DS|哈夫曼编码及应用
题目一:DS树 -- 赫夫曼树的构建与编码
题目描述:
给定n个权值,根据这些权值构造huffman树,并进行huffman编码
注意数组访问是从位置1开始
要求:赫夫曼的构建中,默认左孩子权值不大于右孩子权值
输入要求:
第一行先输入n,表示有n个权值,即有n个叶子
第二行输入n个权值,权值全是小于1万的正整数
输出要求:
逐行输出每个权值对应的编码,格式如下:权值-编码
即每行先输出1个权值,再输出一个短划线,再输出对应编码
接着下一行输出下一个权值和编码,以此类推
输入样例:
5
15 4 4 3 2
输出样例:
15-1
4-010
4-011
3-001
2-000代码示例:
#include <iostream>
#include <string>
#include <cstring>
#include <iomanip>
#include <algorithm>
#include <cmath>
using namespace std;
#define MAXCODELEN 15
#define MAXHUFFMANCODENO 10
#define MAXCODESTRINGLEN 100
typedef struct {
int weight;
int parent, lChild, rChild;
char code[MAXCODELEN];
} HTNode, * HumffanTree;
HTNode HT[2 * MAXHUFFMANCODENO];
void Select(int pos, int* s1, int* s2) {
int w1, w2, i;
w1 = w2 = 100010;
*s1 = *s2 = 0;
for (i = 1; i <= pos; i++) {
if (HT[i].weight < w1 && HT[i].parent == 0) {
w2 = w1;
*s2 = *s1;
w1 = HT[i].weight;
*s1 = i;
}
else if (HT[i].weight < w2 && HT[i].parent == 0) {
w2 = HT[i].weight;
*s2 = i;
}
}
}
void CreateHuffmanTree(int n, int* w) {
int m, s1, s2;
m = 2 * n - 1;
//为Huffman树的叶子结点赋值
for (int i = 1; i <= n; i++) {
HT[i].weight = w[i - 1];
HT[i].parent = 0;
HT[i].lChild = HT[i].rChild = 0;
}
//为Huffman的内部节点赋值
for (int i = n + 1; i <= m; i++) {
HT[i].weight = 0;
HT[i].parent = HT[i].lChild = HT[i].rChild = 0;
}
for (int i = n + 1; i <= m; i++) {
Select(i - 1, &s1, &s2);
HT[s1].parent = i; HT[s2].parent = i;
HT[i].lChild = s1; HT[i].rChild = s2;
HT[i].weight = HT[s1].weight + HT[s2].weight;
}
}
void HuffmanCoding(int n){
int j, m, c, f, start;
// 存放每个字符的编码序列
char cd[MAXCODELEN];
m = MAXCODELEN;
// 编码结束符
cd[m - 1] = 0;
for (int i = 1; i <= n; i++) {
// 编码结束符位置
start = m - 1;
//从叶子到根逆向求每个字符的编码
for (c = i, f = HT[i].parent; f != 0; c = f, f = HT[f].parent) {
if (HT[f].lChild == c) cd[--start] = '0';
else cd[--start] = '1';
}
//将每个字符的Huffman编码存放起来
for (j = 0; j < m - start; j++) HT[i].code[j] = cd[start + j];
HT[i].code[j] = 0;
}
}
int main() {
int n;
cin >> n;
int* array = new int[n];
for (int i = 0; i < n; i++) cin >> array[i];
CreateHuffmanTree(n, array);
HuffmanCoding(n);
for (int i = 1; i <= n; i++) {
cout << HT[i].weight << "-" << HT[i].code << endl;
}
return 0;
}题目二:DS树 -- 赫夫曼树解码
题目描述:
已知赫夫曼编码算法和程序,在此基础上进行赫夫曼解码
可以增加一个函数:int ?Decode(const string codestr, char txtstr[]);//输入编码串codestr,输出解码串txtstr
该方法如果解码成功则返回1,解码失败则返回-1,本程序增加宏定义ok表示1,error表示-1
赫夫曼解码算法如下:
定义指针p指向赫夫曼树结点,指针i指向编码串,定义ch逐个读取编码串的字符
初始操作包括读入编码串str,设置p指向根结点,i为0表示指向串首,执行以下循环:
1)取编码串的第i个字符放入ch
2)如果ch是字符0,则p跳转到左孩子;如果ch是字符1,则p跳转到右孩子;如果ch非0非1,表示编码串有错误,报错退出
3)如果p指的结点是叶子,输出解码字符,p跳回根结点,i++,跳步骤1
4)如果p指的结点不是叶子且i未到编码串末尾,i++,跳步骤1
5)如果p指的结点不是叶子且i到达编码串末尾,报错退出
当i到达编码串末尾,解码结束。
输入要求:
第一行先输入n,表示有n个叶子
第二行输入n个权值,权值全是小于1万的正整数
第三行输入n个字母,表示与权值对应的字符
第四行输入k,表示要输入k个编码串
第五行起输入k个编码串
输出要求:
每行输出解码后的字符串,如果解码失败直接输出字符串“error”,不要输出部分解码结果
输入样例:
5
15 4 4 3 2
A B C D E
3
11111
10100001001
00000101100
输出样例:
AAAAA
ABEAD
error代码示例:
#include <iostream>
#include <string>
#include <cstring>
#include <iomanip>
#include <algorithm>
#include <cmath>
using namespace std;
#define MAXCODELEN 15
#define MAXHUFFMANCODENO 10
#define MAXCODESTRINGLEN 100
typedef struct {
char ch;
int weight;
int parent, lChild, rChild;
char code[MAXCODELEN];
} HTNode, * HumffanTree;
HTNode HT[2 * MAXHUFFMANCODENO];
void Select(int pos, int* s1, int* s2) {
int w1, w2, i;
w1 = w2 = 100010;
*s1 = *s2 = 0;
for (i = 1; i <= pos; i++){
if (HT[i].weight < w1 && HT[i].parent == 0){
w2 = w1;
*s2 = *s1;
w1 = HT[i].weight;
*s1 = i;
}
else if (HT[i].weight < w2 && HT[i].parent == 0){
w2 = HT[i].weight;
*s2 = i;
}
}
}
void CreateHuffmanTree(int n, char* c, int* w) {
int m, s1, s2;
m = 2 * n - 1;
//为Huffman树的叶子结点赋值
for (int i = 1; i <= n; i++) {
HT[i].ch = c[i - 1];
HT[i].weight = w[i - 1];
HT[i].parent = 0;
HT[i].lChild = HT[i].rChild = 0;
}
//为Huffman的内部节点赋值
for (int i = n + 1; i <= m; i++) {
HT[i].weight = 0;
HT[i].parent = HT[i].lChild = HT[i].rChild = 0;
}
for (int i = n + 1; i <= m; i++) {
Select(i - 1, &s1, &s2);
HT[s1].parent = i; HT[s2].parent = i;
HT[i].lChild = s1; HT[i].rChild = s2;
HT[i].weight = HT[s1].weight + HT[s2].weight;
}
}
void HuffmanCoding(int n)
{
int j, m, c, f, start;
// 存放每个字符的编码序列
char cd[MAXCODELEN];
m = MAXCODELEN;
// 编码结束符
cd[m - 1] = 0;
for (int i = 1; i <= n; i++) {
// 编码结束符位置
start = m - 1;
//从叶子到根逆向求每个字符的编码
for (c = i, f = HT[i].parent; f != 0; c = f, f = HT[f].parent) {
if (HT[f].lChild == c) cd[--start] = '0';
else cd[--start] = '1';
}
//将每个字符的Huffman编码存放起来
for (j = 0; j < m - start; j++) HT[i].code[j] = cd[start + j];
HT[i].code[j] = 0;
}
}
int ShowHuffmanDecode(int n, string str, string& st)
{
int c, Root;
Root = 2 * n - 1;
c = Root;
for (int i = 0; i < str.size(); i++) {
if (str[i] == '0')
c = HT[c].lChild;
else
c = HT[c].rChild;
if ((HT[c].lChild == 0) && (HT[c].rChild == 0)) {
st += HT[c].ch;
c = Root;
}
}
if (HT[c].parent != 0) return 0;
else return 1;
}
int main() {
int n;
cin >> n;
char* arr = new char[n];
int* array = new int[n];
for (int i = 0; i < n; i++) cin >> array[i];
for (int i = 0; i < n; i++) cin >> arr[i];
CreateHuffmanTree(n, arr, array);
HuffmanCoding(n);
int t;
cin >> t;
while (t--) {
string s, st = "";
cin >> s;
if (!ShowHuffmanDecode(n, s, st)) cout << "error" << endl;
else cout << st << endl;
}
return 0;
}题目三:DS树 -- 带权路径和
题目描述:
二叉树的创建使用含空树表示的先序遍历序列,计算一棵二叉树的带权路径总和,即求赫夫曼树的带权路径和。
已知一棵二叉树的叶子权值,该二叉树的带权路径和WPL等于叶子权值乘于根节点到叶子的分支数,然后求总和。
如下图中,叶子都用大写字母表示,权值对应为:A-7,B-6,C-2,D-3
树的带权路径和 = 7*1 + 6*2 + 2*3 + 3*3 = 34
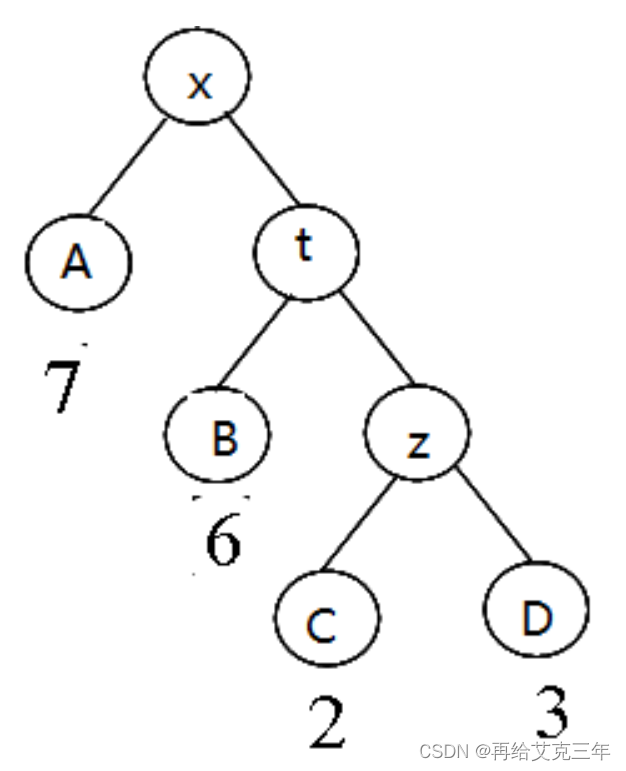
输入要求:
第一行输入一个整数t,表示有t个二叉树
第二行输入一棵二叉树的先序遍历结果,空树用字符‘0’表示,注意输入全是英文字母和0,其中大写字母表示叶子
第三行先输入n表示有n个叶子,接着输入n个数据表示n个叶子的权值,权值的顺序和前面输入的大写字母顺序对应
以此类推输入下一棵二叉树
输出要求:
输出每一棵二叉树的带权路径和
输入样例:
2
xA00tB00zC00D00
4 7 6 2 3
ab0C00D00
2 10 20
输出样例:
34
40代码示例:
#include <iostream>
#include <string>
#include <cstring>
#include <iomanip>
#include <algorithm>
#include <cmath>
#include <queue>
using namespace std;
struct BNode {
char data;
BNode* lChild;
BNode* rChild;
};
class BTree {
public:
BNode* root;
BTree() :root(NULL) {}
BNode* creatBTree() {
BNode* tmp;
char ch;
cin >> ch;
if (ch == '0') tmp = NULL;
else {
tmp = new BNode;
tmp->data = ch;
tmp->lChild = creatBTree();
tmp->rChild = creatBTree();
}
return tmp;
}
void CountWeight(BNode* cur, int level, int& sum) {
int weight;
if (cur != NULL) {
if (cur->data >= 'A' && cur->data <= 'Z') {
cin >> weight;
sum += weight * level;
}
else{
level++;
CountWeight(cur->lChild, level, sum), CountWeight(cur->rChild, level, sum);
}
}
}
};
int main() {
int t;
cin >> t;
while (t--) {
int count = 0;
BTree tree;
tree.root = tree.creatBTree();
int n;
cin >> n;
int sum = 0;
tree.CountWeight(tree.root, 0, sum);
cout << sum << endl;
}
return 0;
}题目四:DS树 -- 二叉树之最大路径
题目描述:
给定一颗二叉树的逻辑结构(先序遍历的结果,空树用字符‘0’表示,例如AB0C00D00),建立该二叉树的二叉链式存储结构
二叉树的每个结点都有一个权值,从根结点到每个叶子结点将形成一条路径,每条路径的权值等于路径上所有结点的权值和。编程求出二叉树的最大路径权值。如下图所示,共有4个叶子即有4条路径,
路径1权值=5 + 4 + 11 + 7 = 27????????路径2权值=5 + 4 + 11 + 2 = 22
路径3权值=5 + 8 + 13 = 26??????????????路径4权值=5 + 8 + 4 + 1 = 18
可计算出最大路径权值是27。
该树输入的先序遍历结果为ABCD00E000FG00H0I00,各结点权值为:
A-5,B-4,C-11,D-7,E-2,F-8,G-13,H-4,I-1

输入要求:
第一行输入一个整数t,表示有t个测试数据
第二行输入一棵二叉树的先序遍历,每个结点用字母表示
第三行先输入n表示二叉树的结点数量,然后输入每个结点的权值,权值顺序与前面结点输入顺序对应
以此类推输入下一棵二叉树
输出要求:
每行输出每棵二叉树的最大路径权值,如果最大路径权值有重复,只输出1个
输入样例:
2
AB0C00D00
4 5 3 2 6
ABCD00E000FG00H0I00
9 5 4 11 7 2 8 13 4 1
输出样例:
11
27代码示例:
#include <iostream>
#include <string>
#include <cstring>
#include <iomanip>
#include <algorithm>
#include <cmath>
#include <queue>
using namespace std;
struct BNode {
char data;
int weight;
BNode* lChild;
BNode* rChild;
};
class BTree {
public:
BNode* root;
BTree() :root(NULL) {}
BNode* creatBTree() {
BNode* tmp;
char ch;
cin >> ch;
if (ch == '0') tmp = NULL;
else {
tmp = new BNode;
tmp->data = ch;
tmp->lChild = creatBTree();
tmp->rChild = creatBTree();
}
return tmp;
}
void Preorder(BNode* cur) {
int weight;
if (cur != NULL) {
cin >> weight;
cur->weight = weight;
Preorder(cur->lChild), Preorder(cur->rChild);
}
}
void addWeight(BNode* cur, int curWeight, int& maxWeight) {
if (cur != NULL) {
curWeight += cur->weight;
if (cur->lChild == NULL && cur->rChild == NULL) maxWeight = max(maxWeight, curWeight);
addWeight(cur->lChild, curWeight, maxWeight), addWeight(cur->rChild, curWeight, maxWeight);
}
}
};
int main() {
int t;
cin >> t;
while (t--) {
int count = 0;
BTree tree;
tree.root = tree.creatBTree();
int n;
cin >> n;
int maxWeight = 0;
tree.Preorder(tree.root);
tree.addWeight(tree.root, 0, maxWeight);
cout << maxWeight << endl;
}
return 0;
}题目五:DS树 -- 二叉树镜面反转
题目描述:
假设二叉树用二叉链表存储,用含空子树遍历的先序序列结果创建。空子树用字符#表示
输入二叉树的先序序列,请你先创建二叉树,并对树做个镜面反转,再输出反转后的二叉树的先序遍历、中序遍历、后序遍历和层序遍历的序列。所谓镜面反转,是指将所有非叶结点的左右孩子对换。
输入要求:
测试次数t
每组测试数据是一个二叉树的先序遍历序列,#表示空树
输出要求:
对每棵二叉树,输出镜面反转后的先序、中序、后序和层次遍历序列。如果空树,输出四个NULL(后面不加空格,每个NULL独自一行,中间没有空行)。如下:
NULL
NULL
NULL
NULL
输入样例:
3
41#32###65##7##
AB#C##D##
AB##C##
输出样例:
4 6 7 5 1 3 2
7 6 5 4 3 2 1
7 5 6 2 3 1 4
4 6 1 7 5 3 2
A D B C
D A C B
D C B A
A D B C
A C B
C A B
C B A
A C B 代码示例:
#include <iostream>
#include <string>
#include <cstring>
#include <iomanip>
#include <algorithm>
#include <cmath>
#include <queue>
using namespace std;
struct BNode {
char data;
BNode* lChild;
BNode* rChild;
};
class BTree {
public:
BNode* root;
BTree() :root(NULL) {}
BNode* creatBTree() {
BNode* tmp;
char ch;
cin >> ch;
if (ch == '#') tmp = NULL;
else {
tmp = new BNode;
tmp->data = ch;
tmp->lChild = creatBTree();
tmp->rChild = creatBTree();
}
return tmp;
}
void Preorder(BNode* cur) {
if (cur != NULL) {
cout << cur->data << " ";
Preorder(cur->lChild), Preorder(cur->rChild);
}
}
void Inorder(BNode* cur) {
if (cur != NULL) {
Inorder(cur->lChild);
cout << cur->data << " ";
Inorder(cur->rChild);
}
}
void Postorder(BNode* cur) {
if (cur != NULL) {
Postorder(cur->lChild), Postorder(cur->rChild);
cout << cur->data << " ";
}
}
void levelDFSTree(BNode* cur) {
queue<BNode*> Q;
BNode* p = cur;
if (p) Q.push(p);
while (!Q.empty()) {
p = Q.front();
Q.pop();
if (p) {
cout << p->data << " ";
Q.push(p->lChild), Q.push(p->rChild);
}
}
}
void Reverse(BNode* cur) {
if (cur != NULL) {
swap(cur->lChild, cur->rChild);
Reverse(cur->lChild), Reverse(cur->rChild);
}
}
};
int main() {
int t;
cin >> t;
while (t--) {
BTree tree;
tree.root = tree.creatBTree();
if (tree.root == NULL) {
cout << "NULL" << endl << "NULL" << endl << "NULL" << endl << "NULL" << endl;
}
else{
tree.Reverse(tree.root);
tree.Preorder(tree.root);
cout << endl;
tree.Inorder(tree.root);
cout << endl;
tree.Postorder(tree.root);
cout << endl;
tree.levelDFSTree(tree.root);
cout << endl;
}
}
return 0;
}本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java网络爬虫--概述与原理
- Unity-小工具-LookAt
- 常用Java代码-Java中的Future和Callable接口
- 【InternLM 大模型实战】第四课
- 相机(机器视觉系统)标定、相机校准、内参和外参
- Scrum敏捷认证CSM官方认证班Certified ScrumMaster - CSM认证班
- 基础算法(9):搜索(深搜)
- 戴尔服务器有8条内存条,开机有一条内存条自检提示出错,可以不用管他吗,有影响吗?
- DEJA_VU3D - Cesium功能集 之 113-获取圆节点(2)
- 计算机毕业设计------SSM电器商城系统