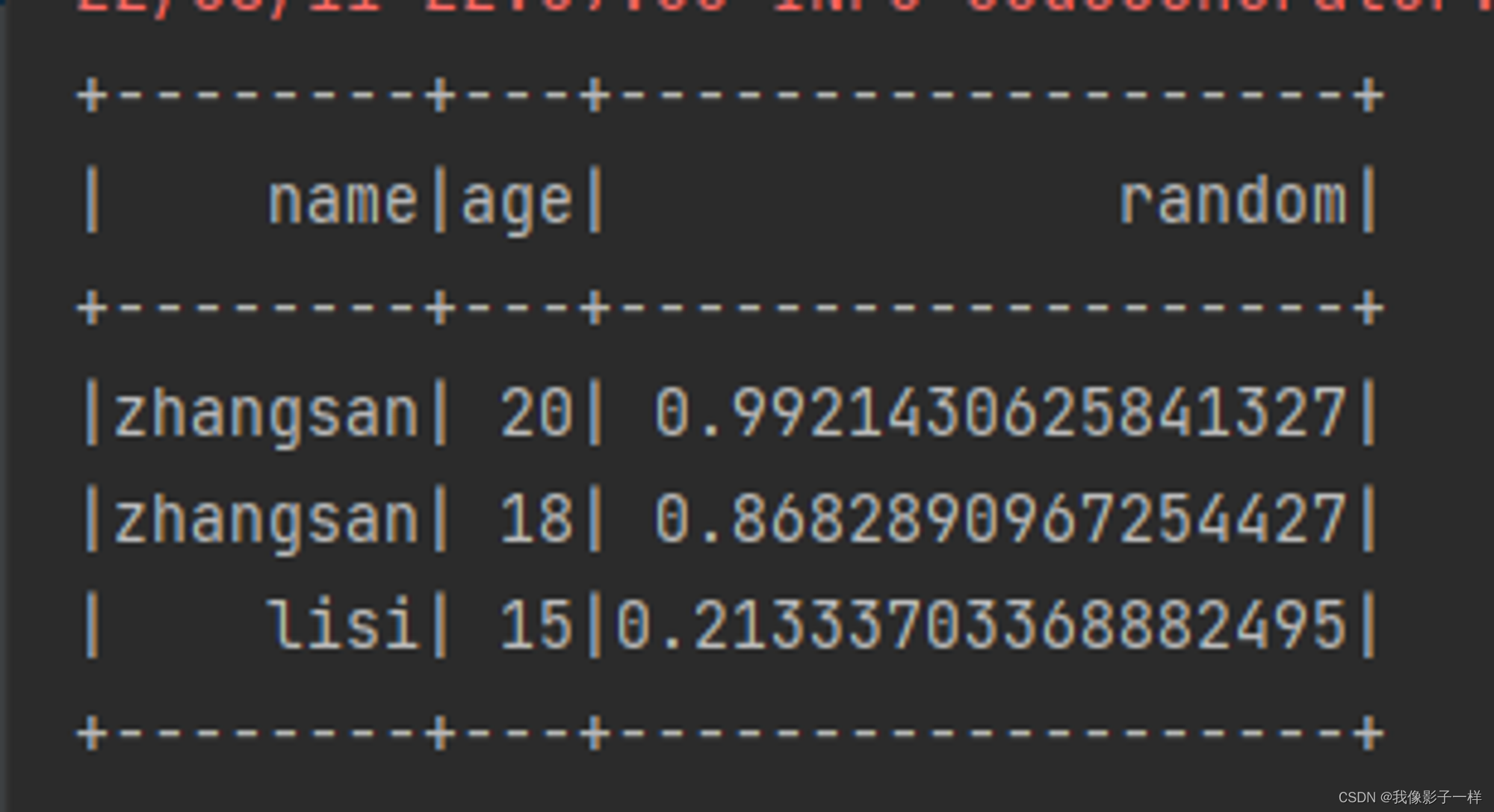
-
withColumnRenamed(修改列名)
修改列名
def column(): Unit ={ val ds = Seq(Person("zhangsan", 20),Person("zhangsan", 18), Person("lisi", 15)).toDS ds.withColumnRenamed("name","new_name").show() }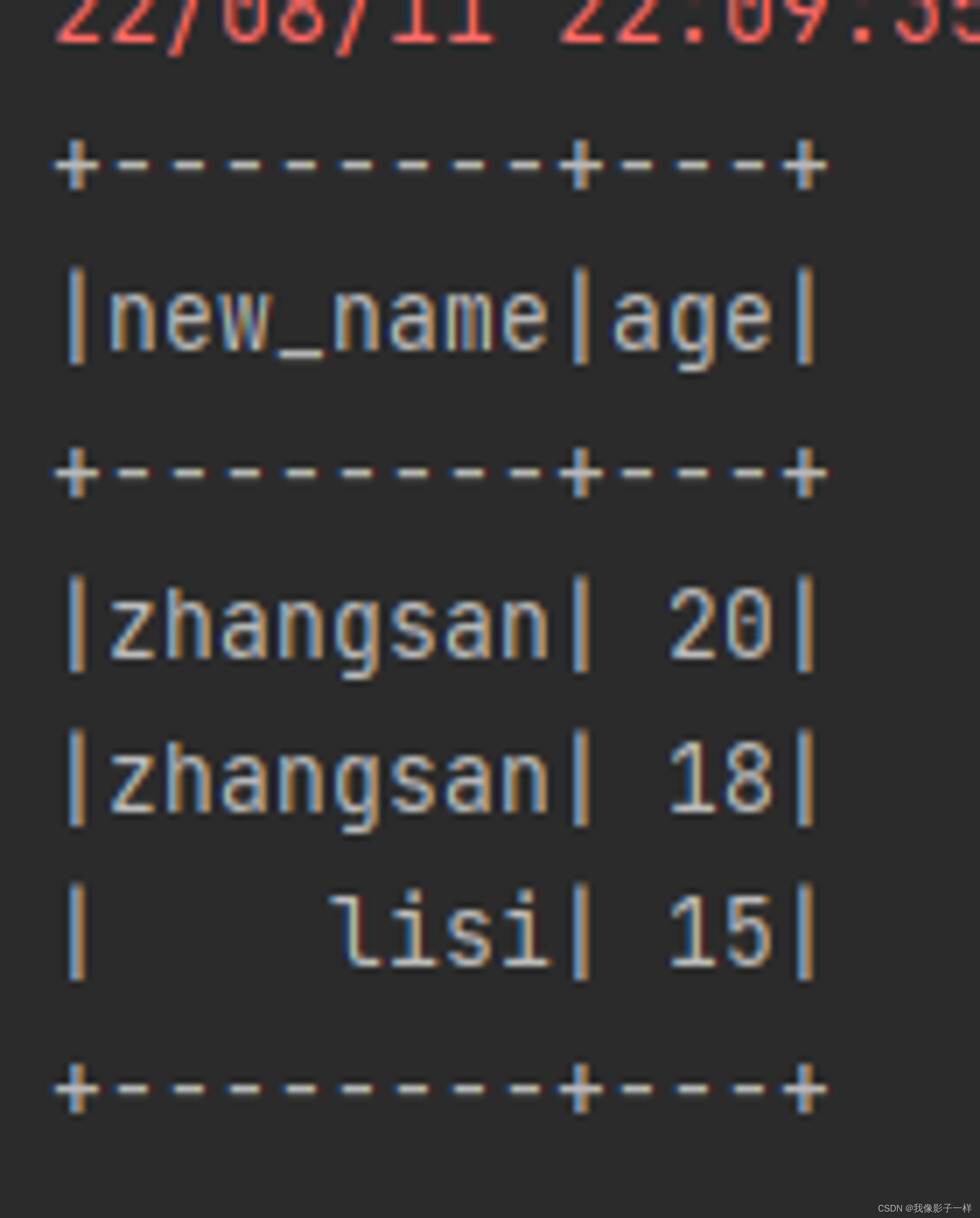
-
剪除 drop
-
剪除 drop
剪掉某个列
@Test def drop(): Unit = { val ds = Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDS() // drop ds.drop('age).show() }
聚合 groupBy
-
聚合 groupBy
按照给定的行进行分组
@Test def groupBy(): Unit ={ val ds = Seq(Person("zhangsan", 20),Person("zhangsan", 18), Person("lisi", 15)).toDS // groupBy //为什么GroupByKey是有类型的,最主要原因是因为 GroupByKey 生成的对象的算子是有类型的 //为什么GroupBy是无类型的,因为GroupBy生成的对象的算子是无类型的,针对列进行处理的 ds.groupBy('name).agg(mean("age")).show() }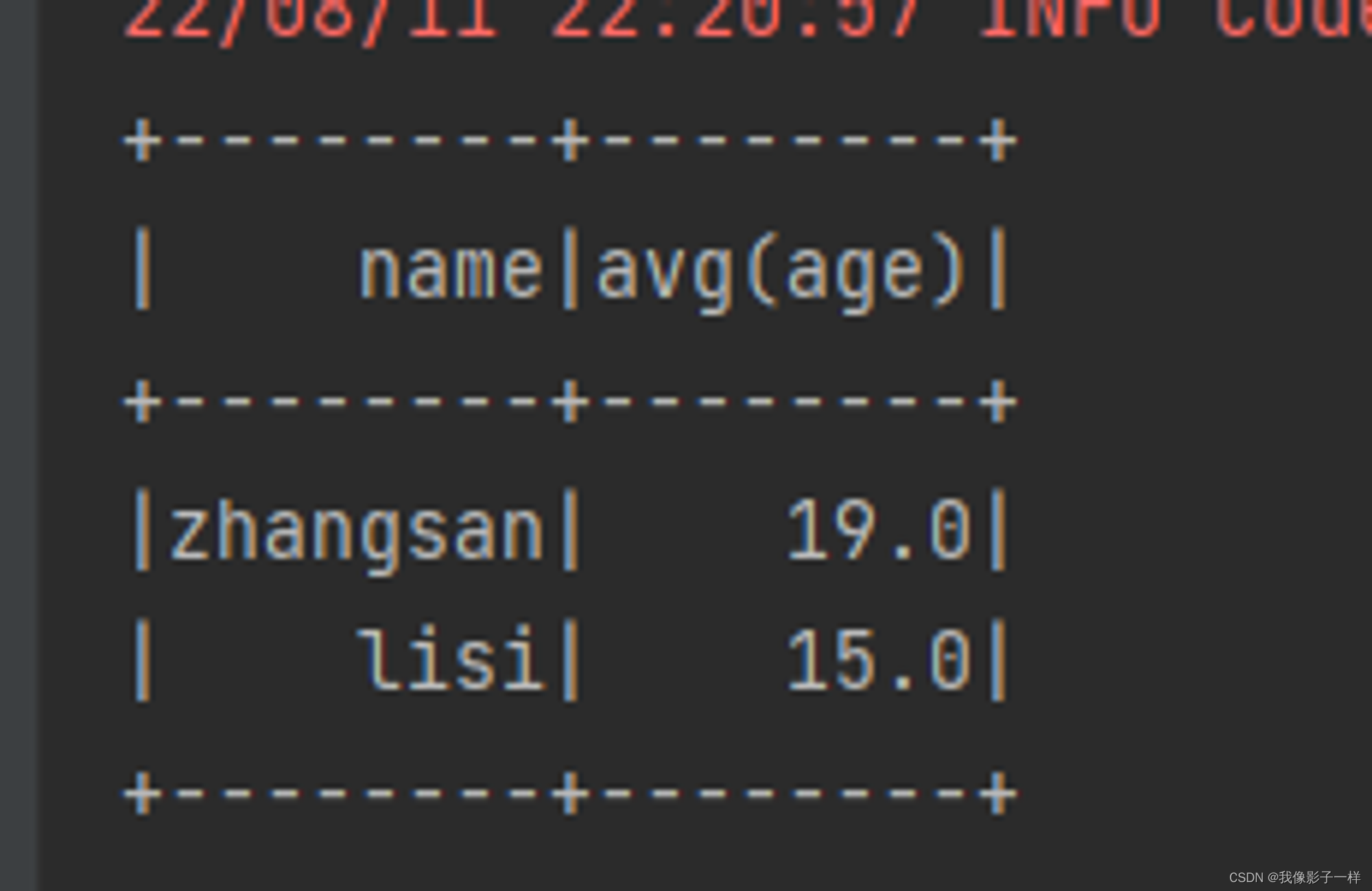
文章来源:https://blog.csdn.net/m0_56181660/article/details/135641798
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- positivessl多域名证书能保护几个域名
- 探索数字隔离器π160M60 代替TLP2745 :主要特性与应用
- (2021|CVPR,XMC-GAN,对比学习,注意力自调制)用于文本到图像生成的跨模态对比学习
- RT-Thread 瑞萨 智能家居网络开发:RA6M3 HMI Board 以太网+GUI技术实践
- SQL注入攻击和防御
- 直播的前景与发展一
- Shell脚本构成与变量介绍
- (免费领源码)java#springboot#mysql宠物领养系统的设计与实现46903-计算机毕业设计项目选题推荐
- WPF实现更加灵活绑定复杂Command(使用Microsoft XAML Behaviors 库)
- Polynomial(Linear) Regression 多项式线性回归