后处理:Calibration Method
和Detection相反,Calibration把重心放在模型回答的后处理上。也就是先不做判断直接使用模型生成回答,再调用工具对回答进行校验和修改。这里我们介绍谷歌和微软提出的几种方案。不同方案对于如何后处理,和调用哪些工具进行后处理存在差异,不过整体流程都和下图相似:模型生成 -> 召回相关知识 -> 对生成结果进行校验和修复
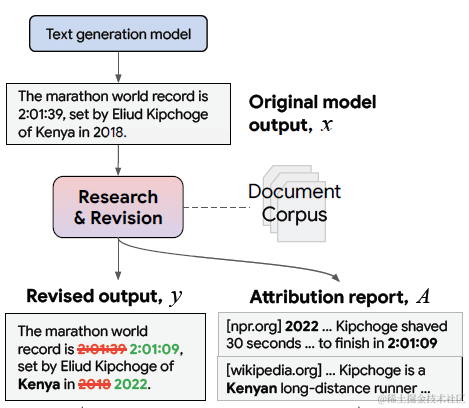
指令方案
RARR: Researching and Revising What Language Models Say, Using Language Models
CRITIC: LARGE LANGUAGE MODELS CAN SELFCORRECT WITH TOOL-INTERACTIVE CRITIQUING
基础方案是RARR提出的Research-then-revise框架,整个流程分为以下几个步骤
Generation Stage,先让LLM直接生成问题回答X
Research Stage,用于收集可以校验回答的事实性证据。针对X使用Few-shot-prompt, 生成用来校验X的多个搜索问题,每个问题分别进行谷歌搜索并召回Top5内容。这里论文没有使用搜索自带的snippet,而是对网页内容进行分块(每4个句子一块),并使用T5-Encoder计算每个chunk和query的相似度保留top-J个内容块。这里会得到一个(Q1,chunk1)(Q1,chunk2),(Q2,chunk1),.....的(问题,事实)列表
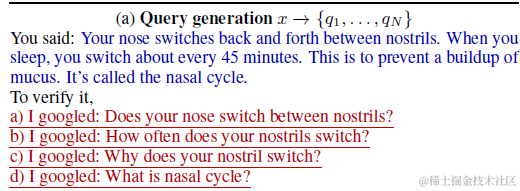
Revise Stage,获取所有检索到的事实之后,进入校验阶段。论文会遍历以上列表,针对每一个问题,分别先使用few-shot-cot判断每个事实和模型回答X之间是否是一致的(agreement model如下)。如果一致则遍历下一个,如果不一致则使用few-shot-prompt让大模型基于事实+问题对模型回答进行修改(revision model如下)。论文在修改回答时,会先定位原始回答X中哪个span和事实不符再进行修改,从而避免大幅修改原始回答


评估部分,后处理方案需要兼顾对模型原始回答的保留和事实性,这里RARR提出了两个指标:
-
Attribution Score计算归因得分,既给定所有事实,修改后回答Y中每个句子和所有事实的最大NLI打分的平均值,既整体回答能获得事实性支撑的平均概率
-
Preservation score计算保留率,由回答原始意图的保留概率 * 前后答案的未改变率(编辑距离度量)得到

RARR最大的问题在于效率,一部分是大模型的推理效率,一方面是最后的Revise部分采用了串行修改,这部分在后面的微调方案中会有改良
另一篇论文CRITIC提出的verify-then-correct和RARR非常相似,只不过在不同的任务上尝试使用了不同的外部工具进行校验。在开放问答上使用搜索,在代码问题就用代码解释器,并未涉及动态的工具选择,只是在不同数据集上固定选用不同的工具,这里就不展开说啦,感兴趣的盆友自己去看论文吧~
微调方案
PURR: Efficiently Editing Language Model Hallucinations by Denoising Language Model Corruptions
Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback
Fusion-in-decoder: Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
PURR针对RARR的效率问题进行了优化,使用的是大模型能力通过数据蒸馏到小模型的方案,也就是把上面最耗时的Revise部分使用T5-large模型来实现,query生成的部分也用T5-large来实现,并且把串行修改的方案优化为了所有事实进行一次性融合修改。
论文的核心就在于如何使用大模型来构建用于事实性修改的T5模型。论文使用了corrput的方案,也就是把正确的回答,人为进行破坏构造幻觉,再训练模型进行还原,具体包含以下几个步骤
-
生成正确的回答:整理了来自各个领域和话题的6000个种子问题,每个问题调用搜索引擎获取TopN网页,并进行chunking分段,使用和上面RARR相同的T5-Encoder计算每个段落和Q的相似度,阈值以上的为positive evidence(E++)这里限制最多4条,其余阈值以下的为negative evidence(E??)。然后使用zero-shot-prompt来让大模型基于E++生成多文档总结,作为正确的回答Y。
-
对回答添加噪声:同样使用大模型基于2shot-cot-prompt,来对以上获得的正确答案进行破坏,指令要求大模型先生成修改方案,再对回答进行魔改。魔改包括但不限于魔改实体,魔改语义关系,魔改语法等等,这里论文使用了text-davinci-003,指令和效果如下图


-
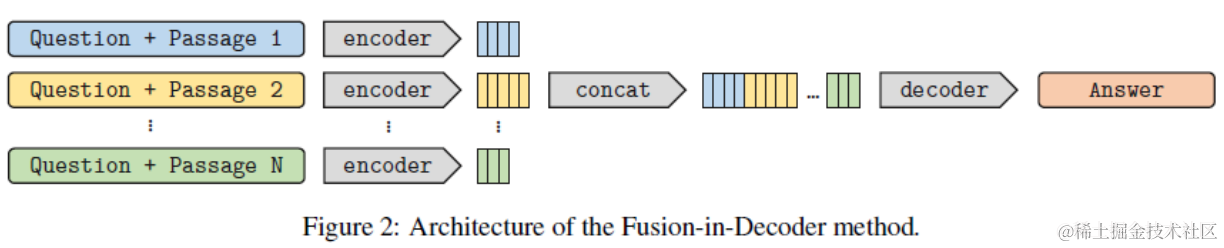
训练T5:微调使用E+�+的事实和添加噪声的回答作为输入,模型目标是把噪声回答修复成正确答案。这里如果E+�+不足4条的会随机采样E?�?这样可以提高模型对噪声事实的识别能力。值得说一下的是这里多个事实并非采用拼接的形式进行融合,而是使用Fusion-in-decoder的形式在encoder层编码后进行拼接,再进入Decoder。
效果上PURR对比RARR,对模型原始回答有更高的保有率(Pres),以及更高的平均归因率(Attr)。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 无需训练让LLM支持超长输入
- 2024PMP考试新考纲-【过程领域】近期典型真题和很详细解析(2)
- 【通讯录案例-延时调用-第三方框架-HUD框架 Objective-C语言】
- LINUX基础培训七之进程管理
- char常见问题之一【C语言】
- Hi5 2.0 虚拟手与追踪器(Tracker)的位置修正
- 1.4 day4 IO进程线程
- [PyTorch][chapter 9][李宏毅深度学习][Why Deep]
- 六、书写命令
- 目标检测系列——Faster R-CNN原理详解