kubeadm
kubeadm来快速的搭建一个k8s集群
二进制搭建适合大集群,50台以上主机。
kubeadm更适合中小企业的业务集群。
我用过的集群是二进制,搭建过adm
master? 192.168.233.91? ? ? 2核4G? /4核8G? ? ? ? docker? ?kubeadm? kubectl? flannel
node1? 192.168.233.92? ? ? ?2核4G? /4核8G? ? ? ? docker? ?kubeadm? kubectl? flannel
node2??192.168.233.93? ? ? ?2核4G? /4核8G? ? ? ? docker? ?kubeadm? kubectl? flannel
Harbor节点:192.168.233.94? 2核4G? ???????????????docker? ?docker-compose? ?docker-harbor
准备环境:
//所有节点,关闭防火墙规则,关闭selinux,关闭swap交换
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
swapoff -a?? ??? ??? ??? ??? ??? ?#交换分区必须要关闭
sed -ri 's/.*swap.*/#&/' /etc/fstab?? ??? ?#永久关闭swap分区,&符号在sed命令中代表上次匹配的结果
#加载 ip_vs 模块
for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;don

//修改主机名
hostnamectl set-hostname master01
hostnamectl set-hostname node01
hostnamectl set-hostname node02
配置主机映射
vim /etc/hosts
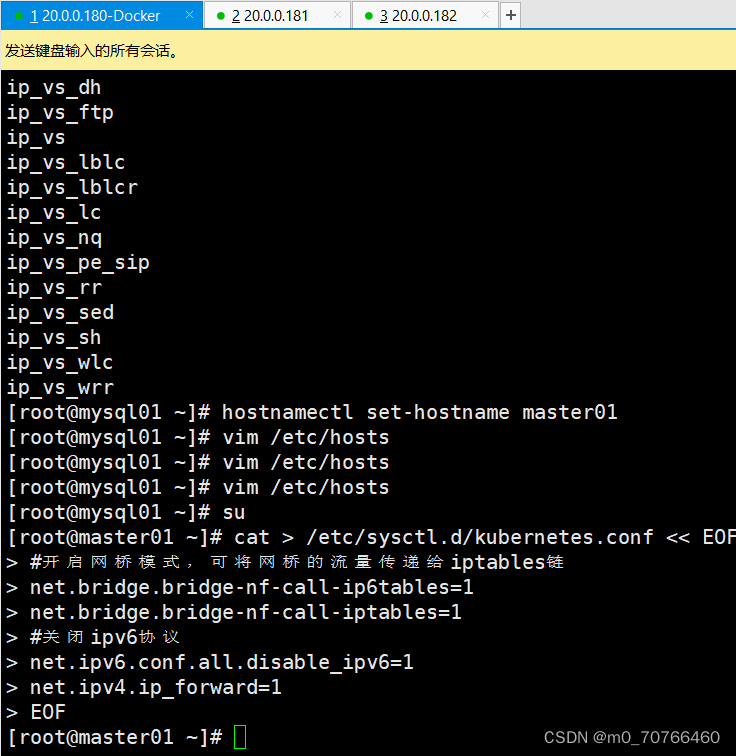
//调整内核参数
cat > /etc/sysctl.d/kubernetes.conf << EOF
#开启网桥模式,可将网桥的流量传递给iptables链
net.bridge.bridge-nf-call-ip6tables=1
net.bridge.bridge-nf-call-iptables=1
#关闭ipv6协议
net.ipv6.conf.all.disable_ipv6=1
net.ipv4.ip_forward=1
EOF
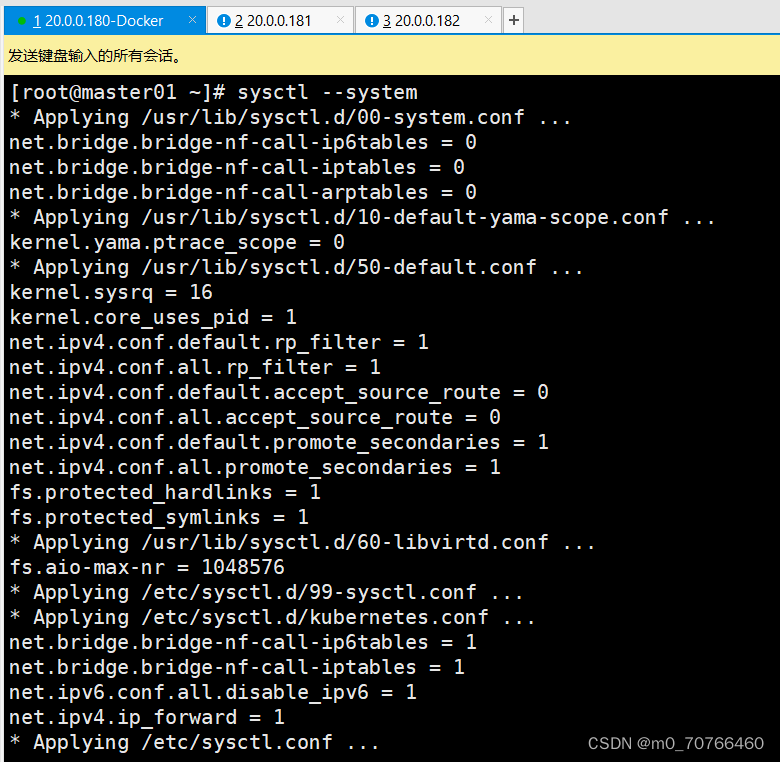
//生效参数
sysctl --system
2、所有节点安装docker
yum install -y yum-utils device-mapper-persistent-data lvm2?
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo?
yum install -y docker-ce docker-ce-cli containerd.io
?
mkdir /etc/docker
cat > /etc/docker/daemon.json <<EOF
{
? "registry-mirrors": ["https://pkm63jfy.mirror.aliyuncs.com"],
? "exec-opts": ["native.cgroupdriver=systemd"],
? "log-driver": "json-file",
? "log-opts": {
? ? "max-size": "100m"
? }
}
EOF
systemctl daemon-reload
systemctl restart docker.service
systemctl enable docker.service?
?
docker info | grep "Cgroup Driver"
Cgroup Driver: systemd

时间同步
yum -y install ntpdate
date

kubeadm的资源控制方式systemd
因此一定要执行


3、所有节点安装kubeadm,kubelet和kubectl ?
//定义kubernetes源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
?
yum install -y kubelet-1.20.15 kubeadm-1.20.15 kubectl-1.20.15
?
//开机自启kubelet
systemctl enable kubelet.service
#K8S通过kubeadm安装出来以后都是以Pod方式存在,即底层是以容器方式运行,所以kubelet必须设置开机自启

//查看初始化需要的镜像
kubeadm config images list --kubernetes-version 1.20.15
k8s.gcr.io/kube-apiserver:v1.20.15
k8s.gcr.io/kube-controller-manager:v1.20.15
k8s.gcr.io/kube-scheduler:v1.20.15
k8s.gcr.io/kube-proxy:v1.20.15
k8s.gcr.io/pause:3.2
k8s.gcr.io/etcd:3.4.13-0
k8s.gcr.io/coredns:1.7.0

kubeadm config images list? --kubernetes-version 1.20.15
pause:特殊的pod。
pause会在节点上创建一个网络命名空间,其他容器可以加入这个网络命名空间。
pod里面的容器可能使用不同的代码和架构编写。可以在一个网络空间里面实现通信。协调这个命名空间里面的资源。(实现pod内容器的兼容性)
kubeadm安装的k8s组件都是以pod的形式运行在kube-system这个命名空间当中。
kubelet node管理器可以进行系统控制。(这个例外)
//在 master 节点上传 v1.20.15.zip 压缩包至 /opt 目录
unzip v1.20.15.zip -d /opt/k8s
cd /opt/k8s/
for i in $(ls *.tar); do docker load -i $i; done
?
//复制镜像和脚本到 node 节点,并在 node 节点上执行脚本加载镜像文件
scp -r /opt/k8s root@node01:/opt
scp -r /opt/k8s root@node02:/opt
for i in $(ls *.tar); do docker load -i $i; done
//初始化kubeadm
kubeadm init \
--apiserver-advertise-address=192.168.233.91 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version=v1.20.15 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=10.244.0.0/16 \
--token-ttl=0
kubeadm init \
> --apiserver-advertise-address=20.0.0.180 \
> --image-repository registry.aliyuncs.com/google_containers \
> --kubernetes-version=v1.20.15 \
> --service-cidr=10.96.0.0/16 \
> --pod-network-cidr=10.244.0.0/16 \
> --token-ttl=0
--apiserver-advertise-address:? ?声明master节点的apiserver的监听地址。
--image-repository registry.aliyuncs.com/google_containers:声明拉取镜像的仓库,使用阿里云。
--kubernetes-version=v1.20.15? k8s集群的版本号
--service-cidr=10.96.0.0/16? 所有service的对外代理地址都是10.96.0.0/16
--pod-network-cidr=10.244.0.0/16:所有pod的ip地址网段
--token-ttl=0:默认的token的有效期,默认是24小时,0表示永不过期。

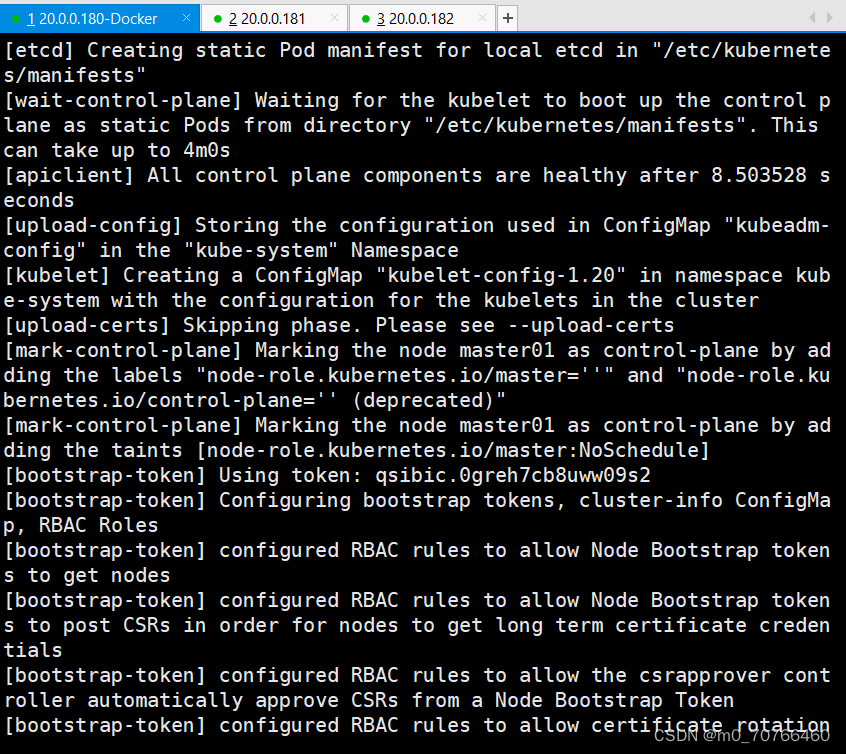
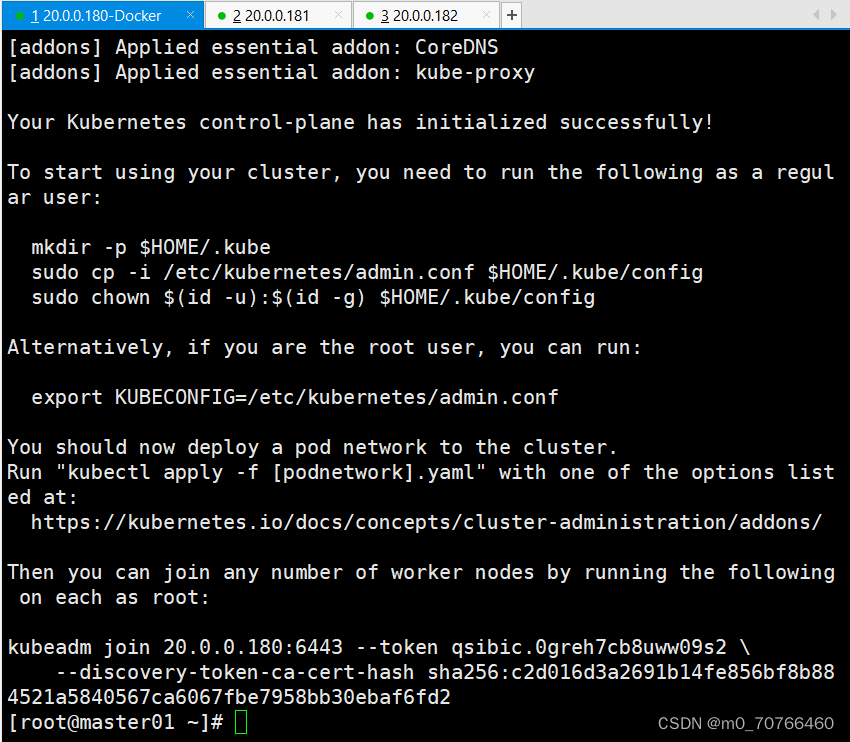
注意:token是随机生成的,让集群加入master节点的代码命令,后面需要用到,需要保存下来
kubeadm join 20.0.0.180:6443 --token qsibic.0greh7cb8uww09s2 \
? ? --discovery-token-ca-cert-hash sha256:c2d016d3a2691b14fe856bf8b884521a5840567ca6067fbe7958bb30ebaf6fd2
#在node节点加入集群
把它复制到两个node节点上
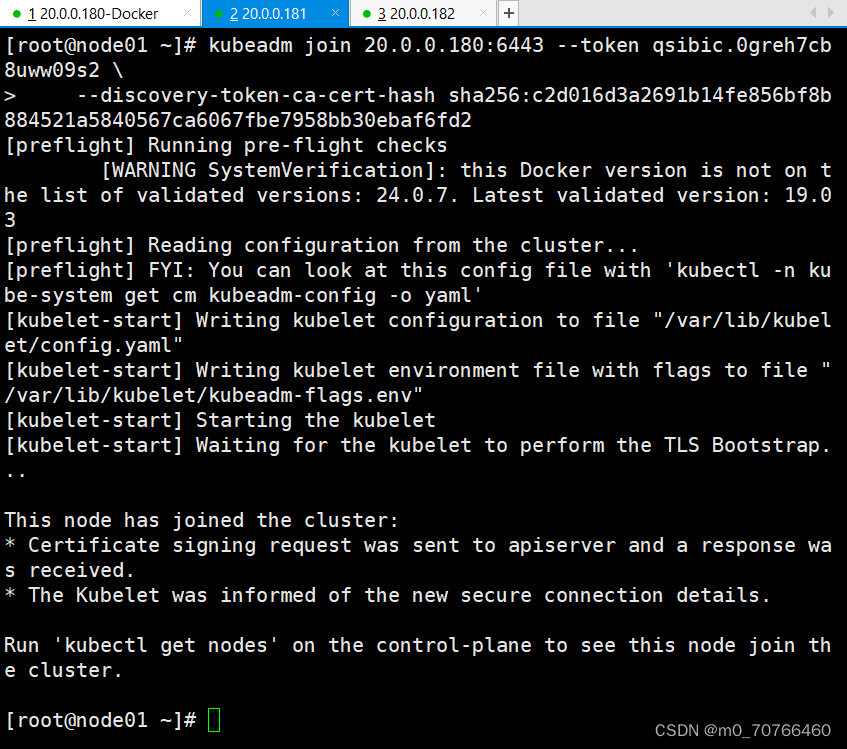
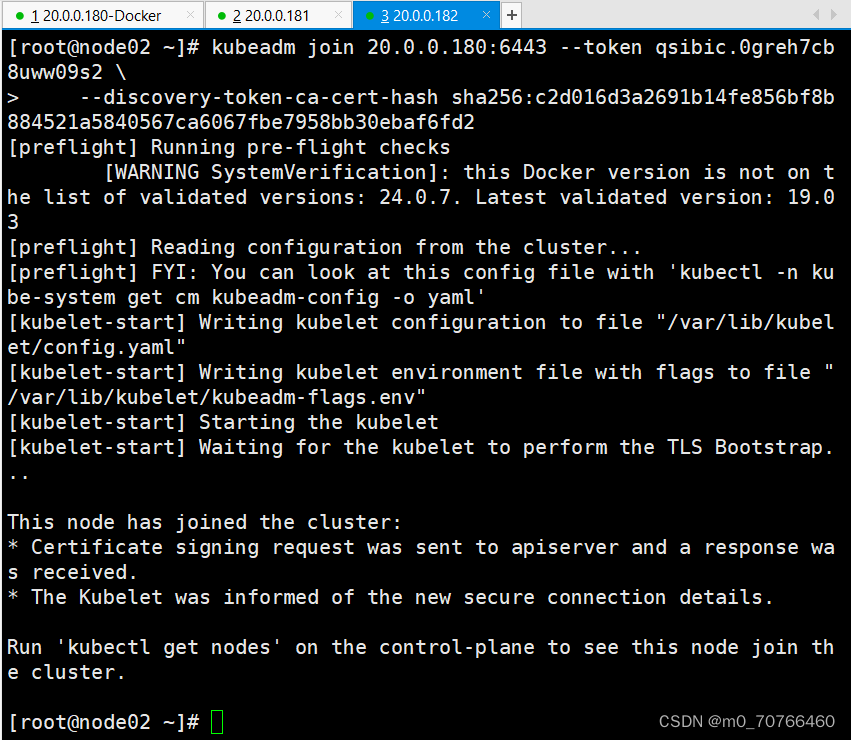
这时候只是apiserver没有起,但是node节点已经加入集群了

起apiserver之前,配置一下环境
//设定kubectl
kubectl需经由API server认证及授权后方能执行相应的管理操作,
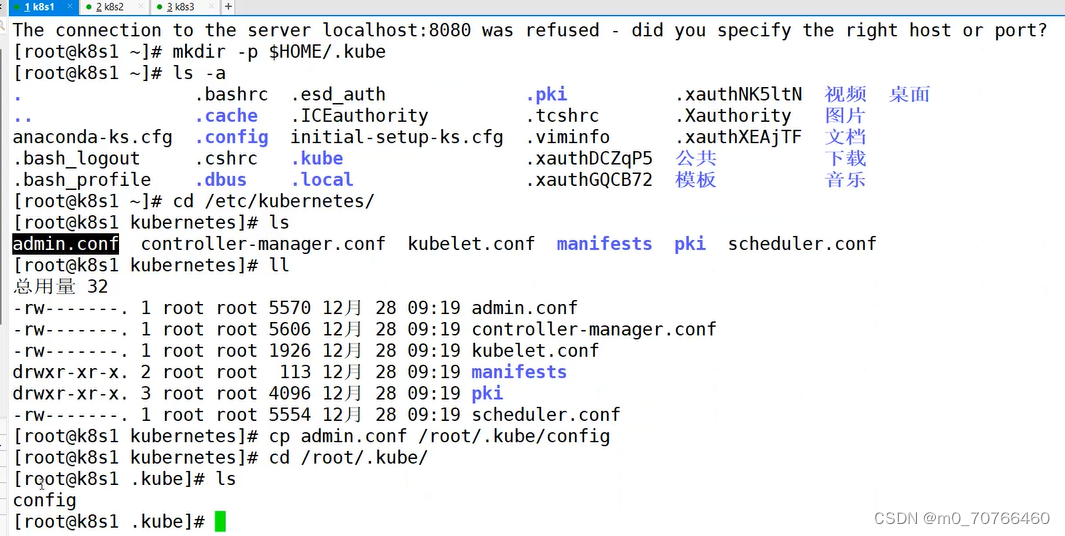
kubeadm 部署的集群为其生成了一个具有管理员权限的认证配置文件 /etc/kubernetes/admin.conf,
它可由 kubectl 通过默认的 “$HOME/.kube/config” 的路径进行加载。
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
systemctl restart kubelet
初始化后需要修改 kube-proxy 的 configmap,开启 ipvs
kubectl edit cm kube-proxy -n=kube-system
修改mode: ipvs

直接搜索mode,改为ipvs即可


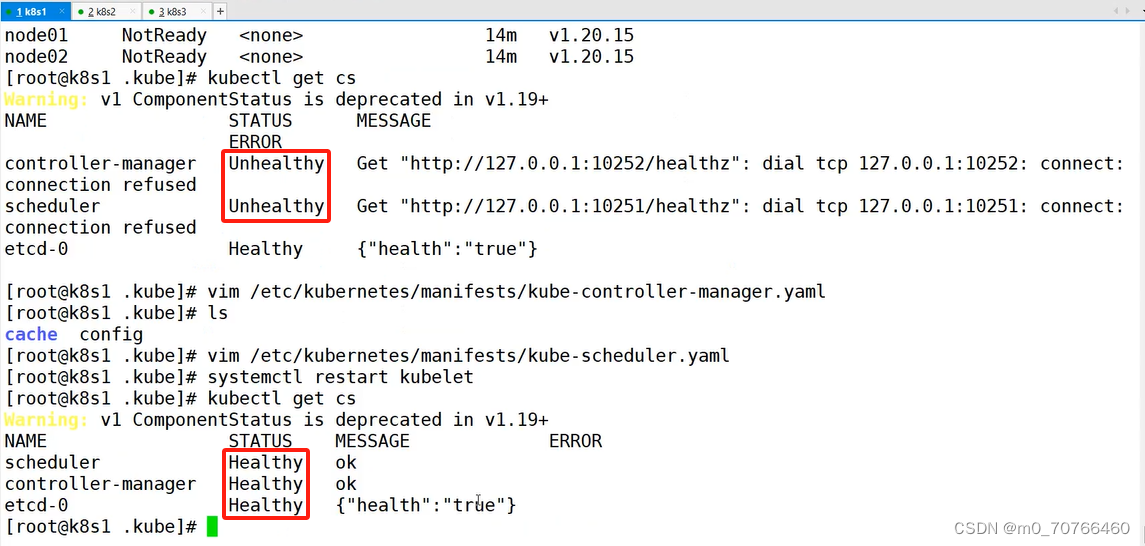
修改完成重启,查看一下node节点,和集群的健康状态

发现controller-manager和schedule的健康状态为unhealthy。错误原因是监听地址不对
接下来我们需要修改一下监听地址
kubectl get cs 发现集群不健康,更改以下两个文件
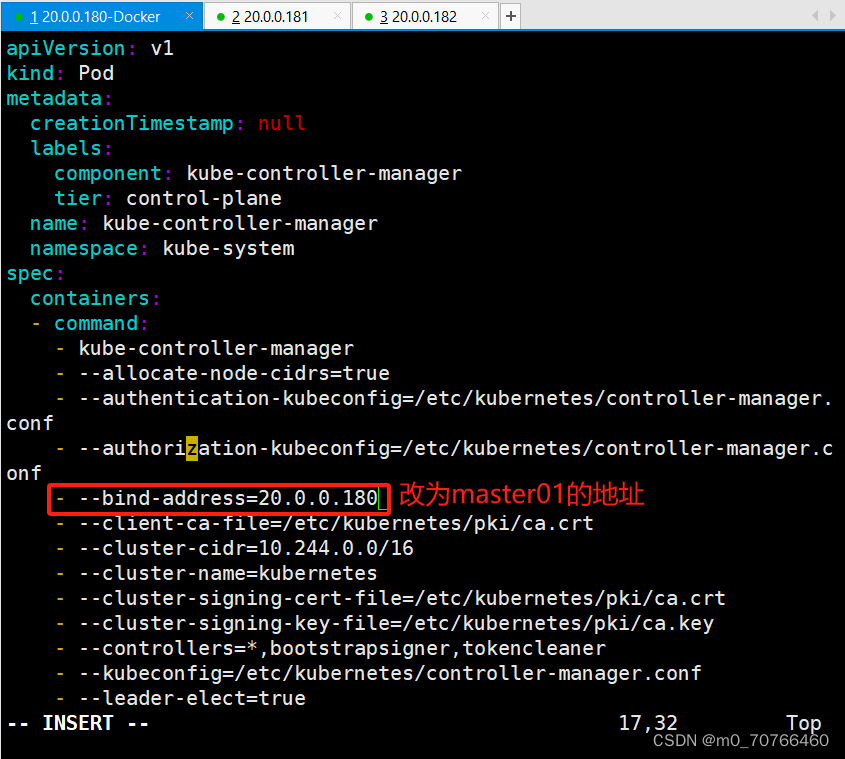
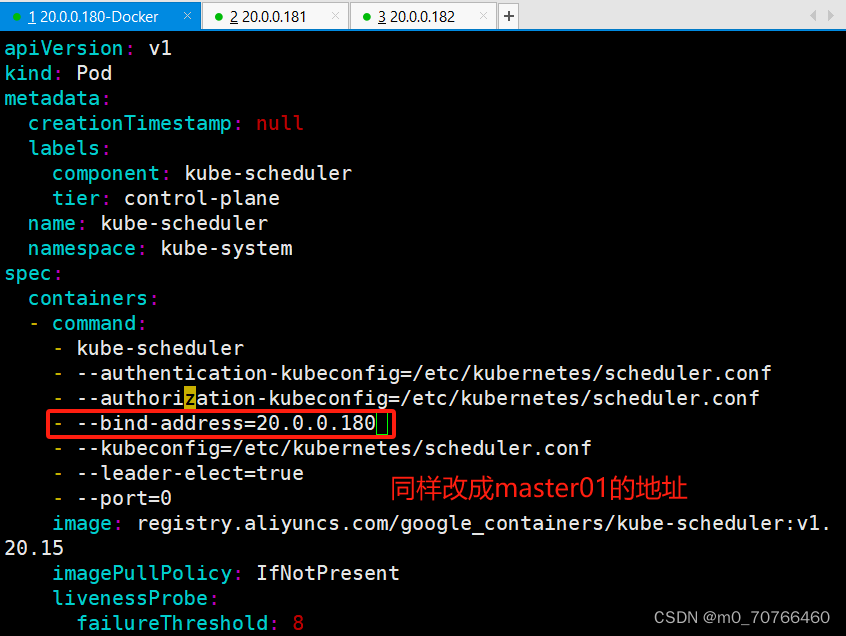
vim /etc/kubernetes/manifests/kube-scheduler.yaml?
vim /etc/kubernetes/manifests/kube-controller-manager.yaml
# 修改如下内容
把--bind-address=127.0.0.1变成--bind-address=192.168.233.91?? ?#修改成k8s的控制节点master01的ip
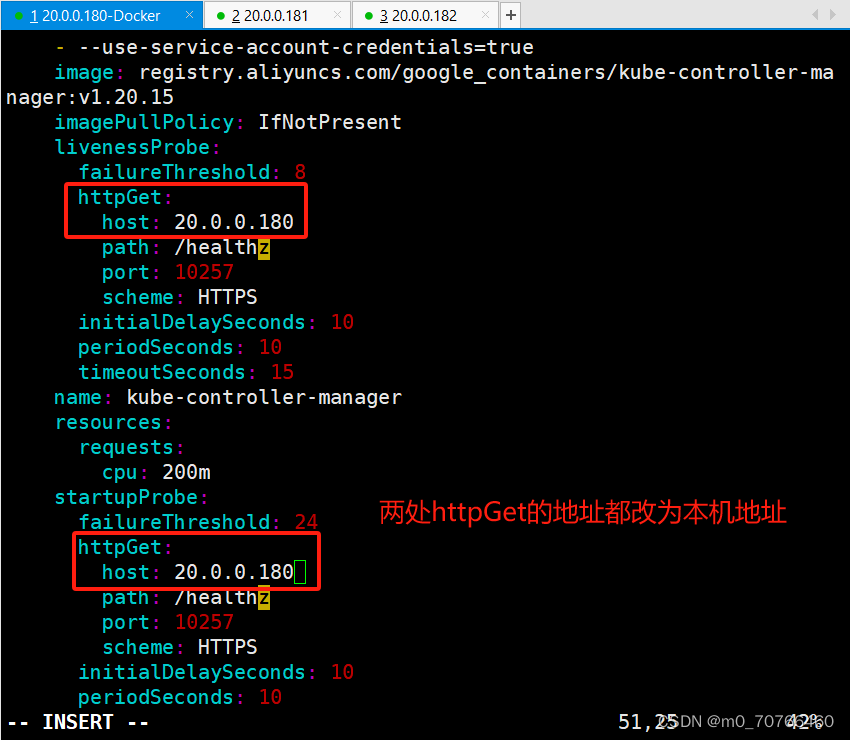
把httpGet:字段下的hosts由127.0.0.1变成192.168.233.91(有两处)
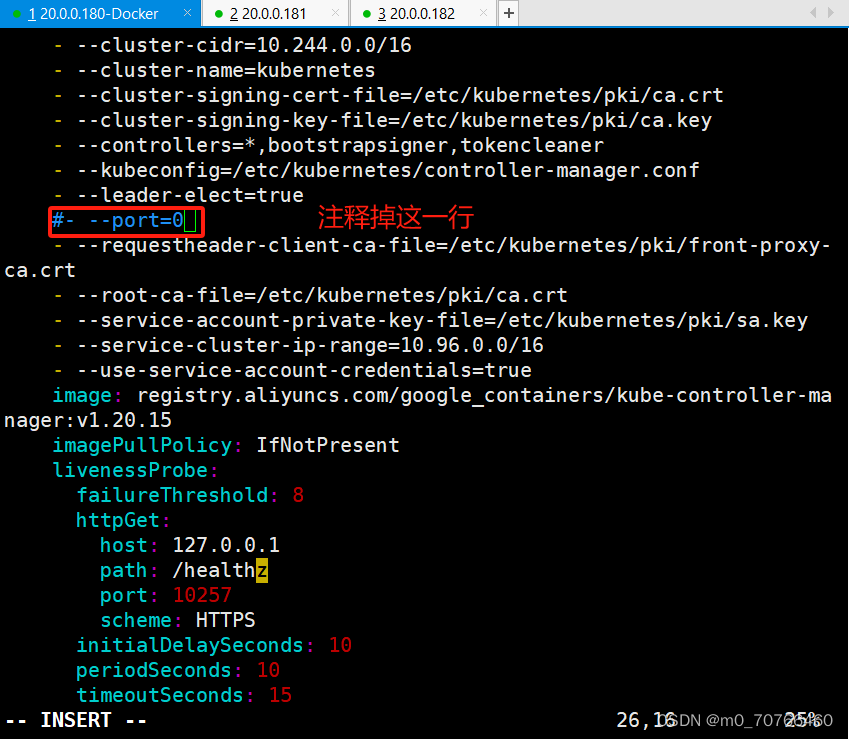
#- --port=0?? ??? ??? ??? ??? ?# 搜索port=0,把这一行注释掉
?
systemctl restart kubelet

vim /etc/kubernetes/manifests/kube-scheduler.yaml?


改完之后重启,重启之后再查看一下,就变为health状态了

接下来开始部署网络
网络部署
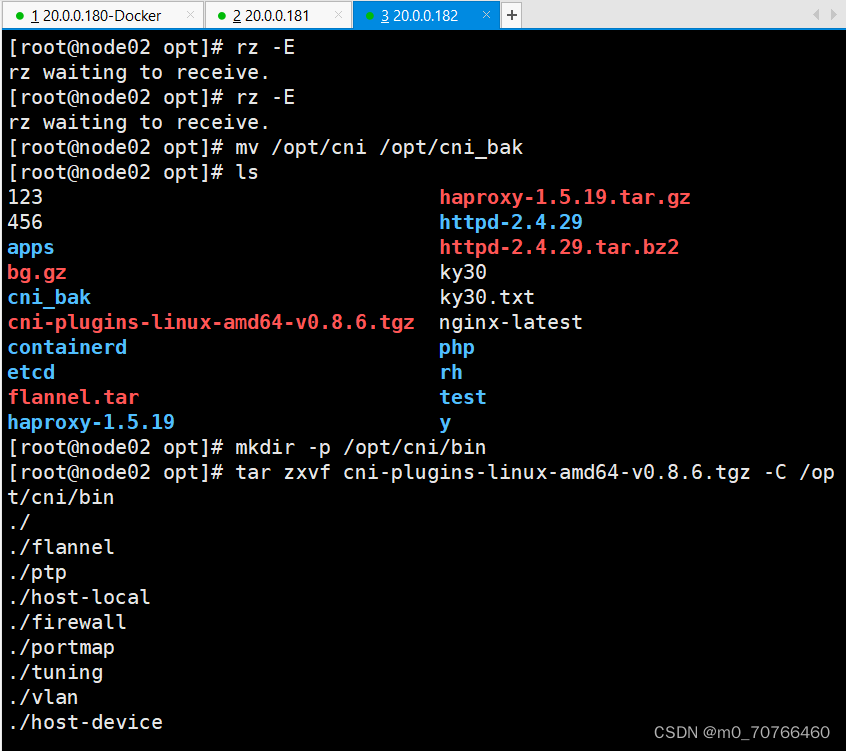
//所有节点上传 flannel 镜像 flannel.tar 和网络插件 cni-plugins-linux-amd64-v0.8.6.tgz 到 /opt 目录
master节点上传 kube-flannel.yml 文件
cd /opt
docker load < flannel.tar
?
mv /opt/cni /opt/cni_bak
mkdir -p /opt/cni/bin
tar zxvf cni-plugins-linux-amd64-v0.8.6.tgz -C /opt/cni/bin

回到node节点

//在 master 节点创建 flannel 资源
kubectl apply -f kube-flannel.yml?

可以不部署master节点
#删除node节点
kubectl delete node master01
![]()
要想保留,重新解压,重新下回来即可


查看状态
#证书有效期的问题,kubeadm默认只有1年:
openssl x509 -in /etc/kubernetes/pki/ca.crt -noout -text | grep Not
openssl x509 -in /etc/kubernetes/pki/apiserver.crt -noout -text | grep Not
./update-kubeadm-cert.sh all
执行脚本即可




这样集群的有效期就变成10年了
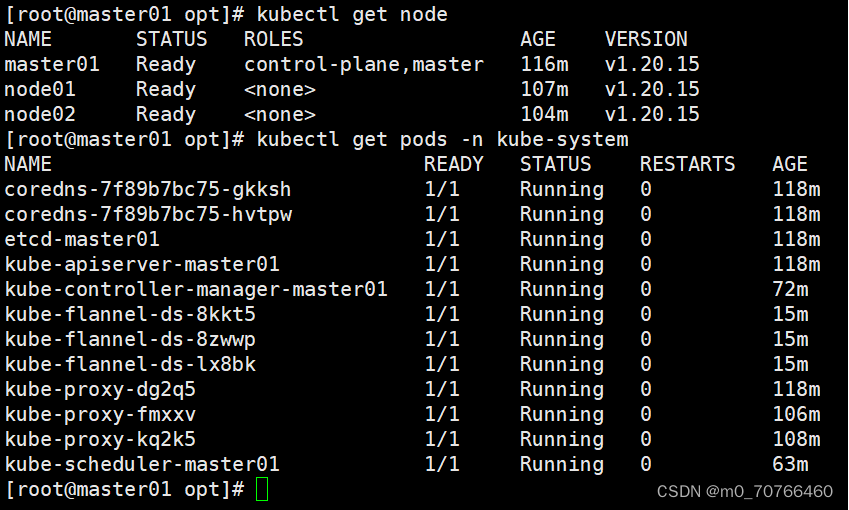
//在master节点查看节点状态
kubectl get nodes
?
kubectl get pods -n kube-system

添加自动补齐的命令
vim /etc/profile
source /etc/profile

这时候的master01既是主,同时它又是一个node节点
//测试 pod 资源创建
kubectl create deployment nginx --image=nginx
?
kubectl get pods -o wide

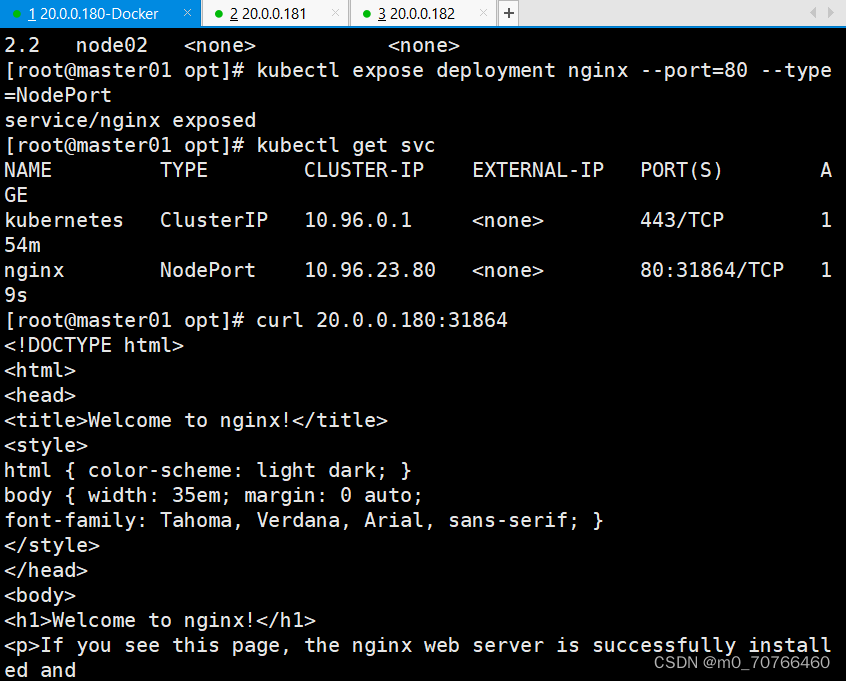
//暴露端口提供服务
kubectl expose deployment nginx --port=80 --type=NodePort
进入pod修改页面
kubectl get svc
//测试访问
curl http://node01:32698
安装 部署与k8s集群对接的Harbor仓库
//上传 harbor-offline-installer-v2.8.1.tgz 和 docker-compose 文件到 /opt 目录
cd /opt
cp docker-compose /usr/local/bin/
chmod +x /usr/local/bin/docker-compose
?
tar zxvf harbor-offline-installer-v2.8.1.tgz
cd harbor/
vim harbor.yml
hostname = hub.test.com
? ?https:
? ? ?# https port for harbor, default is 443
? port: 443
? ? ?# The path of cert and key files for nginx
? ? ?certificate: /data/cert/server.crt
? ? ?private_key: /data/cert/server.key
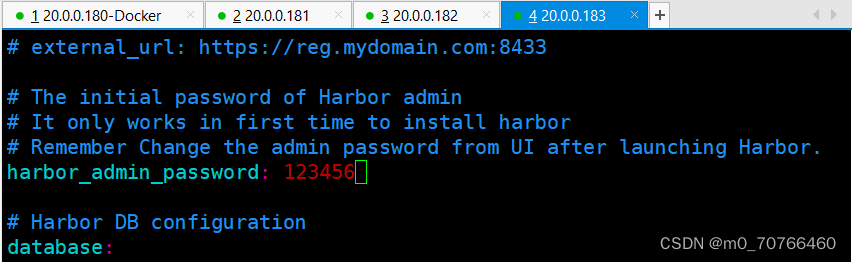
harbor_admin_password = 123456


//生成证书
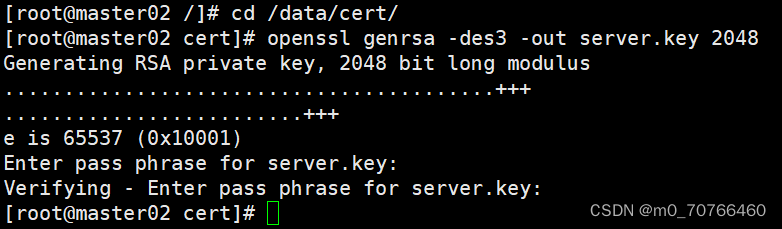
mkdir -p /data/cert
cd /data/cert

#生成私钥
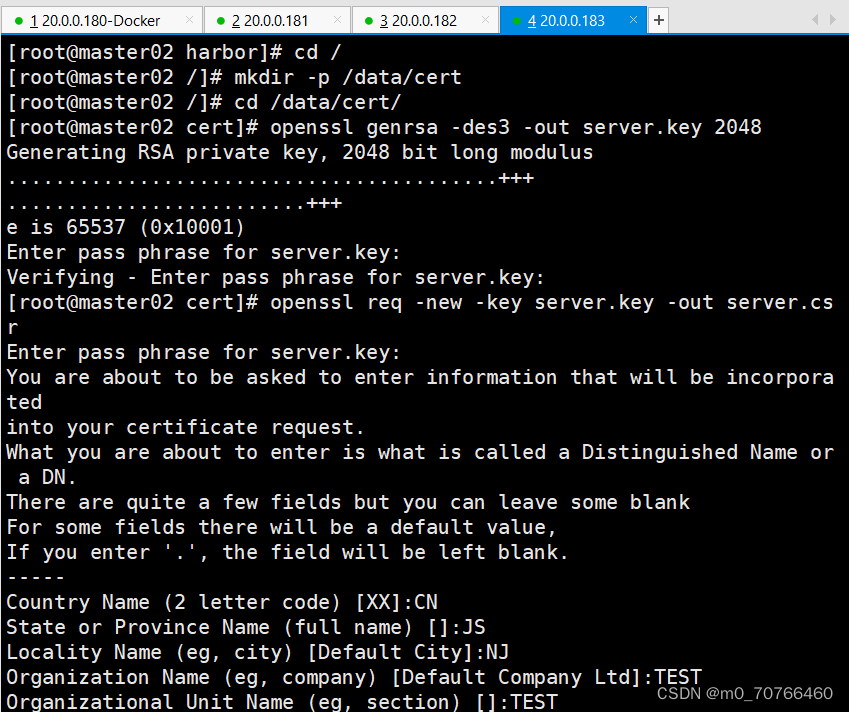
openssl genrsa -des3 -out server.key 2048
输入两遍密码:123456
openssl genrsa: 用于生成 RSA 密钥。
-des3: 使用 Triple DES 加密算法对生成的私钥进行加密。
-out server.key: 指定生成的私钥文件的名称为 server.key。
2048: 指定 RSA 密钥的位数为 2048 位。
#生成证书签名请求文件
openssl req -new -key server.key -out server.csr
输入私钥密码:123456
输入国家名:CN
输入省名:BJ
输入市名:BJ
输入组织名:TEST
输入机构名:TEST
输入域名:hub.kgc.com
输入管理员邮箱:admin@test.com
其它全部直接回车

#备份私钥
cp server.key server.key.org

?
#清除私钥密码
openssl rsa -in server.key.org -out server.key
输入私钥密码:123456

#签名证书
openssl x509 -req -days 1000 -in server.csr -signkey server.key -out server.crt
?
chmod +x /data/cert/*
?
cd /opt/harbor/
./prepare
./install.sh
?
在本地使用火狐浏览器访问:https://192.168.233.94
添加例外 -> 确认安全例外
用户名:admin
密码:123456

回到node节点
mkdir -p? /etc/docker/certs.d/hub.test.com/
kubectl apply -f recommended.yaml
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java项目:11 Springboot的垃圾回收管理系统
- CHS_03.2.1.4+进程控制
- Mybatis-plus分页插件PageHelper的两种不同使用方式
- 【2023我的编程之旅】系统学习C语言easyx图形库心得体会
- 语音合成技术简介
- k8s之对外服务ingress
- 羊奶的制作过程和要点有哪些?
- 【教学类-43-04】20231229 N宫格数独4.0(n=2,4,6,8) (ChatGPT AI对话大师生成 回溯算法)
- freemark--模版引擎
- [三次反转法]循环移动数组元素