python绘制热力图-数据处理-VOC数据类别标签分布及数量统计(-代码)
发布时间:2024年01月15日
Python是一种功能强大的编程语言,它提供了许多库和工具,用于处理和可视化数据。在本文中,我们将介绍使用Python绘制热力图,并对VOC数据集中的类别标签进行分布及数量统计。
首先,我们需要导入所需的库。使用`numpy`库来处理数据,`matplotlib`库来绘制热力图。
import numpy as np
import matplotlib.pyplot as plt接下来,我们需要加载VOC数据集并获取类别标签信息。VOC数据集是一个常用的用于目标检测任务的数据集,其中包含了多个类别的物体标注信息。
假设我们已经加载了VOC数据集,并将类别标签保存在一个名为`labels`的列表中。我们可以使用`numpy`库的`unique`函数获取不重复的类别标签,并使用`numpy`库的`count_nonzero`函数统计每个类别的数量。
labels = [...] ?# VOC数据集的类别标签
unique_labels, label_counts = np.unique(labels, return_counts=True)现在,我们可以绘制热力图来可视化类别标签的分布情况。热力图可以直观地显示不同类别的数量。
# 创建一个空的矩阵,大小为类别标签的数量
heatmap = np.zeros((len(unique_labels),))
# 将每个类别的数量填充到矩阵中
for label, count in zip(unique_labels, label_counts):
? ? heatmap[label] = count
# 绘制热力图
plt.imshow([heatmap], cmap='hot')
plt.colorbar()
plt.xlabel('Label')
plt.ylabel('Count')
plt.title('VOC Dataset Label Distribution')
plt.show()运行以上代码,我们就可以得到一个热力图,横轴表示类别标签,纵轴表示数量统计。颜色越深表示数量越多。
通过绘制热力图,我们可以更好地了解VOC数据集中各个类别的分布情况。这对于分析数据集的特点、优化模型的训练等都非常有帮助。
总结起来,本文介绍了如何使用Python绘制热力图,并对VOC数据集中的类别标签进行分布及数量统计。通过可视化数据,我们可以更好地理解和分析数据集,为后续的任务提供指导和参考。
前言
当你需要统计训练数据中每个类别标签有多少,并且想知道坐标中心分布在图像的位置信息时,你可以利用一下脚本进行计算!
步骤
要绘制热力图来分析VOC数据的分布统计,可以按照以下步骤进行:
?
- 数据处理:首先,你需要读取VOC数据集的标注文件,可以使用Python中的XML解析库(如xml.etree.ElementTree)或者专门用于处理VOC数据集的工具库(如vocparse)来解析XML文件。解析后,你可以获取每个样本的标注信息,包括目标类别、边界框位置等。
- 统计数据分布:遍历所有样本的标注信息,统计每个类别在图像中出现的次数或占比。根据需要,你可以选择统计全局的数据分布,或者针对特定区域或图像子集进行统计。将统计结果存储在一个二维数组或字典中,以便后续生成热力图。
- 绘制热力图:根据统计结果,使用Python中的数据可视化库(如matplotlib、seaborn等)来绘制热力图。热力图可以使用颜色来表示数据的密度或占比。一种常见的绘制方法是使用imshow函数,传入统计结果的二维数组,设置合适的颜色映射和标签等。
代码块?
import os
import xml.etree.ElementTree as ET
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.pyplot as plt
# VOC数据集路径
dataset_path = 'Annotations/'
# 存储标签及其对应的目标框数量
label_counts = {}
image_width = 1280
image_height = 960
block_size = 40
# 创建一个二维数组,用于存储每个块中目标框的数量
block_counts = np.zeros((image_height // block_size, image_width // block_size))
# 遍历数据集中的每个XML文件
i=0
for filename in os.listdir(dataset_path):
if filename.endswith('.xml'):
# 解析XML文件
tree = ET.parse(os.path.join(dataset_path, filename))
root = tree.getroot()
# 遍历XML文件中的所有目标框
for obj in root.findall('object'):
label = obj.find('name').text
if label=='vehicle':
xmin = int(float(obj.find('bndbox/xmin').text))
ymin = int(float(obj.find('bndbox/ymin').text))
xmax = int(float(obj.find('bndbox/xmax').text))
ymax = int(float(obj.find('bndbox/ymax').text))
x_pixel = int((xmin + ymin) / 2)
y_pixel = ymax
# 将底部中心点映射到相应的像素块
block_x = x_pixel // block_size
block_y = y_pixel // block_size
# 统计该像素块中目标框的数量
block_counts[block_y, block_x] += 1
i+=1
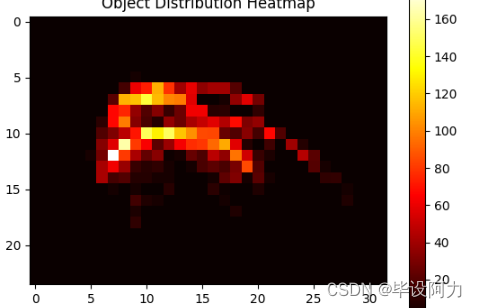
plt.imshow(block_counts, cmap='hot')
plt.colorbar()
# 设置坐标轴
plt.xlabel('Blocks (50x50 pixels)')
plt.ylabel('Blocks (50x50 pixels)')
plt.title('Object Distribution Heatmap')
# 显示热力图
plt.show()
print(block_counts)
print("该标签有",i)
?
代码讲解
- 在进行VOC数据集的类别标签分布和数量统计时,有以下几个需要注意的点:
- 数据集路径:确保设置正确的数据集路径,指向包含XML文件的文件夹。
- 标签统计:使用一个字典或其他适合的数据结构来存储每个标签及其对应的目标框数量。可以使用标签作为键,目标框数量作为值。
- XML解析:使用适当的XML解析库(如xml.etree.ElementTree)解析XML文件。检查XML文件中的标签结构,并定位到目标框的位置信息。
- 目标框位置信息:目标框通常由左上角和右下角的坐标表示(例如xmin、ymin、xmax、ymax)。确保正确提取这些坐标,并转换为适当的格式。
- 统计目标框数量:根据目标框的位置信息,可以将它们映射到图像的像素块中,并在相应的像素块中递增目标框数量。这样就可以统计每个像素块中目标框的数量。
- 绘制热力图:使用合适的可视化库(如matplotlib.pyplot)绘制热力图,以展示目标分布情况。热力图的颜色可以根据目标框数量的大小进行渐变。
- 坐标轴和标题:设置适当的坐标轴标签和标题,以说明热力图的含义和解释。
- 显示热力图:使用适当的函数(如plt.show())显示生成的热力图。
?
import os # 导入os模块,用于文件操作
import xml.etree.ElementTree as ET # 导入xml.etree.ElementTree模块,用于解析XML文件
import matplotlib.pyplot as plt # 导入matplotlib.pyplot模块,用于绘图
import numpy as np # 导入numpy模块,用于科学计算
VOC数据集路径
dataset_path = 'Annotations/'
存储标签及其对应的目标框数量
label_counts = {}
图像的宽度和高度
image_width = 1280
image_height = 960
每个像素块的大小
block_size = 40
创建一个二维数组,用于存储每个块中目标框的数量
block_counts = np.zeros((image_height // block_size, image_width // block_size))
遍历数据集中的每个XML文件
?
i = 0
for filename in os.listdir(dataset_path):
if filename.endswith('.xml'):
# 解析XML文件
tree = ET.parse(os.path.join(dataset_path, filename))
root = tree.getroot()
# 遍历XML文件中的所有目标框
for obj in root.findall('object'):
label = obj.find('name').text
# 判断标签是否为'vehicle'
if label == 'vehicle':
# 获取目标框的坐标信息
xmin = int(float(obj.find('bndbox/xmin').text))
ymin = int(float(obj.find('bndbox/ymin').text))
xmax = int(float(obj.find('bndbox/xmax').text))
ymax = int(float(obj.find('bndbox/ymax').text))
# 计算目标框的底部中心点坐标
x_pixel = int((xmin + ymin) / 2)
y_pixel = ymax
# 将底部中心点映射到相应的像素块
block_x = x_pixel // block_size
block_y = y_pixel // block_size
# 统计该像素块中目标框的数量
block_counts[block_y, block_x] += 1
i += 1
绘制热力图
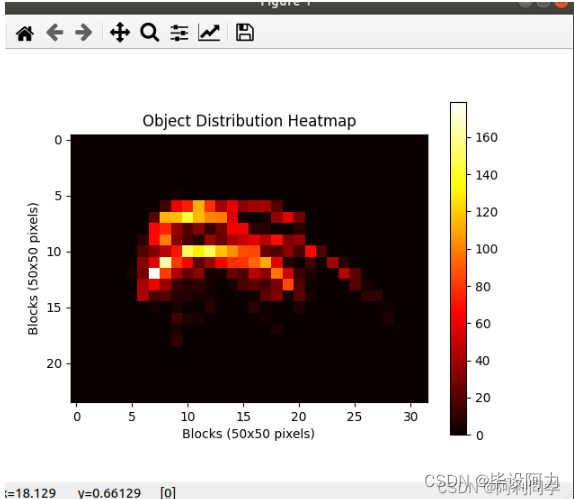
plt.imshow(block_counts, cmap='hot')
plt.colorbar()
设置坐标轴和标题
plt.xlabel('Blocks (50x50 pixels)')
plt.ylabel('Blocks (50x50 pixels)')
plt.title('Object Distribution Heatmap')

显示热力图?
plt.show()
print(block_counts)
print("该标签有", i)
#联系 qq 767172261

文章来源:https://blog.csdn.net/2301_78240361/article/details/135593443
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 力扣● 435. 无重叠区间 ● 763.划分字母区间 ● 56. 合并区间
- python/c++ Leetcode题解——1.两数之和
- 24年春招要来了,大学生第一次实习去大厂重要么?
- vue3.0规范学习记录
- 开源攻防武器项目
- scss是什么?安装使用的步骤是?有哪几大特性?
- 普通的GET和POST请求
- Debugger断点调试以及相应面板介绍
- 自适应均衡化图片
- java springboot 内存级数据库 H2 创建表并添加数据演示