关于GPU使用过程中的若干问题
1.CUDA异常
问题描述:运行torch.cuda.is_available()
报错:cuda unknown error - this may be due to an incorrectly set up environment
解决方案:重启
2.nvidia驱动版本不匹配
问题描述:运行nvidis-smi
报错:Failed to initialize NVML: Driver/library version mismatch
解决方案:
- 查看/var/log/apt/history.log,是否有驱动更新记录
- 进行驱动版本的适配
- 驱动版本修改后需要重启才会生效
3.服务器主机acpi报错
问题描述:非正常关机,开机之后报错
报错提示 “ACPI Error: No handler for Region”
1)关闭acpi。步骤如下:
a. 编辑grub菜单项。
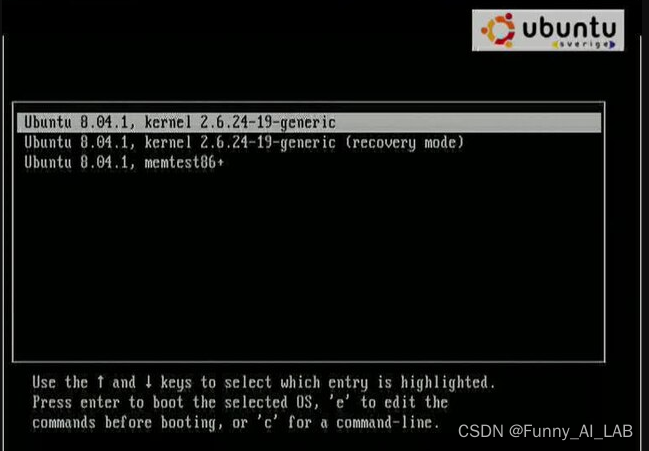
b. 编辑linux命令启动行,在末尾添加 acpi=off
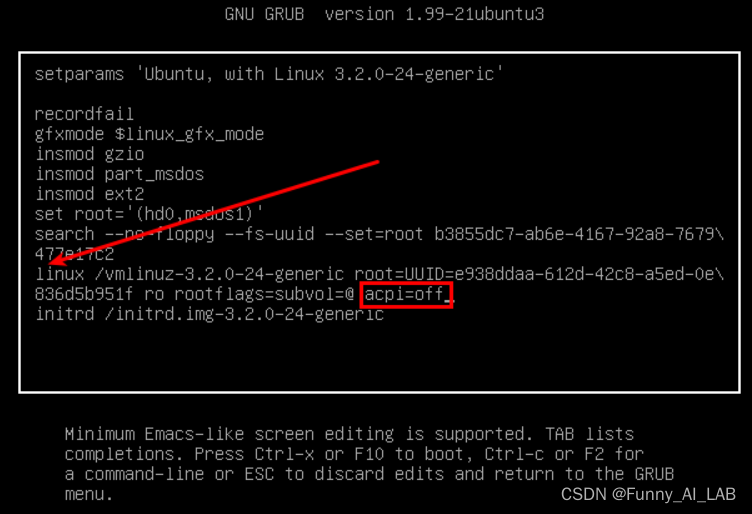
c. 按Ctrl+X 保存重启
重启后,终端提示进入emergency mode。
2)修复磁盘
- 执行 journalctl -xb | grep -C 10 "fsck failed"查看错误行和前后几行
- 找到/dev/…损坏的盘
- 执行umount /dev/…
fsck -y /dev/… - reboot
如果重启后,卡在黑屏界面,光标不停闪烁
3)解决驱动问题
参照1),进入grub菜单项,在linux启动行末尾添加 nomodeset。
重启后正常进入图形桌面。
参考链接:
ubuntu出现emergency mode的解决办法
Ubuntu系统启动过程在遇到的黑屏光标闪烁问题解决
4.Ubuntu系统启动异常
问题描述:Ubuntu 20.04 系统启动后,屏幕显示如下,无法进行其他操作:
A start job is running for Hold until boot process finishes up (xxx min xxx s/no limit
解决方案:
- 编辑/etc/default/grub文件,找到 GRUB_CMDLINE_LINUX_DEFAULT=“quiet splash"配置,改为 GRUB_CMDLINE_LINUX_DEFAULT=”"
- 更新 grub2(sudo update-grub)
参考:
Start Job Running for Hold
5.编译CUDNN时出错
问题描述:NVIDA官方网站下载cuDNN,编译mnistCUDNN时
报错:fatal error: FreeImage.h: No such file or directory
解决方案:
sudo apt-get install libfreeimage3 libfreeimage-dev
参考:
编译mnistCUDNN时出错:fatal error: FreeImage.h: No such file or directory
6.服务器重启黑屏
硬件层面:
观察主机的指示灯
(1)指示灯偏黄,硬件存在问题(内存条有静电,拔出后用橡皮擦擦拭;或GPU松动)
- 电源指示灯黄,闪烁三下再闪烁一下,扣下主板上的纽扣电池,过十五秒后再装上
- 开机出现下面的情况:
开机按F2进入BIOS设置,将SATA Configuration设置为AHCI,保存重启就好!
(2)指示灯白色且无闪烁,表明硬件无问题,可能系统存在问题
系统软件层面
在xshell能操控的情况下,运行nvidia-smi,若无法显示,驱动存在问题,需重装
- 卸载驱动 sudo apt-get purge nvidia*
- 添加源 sudo add-apt-repository ppa:graphics-drivers/ppa
- 更新 sudo apt-get update
- 查看可用驱动 ubuntu-drivers devices
- 安装可用驱动 sudo apt-get install nvidia-430
参考:
Ubuntu辊机开机后显卡挂了
7.GPU服务器启动报错分析
问题描述:
重启t640后,可以通过xshell远程连接,但与服务器无法进入图形界面。
(/var目录空间满)
解决方案:
1).采用sudo init 5, 尝试恢复图形界面。恢复后,界面如下:
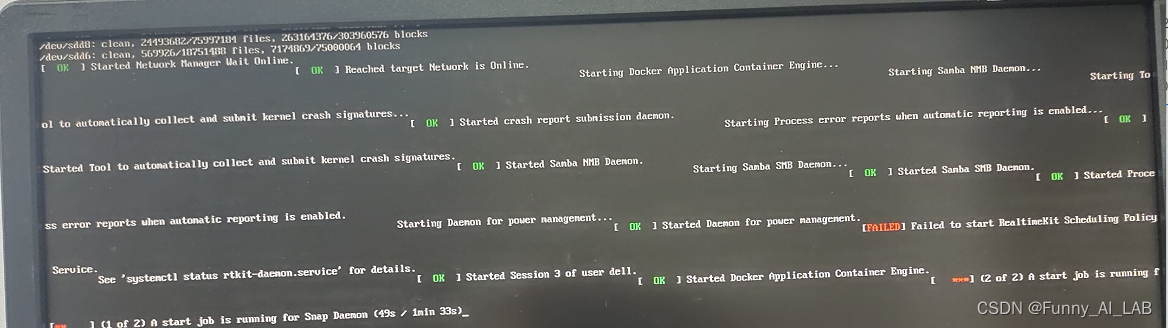 2).查询失败原因,输入:systemctl status rtkit-daemon.service
2).查询失败原因,输入:systemctl status rtkit-daemon.service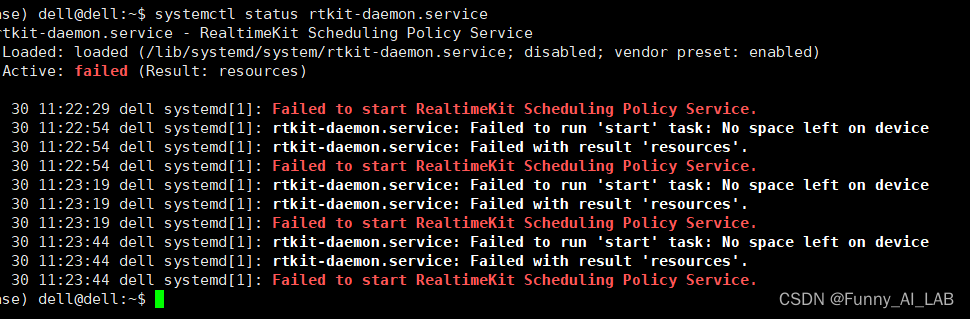
3). 清理空间,主要是清理/home, /opt 下面的数据。 清理完成后,重启机器,发现问题依旧.
4). 再次查看空间及inode,研究inode与磁盘空间的关系,无任何发现.
df -h
df -i
5). 采用journalctl -b 检查启动日志
6). 定位到还是空间不够,但不清楚是在哪个device,经朋友指导,定位到/var空间满, 之前注意到各种/snap开头的满了,以为/var满了没有影响.
7). 清理/var空间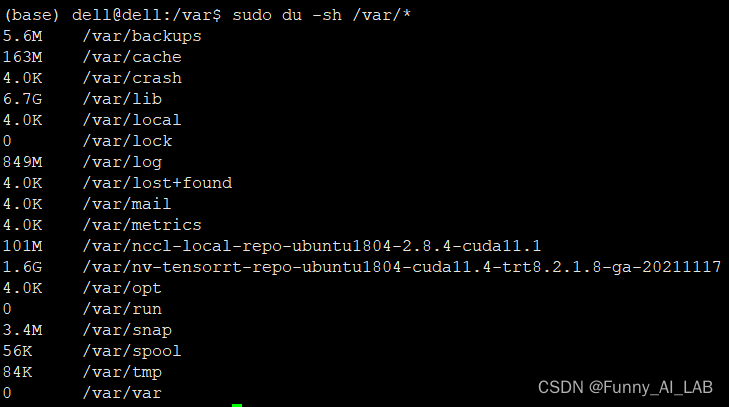
将里面1.6G那个目录移走,并建立软链接如下: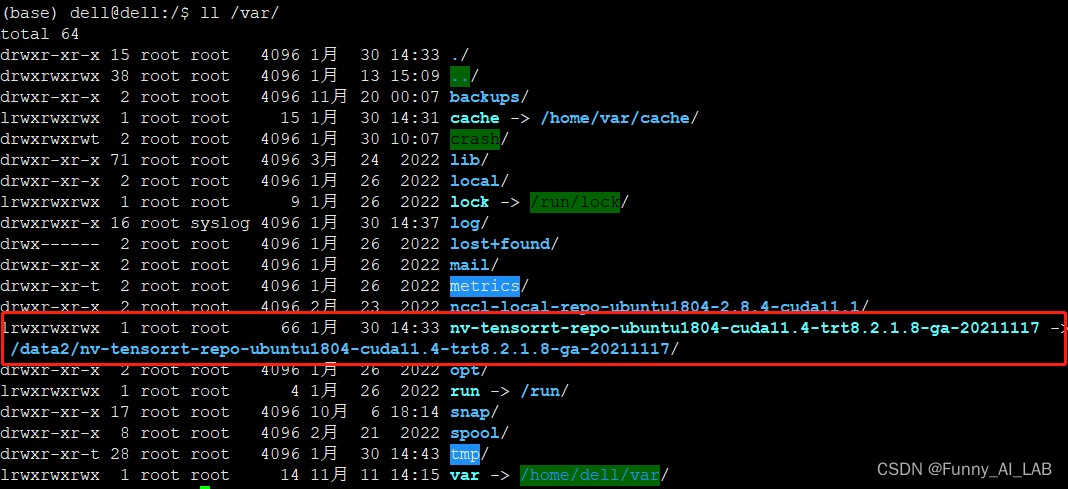
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024年【氧化工艺】试题及解析及氧化工艺操作证考试
- 【实操】基于 GitHub Pages + Hexo 搭建个人博客
- 一条sql是如何运行的
- 安装 Pyqt5 和 Designer
- 从法律的角度看待项目前期可行性研究的必要性
- JS滑块协议逆向
- vscode安装+汉化+配置C/C++环境(保姆级教程!)
- 九州金榜|这样的家庭教育方式有没有你?
- 如果您的助听器弄湿了该怎么办
- 中国数字化进程简史(1980-2022)之二基础网络雏形