【霹雳吧啦】手把手带你入门语义分割の番外13:U2-Net 源码讲解(PyTorch)—— 损失的计算
目录
前言
文章性质:学习笔记 📖
视频教程:U2-Net 源码讲解(PyTorch)- 3 损失计算
主要内容:根据 视频教程 中提供的 U2-Net?源代码(PyTorch),对 train_and_val.py 文件中的 criterion 函数进行具体讲解。
Preparation
├── src: 搭建网络相关代码
├── train_utils: 训练以及验证相关代码
├── my_dataset.py: 自定义数据集读取相关代码
├── predict.py: 简易的预测代码
├── train.py: 单GPU或CPU训练代码
├── train_multi_GPU.py: 多GPU并行训练代码
├── validation.py: 单独验证模型相关代码
├── transforms.py: 数据预处理相关代码
└── requirements.txt: 项目依赖
 ?
?
?
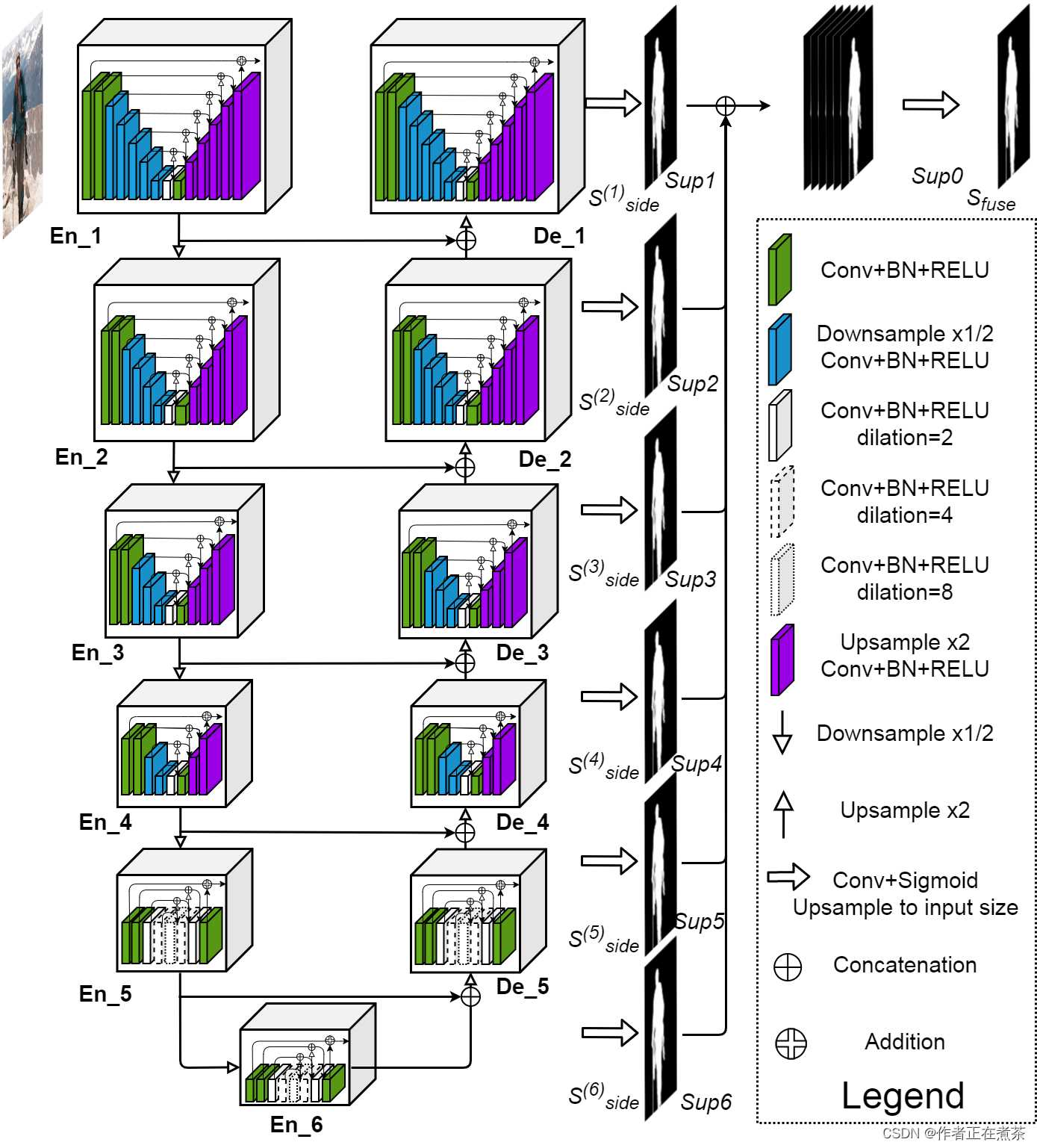
一、U2-Net 网络结构图
原论文提供的 U2-Net 网络结构图如下所示:?
 ??
??
【说明】在 Encoder 阶段,每通过一个 block 后都经 Maxpool 下采样 2 倍,在 Decoder 阶段,每通过一个 block 后都经 Bilinear 上采样 2 倍。U2-Net 网络的核心 block 是 ReSidual U-block,分为具备上下采样的 block 和不具备上下采样的 block:
- 具备了上下采样的 block:Encoder1~Encoder4、Decoder1~Decoder4
- 不具备上下采样的 block:Encoder5、Encoder6、Decoder5
二、U2-Net 网络源代码
1、损失计算
原论文给出了 U2-Net 的损失计算公式:
式中:l 代表 二值交叉熵损失 ,w 代表每个损失的权重,M=6 表示有 Decoder1~Decoder5 和 Encoder6 等 6 个输出。
这个损失函数可以看成两部分, + 前半部分 是来自于不同尺度上的一个输出,令其通过对应的 3x3 卷积层和双线性插值,将其还原回原图尺度,再将得到的 Sup1~Sup6 特征图与手工标注的 Ground Truth 去计算损失,进行加权求和; + 后半部分 是融合后得到的最终的预测概率图与 GT 之间的损失。在源码中,权重 w 全部等于 1 。
2、model.py

【说明】在训练模式下,这里的 x 代表网络最终融合的一个输出,而 side_outputs 则是列表形式,收集了图中所示的?Sup1~Sup6 特征图,注意在训练模式下没有经过 sigmoid 函数,这样做是为了在使用混合精度训练时更加稳定。
3、train_and_eval.py


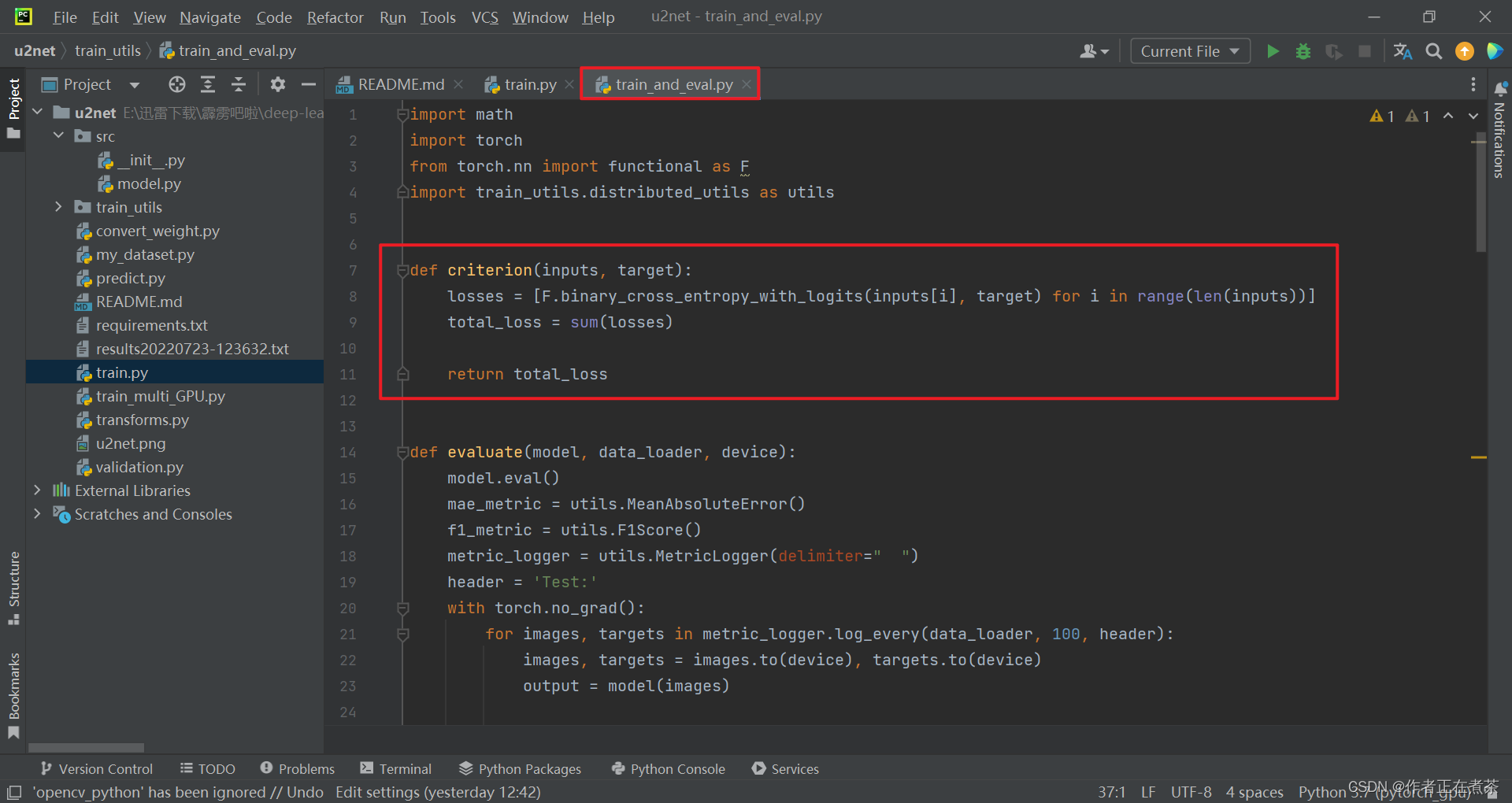
【说明】通过 for 循环去遍历 inputs 列表中的每一项,inputs 列表中存储的就是最终的一个融合预测特征图以及?Sup1~Sup6 特征图,将其与对应的 Ground Truth ,也就是 target ,进行损失计算,采用 F.binary_cross_entropy_with_logits 计算二值交叉熵损失。
附:train_and_eval.py 源代码
import math
import torch
from torch.nn import functional as F
import train_utils.distributed_utils as utils
def criterion(inputs, target):
losses = [F.binary_cross_entropy_with_logits(inputs[i], target) for i in range(len(inputs))]
total_loss = sum(losses)
return total_loss
def evaluate(model, data_loader, device):
model.eval()
mae_metric = utils.MeanAbsoluteError()
f1_metric = utils.F1Score()
metric_logger = utils.MetricLogger(delimiter=" ")
header = 'Test:'
with torch.no_grad():
for images, targets in metric_logger.log_every(data_loader, 100, header):
images, targets = images.to(device), targets.to(device)
output = model(images)
# post norm
# ma = torch.max(output)
# mi = torch.min(output)
# output = (output - mi) / (ma - mi)
mae_metric.update(output, targets)
f1_metric.update(output, targets)
mae_metric.gather_from_all_processes()
f1_metric.reduce_from_all_processes()
return mae_metric, f1_metric
def train_one_epoch(model, optimizer, data_loader, device, epoch, lr_scheduler, print_freq=10, scaler=None):
model.train()
metric_logger = utils.MetricLogger(delimiter=" ")
metric_logger.add_meter('lr', utils.SmoothedValue(window_size=1, fmt='{value:.6f}'))
header = 'Epoch: [{}]'.format(epoch)
for image, target in metric_logger.log_every(data_loader, print_freq, header):
image, target = image.to(device), target.to(device)
with torch.cuda.amp.autocast(enabled=scaler is not None):
output = model(image)
loss = criterion(output, target)
optimizer.zero_grad()
if scaler is not None:
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
else:
loss.backward()
optimizer.step()
lr_scheduler.step()
lr = optimizer.param_groups[0]["lr"]
metric_logger.update(loss=loss.item(), lr=lr)
return metric_logger.meters["loss"].global_avg, lr
def create_lr_scheduler(optimizer,
num_step: int,
epochs: int,
warmup=True,
warmup_epochs=1,
warmup_factor=1e-3,
end_factor=1e-6):
assert num_step > 0 and epochs > 0
if warmup is False:
warmup_epochs = 0
def f(x):
"""
根据step数返回一个学习率倍率因子,
注意在训练开始之前,pytorch会提前调用一次lr_scheduler.step()方法
"""
if warmup is True and x <= (warmup_epochs * num_step):
alpha = float(x) / (warmup_epochs * num_step)
# warmup过程中lr倍率因子从warmup_factor -> 1
return warmup_factor * (1 - alpha) + alpha
else:
current_step = (x - warmup_epochs * num_step)
cosine_steps = (epochs - warmup_epochs) * num_step
# warmup后lr倍率因子从1 -> end_factor
return ((1 + math.cos(current_step * math.pi / cosine_steps)) / 2) * (1 - end_factor) + end_factor
return torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=f)
def get_params_groups(model: torch.nn.Module, weight_decay: float = 1e-4):
params_group = [{"params": [], "weight_decay": 0.}, # no decay
{"params": [], "weight_decay": weight_decay}] # with decay
for name, param in model.named_parameters():
if not param.requires_grad:
continue # frozen weights
if len(param.shape) == 1 or name.endswith(".bias"):
# bn:(weight,bias) conv2d:(bias) linear:(bias)
params_group[0]["params"].append(param) # no decay
else:
params_group[1]["params"].append(param) # with decay
return params_group本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 什么是游戏盾?哪家效果好。
- 机器学习基础实验(人口收入普查数据探索)
- 用js让用户输入一个数累加和
- PFA试剂瓶耐强酸PFA取样瓶可储存高纯水、电子级清洗剂
- 机器学习原理到Python代码实现之NaiveBayes【朴素贝叶斯】
- 2023版本QT学习记录 -3- QT Creat 程序打包
- [c]增高防护塔
- CentOS修改SSH端口号和禁止root用户直接登录
- 使用Kali Linux端口扫描
- Linux系统用户账号的管理