【深度学习下载大型数据集】快速下载谷歌云盘数据集
发布时间:2024年01月02日
个人博客:Sekyoro的博客小屋
个人网站:Proanimer的个人网站
跑深度学习的时候,一些数据集比较大,比如60多个G,而且只是训练集.
然后这些数据是由某些实验室组采集的,并不像一些大公司搞的,一般都直接方法一些网盘中.
如果是谷歌网盘,本身通过代理也不麻烦,但是发现即使通过代理,下载的速度也非常慢,如果频繁下载还会被限制.

这里给一个方法,通过租赁廉价服务器下载谷歌云盘的数据集,然后自己再通过公网下载.速度要快一些.
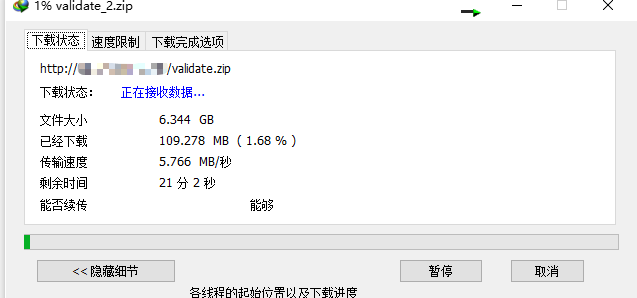
我通过IDM下载谷歌云盘上的大型数据集时速度低的时候可能才五六百KB,
使用这种方法20多G的数据40s左右下载到服务器上

然后搭个nginx,再下回国内.速度6M左右.不会像谷歌云盘那样限速
基本方法
下载到服务器
方法基本想法就是海外服务器下载谷歌云盘上的数据更快(哪怕你用了代理),利用vultr等服务器商租一个服务器,利用google api下载数据.
curl -H "Authorization: Bearer YOUR_ACCESS_TOKEN" https://www.googleapis.com/drive/v3/files/YOUR_FILE?alt=media -o OUTPUT_FILE
token从OAUTH取,授权Drive API v3下的 https://www.googleapis.com/auth/drive.readonly 这样就拿到了token.
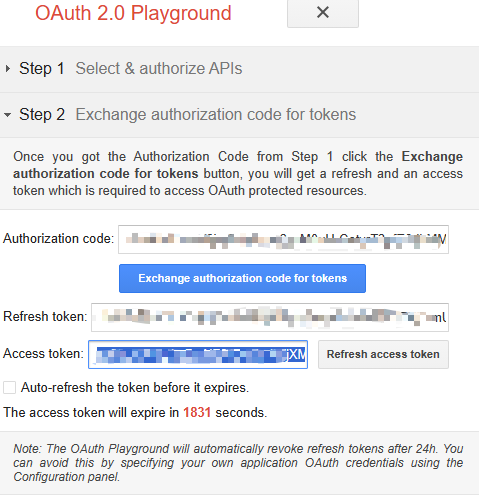
接下来拿云盘上文件的id,
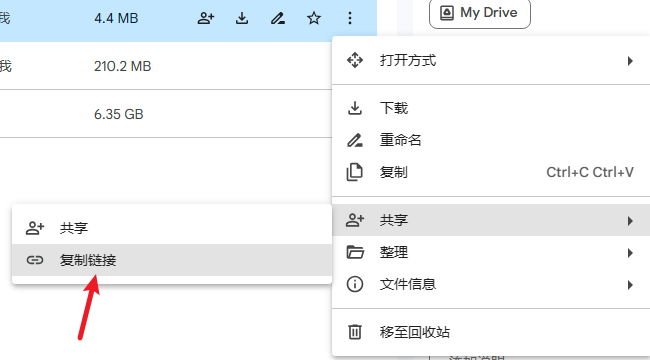
复制的链接的中间有一串独特的id,这就是文件id.
这里要注意的是,如果文件是从别人那直接下载的,还是可能会遇到超额问题,建议保存到自己的网盘下然后拿文件链接
下载到本地
在服务器上搭建一个nginx
sudo ufw app list
sudo ufw allow 'Nginx Full'
把需要下载的文件放在nginx Web根目录(/var/www/html)中,然后根据ip后加上文件名就能直接下载了,一般来说这里的下载速度就要慢一些了,我这里5、6M左右,可以优化这部分速度
参考方法
如有疑问,欢迎各位交流!
服务器配置
宝塔:宝塔服务器面板,一键全能部署及管理
云服务器:阿里云服务器
Vultr服务器
GPU服务器:Vast.ai
文章来源:https://blog.csdn.net/aqwca/article/details/135346774
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【MySQL】sum 函数和 count 函数的相同作用
- 2.3_2 进程互斥的软件实现方法
- 【XR806开发板试用】系列之二 - I2C外设使用及控制OLED屏显示
- 现在AI那么发达,还有必要系统地学习Excel吗?
- 【设计模式】代理模式
- 武理多媒体信息共享平台的架构设计与实现
- 第六章 SpringCloud Alibaba Sentinel–服务容错
- Centos下,使用NFS实现目录共享/网络驱动器
- SpringBoot系列之基于Jedis实现分布式锁
- CVE-2023-49371|RuoYi 若依后台管理系统存在SQL注入漏洞