【MYSQL】Mysql索引详解
发布时间:2023年12月26日
MySQL索引
MySQL索引
1.什么是索引?
# 概念:一种帮助mysql提高 查询 效率的数据结构
# 类似于我们的字典目录
2.索引的优缺点
# 优点:
大大加快数据的查询速度
# 缺点:
1.维护索引需要消耗数据库资源
2.索引需要占用磁盘空间
3.索引并不是越多越好,当对表数据进行除了查询以外的操作(增删改)的时候,因为要维护索引,所以增删改操作的效率受到影响。
3.索引的分类(四大分类 面试必问)
# InnoDB引擎支持的四大分类
# 1.主键索引
设定主键后数据库会自动建立索引(聚簇索引);
主键索引索引的列值不能为null(非空非重复)
# 2.单列索引(单值/普通索引)非聚簇索引
即:为表里的除了主键之外的列创建索引,一个索引包含一个列,一个表里可以有多个单列索引;
eg:给id列一个索引,给name列一个索引——>id index name index
# 3.唯一索引
索引列的值必须唯一,但可以为null(可空不重复);
唯一索引索引列值可以存在null,但只能存在一个null值
# 4.复合索引
一个索引可以包含多个列;多个列组合在一起共用一个索引
eg:给 name和age两个列一个复合索引——>id (name age) index add
4.索引的创建和删除
4.1主键索引的创建
创建主键的时候,主键索引就被自动创建好了
#创建主键primary key时,自动创建了主键索引
create table user(
id int(3) primary key,
name varchar(12),
age int(3)
);
#查看索引
show index/keys from 表;

4.2.单列索引的创建
- a.建表时创建————> 创建索引列 : key(列)
create table userone(
id int(3) primary key,
name varchar(12),key(name),
age int(3),key(age)
);
#注意:建表后创建索引:我们索引的名字一般命名为 索引列_index;
# 建表时创建索引:我们的索引名默认为索引列名 eg如下图所示
- b.建表后创建
create index 列_index on 表(列);
create index name_index on user(name);
eg:
# 建表时创建普通索引
create table usertwo(
id int(3) primary key,
name varchar(12),key(name),
age int(3),key(age),
address varchar(11)
);
# 建表后创建普通索引
create index address_index on usertwo(address);
show keys from usertwo;

4.3唯一索引的创建
- a.建表时创建 ————> 创建索引列 : unique(列)
# 建表时创建唯一索引 unique 关键字
create table user3(
id int(2) primary key,
name varchar(12),unique(name),
age int(3)
);
- b.建表后创建唯一索引
# 建表后创建唯一索引
create unique index age_index on user3(age);
show index from user3;
#注意:建表后创建索引:我们索引的名字一般命名为 索引列_index;
# 建表时创建索引:我们的索引名默认为索引列名 eg如下图所示

4.4.复合索引的创建
- a.建表时创建 ————> 创建索引列 :key(列1,列2)
# 建表时创建复合索引
create table user4(
id int(2) primary key,
name varchar(12),
age int(3),key(name,age)
);
# 注:最前面的列的名会作为复合索引名

- b.建表后创建
# create index age_name_index on user6(age,name);

# 复合索引面试容易被问的问题:我们基于name,age,address三个字段创建了复合索引
# 查询时候能否利用建立好的索引我们有两个原则
1.最左前缀包含原则(即就是查询的字段一定要含有最左边前缀)
2.查询过程中可以动态调整字段的顺序以便利用索引
- 基于name,address,age查询的时候能否利用索引?---可以
# 底层查询的时候就会动态把name address age调整为name age address
- 基于name,age---可以
- 基于name,address---可以
- 基于name,age,address查询能否利用索引?---可以
- 基于age,address查询能否利用索引?---不行,不满足1
- 基于address,age,name查询能否利用索引?---可以
- 基于address,age---不可以,不满足1
- 基于age,name--可以
4.5.删除索引
Drop index 索引名
4.6.总结索引
-
创建索引
create index 列名_index on 表(列名); # 创建唯一索引时,在create后加上unique即可 -
删除索引
DROP INDEX 索引名
5.索引的底层原理(索引的数据结构----B+树)
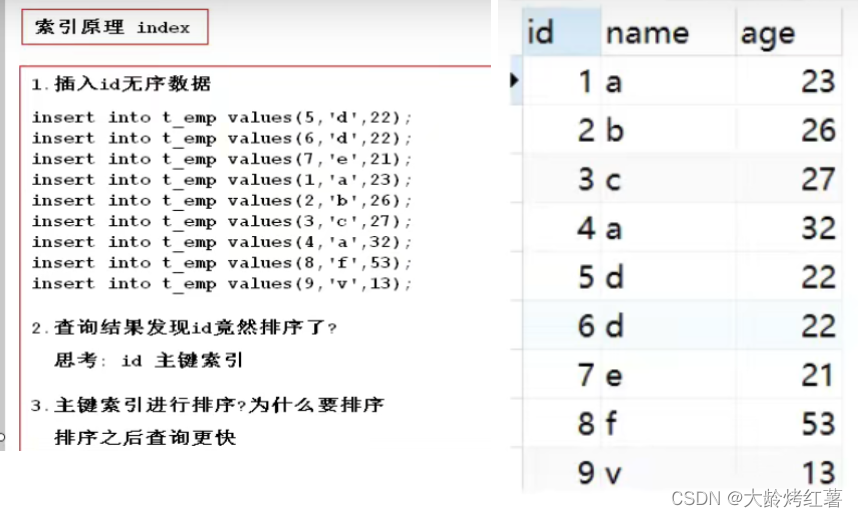
mysql的主键索引为聚簇索引会为我们主动进行排序;
排序的目的就是为了更加方便的查询,假设我们查找id=5的信息,排序后我们只需要按照顺序查找5次就可以,不排序的的话运气好第一次就查到,否则可能会查几百次。
5.1mysql底层存储数据(一般最多三级结构)
# mysql底层存储数据按页(page)进行存储,每页默认存储的大小是16kb,存满以后就会进入下一页进行存储;
页里面存储的内容: 主键索引+表内容+指针
指针:是查找的时候,通往下一个索引的桥梁;
# 页目录:页目录里存储的是每个页里的首元素;查找时通过页目录找到我们要查找的具体页,再在该页里进一步进行查找。
(页目录不存储数据,只存储首元素的主键+指针)
存储该首元素的:主键索引+指针
eg:我们查找id=6的元素,首先在页目录中进行判断,6>1,6<7,所以我们下一步就会到第二页进行精确查找。
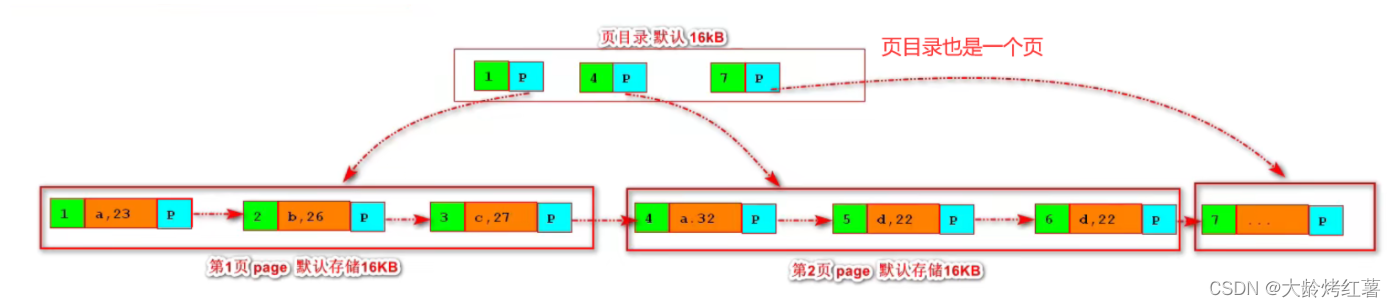
5.2 B+树
# B树遍历不方便,可能会回访某个页码,而B+树是在B树基础上的优化,使得遍历时每个元素只访问一次
B+Tree是在B树基础上的一种优化,使其更适合实现外存储索引结构,InnoDB存储引擎就是用B+Tree实现其索引结构。
B+Tree是在B-Tree(B树)基础上的一种优化,使其更适合实现外存储索引结构,InnoDB存储引擎就是用B+Tree实现其索引结构。
·从B-Tree(B树)结构图中可以看到每个节点中不仅包含数据的key值,还有data值;
·而每一个页的存储空间是有限的,如果data数据较大时将会导致每个节点(即一个页) 能存储的key的数量很小,当存储的数据量很大时同样会导 致B-Tree的深度较大,增大查询时的磁盘I/O次数,进而影响查询效率;
·而在B+Tree中,所有数据记录节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储key值信息,这样可以大大加大每个 节点存储的key值数量,降低B+Tree的高度。
# 在B+树中,叶子节点包含了所有的数据记录以及指向下一个记录的指针;
B+树中,所有数据记录,按照键值大小从小到大顺序链接存放在同一层的叶子节点上。
# B+Tree相对于B-Tree(B树)有几点不同:
1. 非叶子节点只存储键值信息;
2. 所有叶子节点之间都有一个链指针;(所有叶子节点被链指针链接起来)
3. 数据记录(key+data)都存放在叶子节点中;
4. 所有元素只出现一次;
5. 根节点中的关键字在叶子节点再次列出
如下第一个图所示:
InnoDB存储引擎中页的大小为16KB,一般表的主键类型为int(占用4个字节 4byte)或bigInt(占用8个字节 8byte),指针类型也一般为4或8个字节,也就是说一个页(B+Tree中的一个节点)中存储的数据大小为:16kb / (8byte+8byte+数据内容大小)= 1000个键值;
· 就是说一个深度为3的B+Tree索引大概可以维护10^3 * 10^3 * 10^3 = 10亿条记录。
· 实际情况中每个节点可能不能填充满,因此在数据库中,B+Tree的高度一般都在2~4层。mysqI的InnoDB存储引擎在设计时是将根节点常驻内存的,也就是说:查找某一键值的行记录时最多只需要1~3次磁盘I/O操作。
# 第一层一般是常驻内存 不动磁盘I/O;
# 若高度为3(2)层,一般基于主键查询需要2(1)次磁盘I/O操作;(常驻内存不动)
# 基于非主键查询时候,我们得先根据其找到主键(需要一次磁盘I/O)再进行查询,所以得3次磁盘I/O操作;
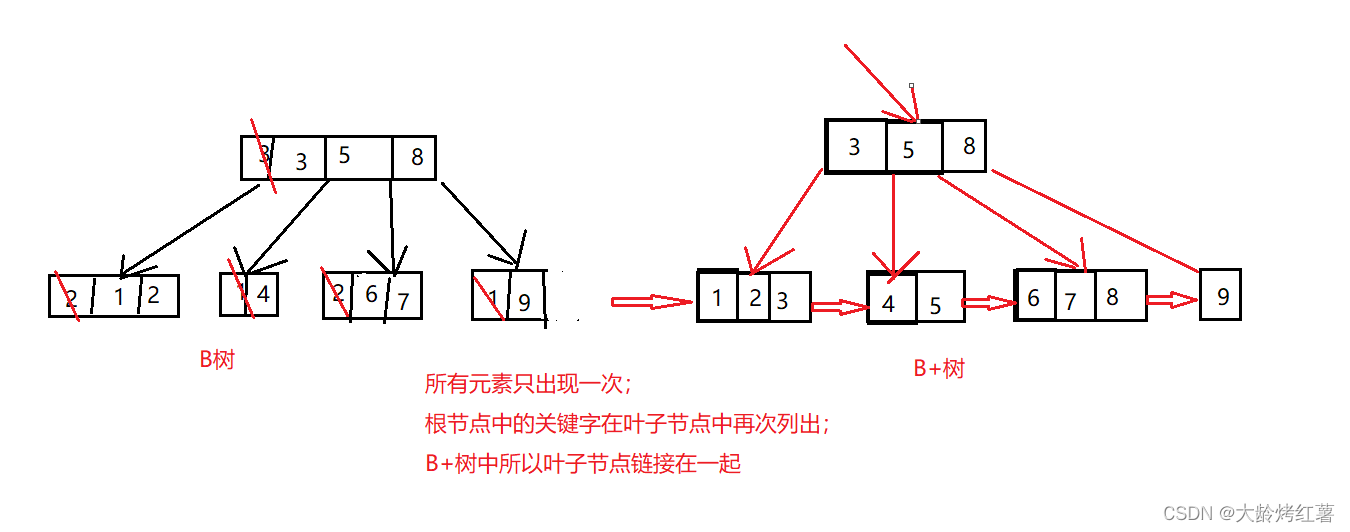
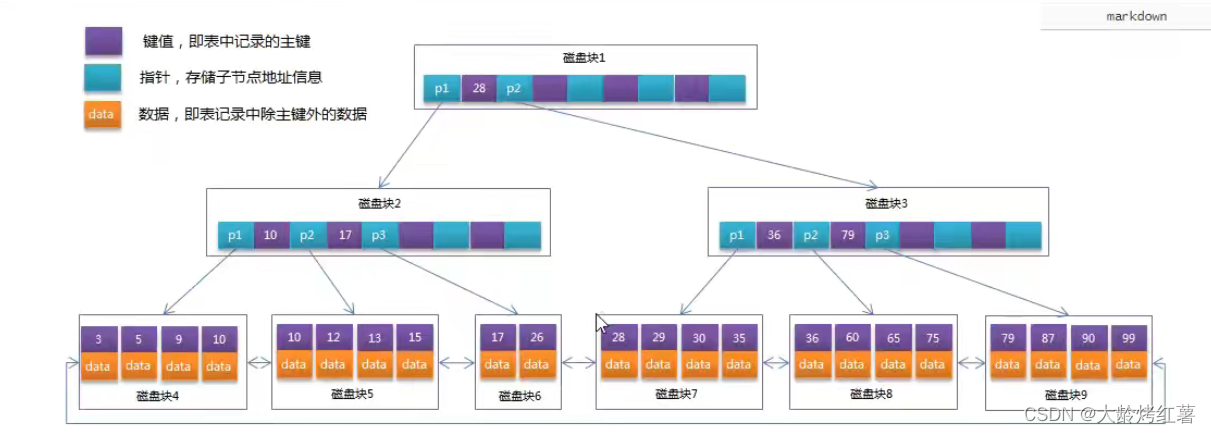
6.聚簇索引与非聚簇索引
# 聚簇索引:数据存储与索引放在一块,索引结构的叶子节点上保存了某行数据;
· 主键索引一定是聚簇索引;但聚簇索引不一定都是主键索引;
· 一个表中只能有一个聚簇索引;剩下的都是非聚簇索引;
# 非聚簇索引: 数据与索引分开存储,索引结构的叶子节点存储的是主键值(主键索引),指向的是数据存储的位置;
# 注意:在innodb中,在聚簇索引之上创建的索引称之为辅助索引;
非聚簇索引都是辅助索引,eg:复合索引、普通索引、唯一索引;
辅助索引叶子节点存储的不是行的物理位置,而是主键值,辅助索引访问数据总是需要二次查找。如下图右图所示
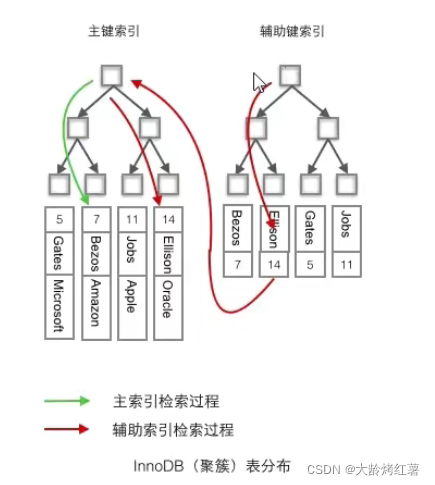
# 聚簇索引的查找:
聚簇索引中数据和索引存放在一起,比如我们之前的id作为主键索引,通过页目录找到对应id存在的页,然后在精确找到相应的id位置,此时在叶子节点上就能找到存储这个索引(id)对应的行信息;(一个叶子节点对应一页,一页上有多条行数据)
# 非聚簇索引的查找:辅助索引访问数据总是需要二次查找
非聚簇索引的数据和索引是分开存放的,比如我们给name这个列建立单列索引(普通索引),也就是我们说的辅助索引,然后我们要根据给出的name找到行信息;
基于name索引(辅助索引)建立的索引树(B+树),根据页目录找到对应name存储的叶子节点,叶子节点不存储信息存储的是name对应的主键索引,也就是说叶子节点存的是id名,然后我们根据id去主键索引所在的索引树上去找对应的信息(此时查找步骤参考聚簇索引的查找
# 答案原文
- ·InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用'where id =14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据;
- ·若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。(重点在于通过其他键需要建立辅助索引)
# 面试问:为什么叶子节点不直接存储数据在另一个索引树上的位置,而是存储对应的主键索引,通过主键索引再一次进行查找呢?
答:因为我们在对数据进行增删改的时候,会改变数据在索引树的位置,所以在辅助索引树叶子节点上存储位置信息反而更加麻烦。
7.InnoDB引擎与MYISAM引擎
# innodb引擎
- 聚簇索引默认是主键,如果表中没有定义主键,InnoDB会选择一个唯一且非空的索引代替。(一般都以主键索引作为聚簇索引)
如果没有这样的索引,InnoDB会隐式定义一个主键(类似oracle中的Rowld)来作为聚簇索引。如果已经设置了主键为聚簇索引又希望再单独设置聚簇索引,必须先删除主键,然后添加我们想要的聚簇索引,最后恢复设置主键即可。(一般没有必要)
# MYISAM引擎(不需要二次查找)
- MyISAM使用的是非聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键辅助键索引B+树存储了辅助键。
表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
8.聚簇索引的优势与注意
8.1使用聚簇索引的优势
- 问题:每次使用辅助索引检索都要经过两次B+树查找,看上去聚簇索引的效率明显要低于非聚簇索引,这不是多此一举吗? # 所以聚簇索引的优势在哪? 1.由于行数据和聚簇索引的叶子节点存储在一起,同一页中会有多条行数据,访问同一数据页不同行记录时,已经把页加载到了Buffer(缓存器)中,再次访问时,会在内存中完成访问,不必访问磁盘。 这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键Id来组织数据,获得数据更快。 2.辅助索引的叶子节点,存储主键值,而不是数据的存放地址。 优点: (1)当行数据放生变化时,索引树的节点也需要分裂变化,或者是我们需要查找的数据,在上一次IO读写的缓存中没有,需要发生一次新的IO操作时,可以避免对辅助索引的维护工作,只需要维护聚簇索引树就好了(增删改的时候不需要维护索引地址); (2)因为辅助索引存放的是主键值,减少了辅助索引占用的存储空间大小。(存储位置比存储主键值占用的空间大)
8.2使用聚簇索引要注意的地方
- 1.当使用主键为聚簇索引时,主键最好不要使用uuid,因为uid的值太过离散,不适合排序且可能出现新增加记录uuid会插入在索引树中间的位置,导致索引树调整复杂度变大,消耗更多的时间和资源。
uuid:(Universally Unique Identifier 全局唯一标识符)指的是一台机器随即生成的32位数字(16进制的)
- 2.建议使用int类型的自增,方便排序并且默认会在索引树的末尾增加主键值(主键自增),对索引树的结构影响最小。
而且因为主键值占用的存储空间越大,辅助索引中保存的主键值也会跟着变大,占用存储空间,也会影响到Io操作读取到的数据量。(int是逐步增大的从1开始,我们最多会到bigInt(8个字节),而uuid一开始就是32位16进制的数字)
8.3为什么主键通常建议用自增id
- 聚簇索引的数据的物理存放顺序是从小到大与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。(也就是说,这页找不到,就直接链接到下一页)
即:若使用自增id,索引的默认排放顺序就是1 2 3 4 .. 而数据的物理存放顺序在叶子节点上也是从小到大排列的这样就保持了一致性。
如果主键不是自增id,那么就要不断地调整数据的物理地址、分页,虽然有其他一些措旒来减少这些操作,但都无法彻底避免。
如果是自增的,它只需要一页一页地写入数据,因而索引结构相对紧凑,磁盘碎片少(磁盘利用率高),效率也高。
磁盘碎片:就是磁盘有空闲,没利用完,剩下的空间就叫磁盘碎片。
9.什么情况下无法利用索引
- 1.查询语句中使用LIKE关键字
在查询语句中使用LIKE关键字进行查询时,如果匹配字符串的第一个字符为%,索引不会被使用;
如果%不是在第一个位置(%在右边),索引就可以被使用。
- 2.查询语句中使用多列索引
多列索引是在表的多个字段上创建一个索引:复合索引
复合索引中:只有查询条件中使用了这些字段中的第一个字段,索引才会被使用。(最左前缀包含原则)
eg:name age bir 建立了一个复合索引
name age bir 可以利用索引
age name bir 可以
bir name age 可以
name bir 可以
name age 可以
age bir 不可以(不包含最左前缀:name)
- 3.查询语句中使用OR关键字
查询语句有OR关键字时,如果oR前后的两个条件列都有索引,那么查询中可使用索引;
如果OR前后有一个条件列没有索引,那么查询中将不能使用索引。
eg:name age 两个单列索引
name and age 可以
name or age 可以 or前后两个列都有索引
name or age or bir 不可以 第二个or后面的列bir无索引
文章来源:https://blog.csdn.net/m0_48904153/article/details/135210822
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- “马屁精”李白
- 钡铼工控机BL302+PLC,助力酿酒业转型升级
- Java填充Execl模板并返回前端下载
- 权限系统模型:RBAC模型与ABAC模型
- 强化学习应用(三):基于Q-learning的物流配送路径规划研究(提供Python代码)
- Java——Java引用数据类型总结!!!
- C语言从入门到实战——动态内存管理
- 【复习】人工智能 第 8 章 人工神经网络及其应用
- 亚马逊,速卖通,国际站测评补单,目前有哪些安全的方式?
- 2.IHRM人力资源 - 登录