从传统型数据库到非关系型数据库
一 什么是数据库
???? 数据库顾名思义保存数据的仓库,其本质是一个具有数据存储功能的复杂系统软件,数据库最终把数据保存在计算机硬盘,但数据库并不是直接读写数据在硬盘,而是中间隔了一层操作系统,通过文件系统把数据保存为本地文件系统的数据文件;我们讲过Hadoop,分布式文件系统HDFS的数据块本质上也是本地文件系统的普通数据文件。
二传统关系型数据库为什么行,又为什么不行了?
? ? 讲HBase之前,我们先从关系数据库讲起,再从逻辑上一步步推导出为什么要使用HBase
1 关系数据库为什么行?
? ? 从一个关系数据库的例子开始:我们学的过MySQL数据库,就是一个典型的关系数据库
? ? 一个关系数据表的典型例子:学生-课程-成绩表
一共三张关系表:
? ? 学生表(学号<string>,姓名<string>,年龄<int>)
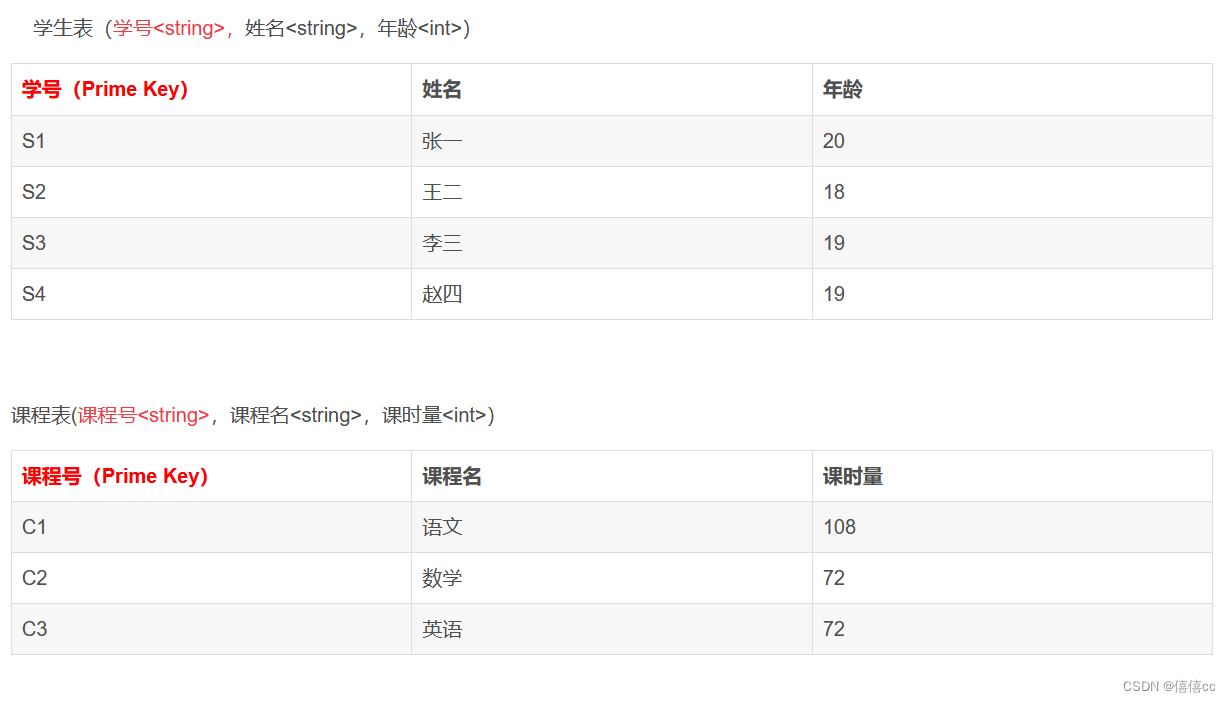

以上是在MySQL关系数据库中学过的,最常见的实体E-关系R表(2实体,1关系)的实例
???? 但是马克思主义哲学认为,世界上所有的事物都是普遍联系的(离散数学中的对关系的定义)万事万物在本质上都处于同一张巨大的“关系表”中,能够用一张大表来表示,
???? 学生、课程、成绩也不例外,在没有进行关系模式分解之前,它们三者实质上也是出于同一张大表中(在离散数学里,这张大表实质上是学生、课程、成绩三个集合的笛卡尔积的一个子集,笛卡尔积全集总共应该是4*3=12条记录,我们取是一个7条记录的子集),学生课程成绩大表如下:
NULL代表空值,说明没有实际意义的数据,但是每个NULL仍然占存储空间(1个字节)
??? 那么问题来了,既然这样一张大表就可以表示学生、课程以及成绩三者之间的关系,并能完备的保存所有数据,那么为什么关系数据库要很麻烦地把这张大表分解成三张小表呢?
??? 一张同时保存学生,课程和成绩的一张大的关系表有什么问题(缺点)呢?
??? 问题1:
??? 数据冗余(很容易看出,学生,课程名等信息都保存了很多次,浪费了很多存储空间)
??? 问题2:
??? 数据丢失(学生赵四因为没有学习任何门课程,没有成绩,导致基本信息姓名年龄也没法保存)
??? 问题3:
??? 更新麻烦(修改语文的课时量,要修改多次,更新多个存储单元,浪费算力)
??? 问题4:
??? 插入异常(假如插入一个学生马五,却未学习任何课程,课程是主键,没有任何成绩,则无法插入学生)
??? 问题5:
?? 删除异常(假如删除英语课程,会导致学生李三的信息也被删除了)
??? 总之,采用一张大的关系表,不但会导致数据冗余,而且数据记录的增加、删除、修改都会出现异常问题!
?? 经过关系模式分解,把一张大表拆分成学生、课程和成绩三张小表后,以上问题就都可以解决了;因此,关系数据库一般都有存在主外键关联的多张表,而不会一股脑的把所有数据用一张大表来存储;
??? 但是一张大表是不是一无是处呢,会不会也有优点呢?
??? 答案:一张大表的优点是查询比较方便,速度快;无论是查学生、查课程、查成绩都在同一张表操作即可,如果加上索引机制,速度会更快
?? 那么新的问题又来了,既然传统关系数据库模型已经完美解决了数据存储和数据查询的问题,也不会有插入删除更新等异常,为什么还会出现非关系型数据库(NoSQL)呢?HBase就是一种典型的非关系型数据库!!一张大表自己跟自己何来关系?多张表之间才存在“关系”!
2 关系数据库又为什么不行了?
??? 大家别忘了,我们现在处于大数据时代,所要存储和处理的数据量是PB/EB/ZB级别,而传统关系型数据库(如Oracle MySQL),能保存1亿条记录(每条记录几百个列),能达到TB级别基本就绝对是达到极限了,而大数据级别规模的数据库,需要保存的可能是上百亿条记录,每条记录几百万个列!!
?? 大数据时代,数据规模大得不可想象、宏大至极、如浩瀚星宇!!
??? 如此巨大的数据规模,传统关系数据库就力不从心了,原因如下:
??? 1)数据存储
??? 关系数据库的服务器存储容量不能横向扩展,无法存储海量数据,纵向扩展的程度有限,存储能力不够;关系数据库是面向行的存储,某行的一个列字段即使是Null,也会占用一些(一个字节)存储空间,造成存储空间的巨大浪费
??? 2)数据操作
?? 查询操作:关系数据库一般都有多张表,select操作多会涉及到多张表,存在大量的多表关联查询,数据量不大还好,比如简单的联机事务处理OLTP,还可以应付;如果数据量非常大,比如是复杂的联机分析处理OLAP,需要对大量数据进行复杂的多表关联查询,多表关联查询非常非常慢,效率会非常非常低,导致传统关系数据库的失能。
??? 那么有人会问,既然数据量很大时,会导致多表关联查询变慢,那么就不搞多张表了,还把几张小表合并成一张大表不就可以了吗?
?? 答案:是个好主意,但是搞成一张大表,又退回到问题原点了,又会出现数据冗余、增删改的异常!!
?? 因此,大数据时代的来临,面对不可想象的超大规模数据量,传统关系数据库面临进退两难的境地,进会导致复杂关联查询变慢,退会导致最基本的OLTP(增删查改操作)出错异常,进退维谷,彻底歇菜!
? 除此之外,关系数据库还有一个问题,只能存储结构化数据(关系表的每个列字段的数据类型都是固定的事先定义好的);互联网大数据产生的数据一般多是半结构和非结构化的,关系数据库无法存储半结构非结构化数据
三 大数据时代,HBase分布式数据库为什么行?
??? 互联网公司最关心两个业务指标是什么?一是流量,二是用户量;流量大说明要存储处理的数据量大(大数据),用户量大说明需要处理高并发的用户请求(高并发);
?? 大数据有个4V特征是什么:1)数据规模庞大(Volume): 数据量大关系数据库容不了;2)数据更新频繁(Velocity):高并发访问大关系数据库受不了;3)数据类型多样(Variety):类型多变关系数据库存不了;4)数据价值大密度低(Value):高价值数据密度低关系数据库算不了
?? 我们上面一直只是在论述“传统关系型数据库在大数据和高并发场景下为什么不行?”,那么为什么“非关系型数据库HBase在大数据和高并发场景下为什么行?
?? NoSQL非关系型数据库在大数据时代横空出世,就是为了解决传统数据库面临的问题,就是为了存储处理的大数据,以及响应高并发的用户请求,适应数据类型多变得半结构非结构化存储!
??? HBase(Hadoop DataBase)就一种典型的NoSql非关系型数据库!!!HBase诞生在大数据的新时代,是专门用于保存大数据规模的数据库,传统关系数据库诞生在小数据的旧时代,是用于保存中小规模数据的数据库;
??? 数据量非常大时,传统关系数据库处理复杂关联查询统计分析显得力不从心,比如执行group by聚合操作语句时,关系数据库是按行存储的,需要读取一整行的所有列的数据,效率低,而HBase是按列存储的,执行聚合操作时只需读取单列数据,效率高;
??? 传统关系数据库既不能适应超大规模数据量,也不能适应高并发的读写请求(了解一下阿里的去ioe),即使是非常擅长联机事务处理OLTP的Oracle数据库,遇到千万上亿好并发请求估计也会歇菜,而HBase等非关系型数据库天然为了互联网和大数据时代而产生的,其数据模型和架构设计使其不但能存储海量数据,还能胜任高并发随机读写请求;
?? HBase在大数据和高并发场景下为什么行?主要原因如下:
?1)HBase保留了传统关系数据的部分优点(保留了老优点)
?????? 存储无冗余(值的存储无冗余,但是行键、列族和列是有冗余的,表设计行键不要太长),简单查询快,没有插入、删除、更新异常
? 2)HBase克服了传统关系数据的部分缺点(改正了老缺点)
????? 高并发访问,大数据量存储,单列快速查询,单列数据超快速插入,面向单列的复杂查询统计效率高(例如执行group by聚合语句)
??? 3)HBase独有的功能特性(增加了新优缺点)
???? HBase 是面向列的存储,列的本质上是从上到下紧密连续紧密存储的多个键值对,因此逻辑视图中的空白单元格值并不占用实际存储空间;只有主列是固定的,子列是动态插入的,能动态增加子列;每个存储单元,也就是每个列的值有多个时间版本;没有数据类型,所有数据都存储为字节数组,适应半结构非结构化类型多变的数据
? 4)然而,HBase也有比不上传统关系数据库的缺点(丢失了老优点,但是老优点在新的业务场景下也是可有可无)
??? 不擅长OLTP联机事务处理,只能对单行的数据的操作加事务transaction;不擅长跨越多个主列的复杂关联查询,只能对单个主列进行过滤查询;大数据存储处理和高并发场景下的HBase分布式系统,并不需要严格的事务和复杂关联查询;HBase在CAP定理中选择了C(最终一致性)和P(分区容错性),放弃了A(可用性),因此事务不太重要(放弃ACID选择BASE)
四 HBase的数据存储方式
HBase和传统关系型数据库面向行的存储不同,而是采用面向列的存储方式!
HBase没有采用关系数据库的关系模式分解成多张小表,它很简单粗暴,就是一张大表搞定!
所以HBase没有学生表,没有课程表,没有成绩表,就是只有一张面向列存储的大表,HBase表是一张大表,把学生信息、课程和成绩放在一张表中,把原来的三张表当做主列(列族),把原来的表中列当做子列
什么叫逻辑上,什么是物理上?举个例子,我们机房的网络的主机之间在逻辑上是两两相连的网状连接,而在物理上所有主机都直接连接到中心交换机,物理上是星形连接。
HBase的数据表的逻辑视图(头脑中的存储方式),像一张(只有一张)含有子列的多维表;有三个主列,每个主列有多个并列显示的子列,如下表所示(HBASE的逻辑视图1):
?
上表不是传统的关系表,因为关系表不允许列包含有子列;上表中的空白单元格不是NULL,不占用实际物理存储空间,这和传统关系表也不相同;
??? 上表的描述方式,各个子列是从左到右横向排列的,仍然像是“面向行”特征,仍然无法清晰的体现出HBase“面向列”的存储特征,我们把上面的HBase逻辑视图再变化一下,把各个子列由上到下纵向排列,更像是一列,更能体现HBase“面向列”的存储特征,从逻辑视图上看,学生课程成绩表如下表所示(HBASE的逻辑视图2),:
说明:
1)空白单元格不是NULL, 不占用实际的物理存储空间;关系表中才有NULL,占一个字节;
2)课程的课时量视为课程的其他次要属性,不用保存;或可以另表保存,或可作为子列名的后缀(语文-108)
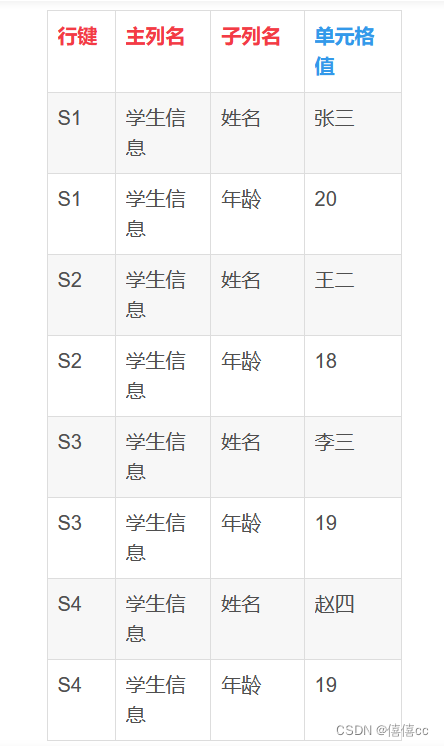
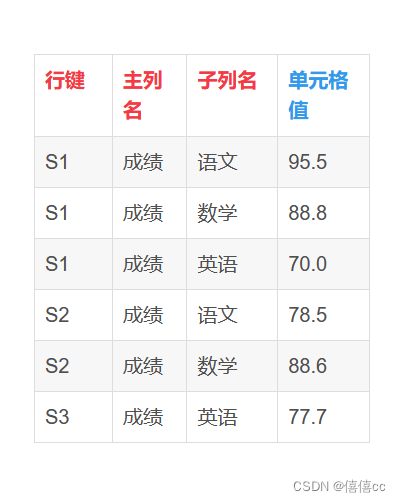
??? HBase的数据表的物理视图(真实的存储形式)中可以看出,HBase是面向列存储的,主列中的子列只保存为从上到下纵向的一列,本质上是单列的存储格式是一个键值对(Key,Value);学生课程成绩表实际存储为两列,每列都是由(行键,主列名,子列名,单元格值)组成的连续存储的存储单元,其中前三个元素(行键,主列名,子列名) 构成键Key,最后一个元素单元格值构成值Value:
第一列:学生信息列
?第二列:成绩列
说明:
1)Hbase的物理视图体现出HBase数据存储的本质特征,从物理上看,HBase确实是面向列存储的数据库,信息列和成绩列这两列完全是分开、独立存储的;
2)(行键,主列名,子列名)才能唯一标识一行,行键不是唯一的,因此存在多行的行键相同(关系表的行键唯一);
3)为了容易理解,目前可以先认为HBase的存储是三维的,(行键、主列、子列)三个维度坐标确定一个值,关系表的存储是二维的,(行键,列名)两个维度坐标确定一个值;
4)但事实上,HBase的实际物理存储模型是四维的,多了一个时间维;(行键、列族、列、时间戳)四个维度坐标确定一个值,所以HBase才能够存储海量的数据(HBase是四维时空,MySQL是二维空间);如下图,行键、列族、列可以都相同,但是时间戳不同,所以值可以不同
五 关于CAP定理(NOSQL)
鱼、熊掌、鹿茸三者不可得兼
项目管理:进度、成本、质量等边三角形
CAP定理:
Consistency? 一致性:集群中每个节点读到的数据是一样的
Availability? 可用性? :整个系统不失能,可忍受的响应时间
Partition Tolerance:分区容错性:集群中的节点之间无法通信(断网),分离的节点可以各自正常运行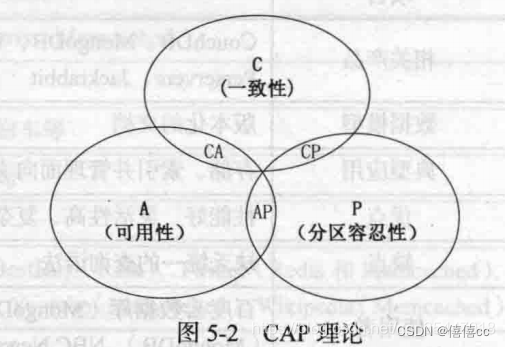
对CAP理论的图解

不同的系统对CAP的选择不同:

六 对HBase的体系架构的图解
?1)对分区(Region)的形象化解释
?
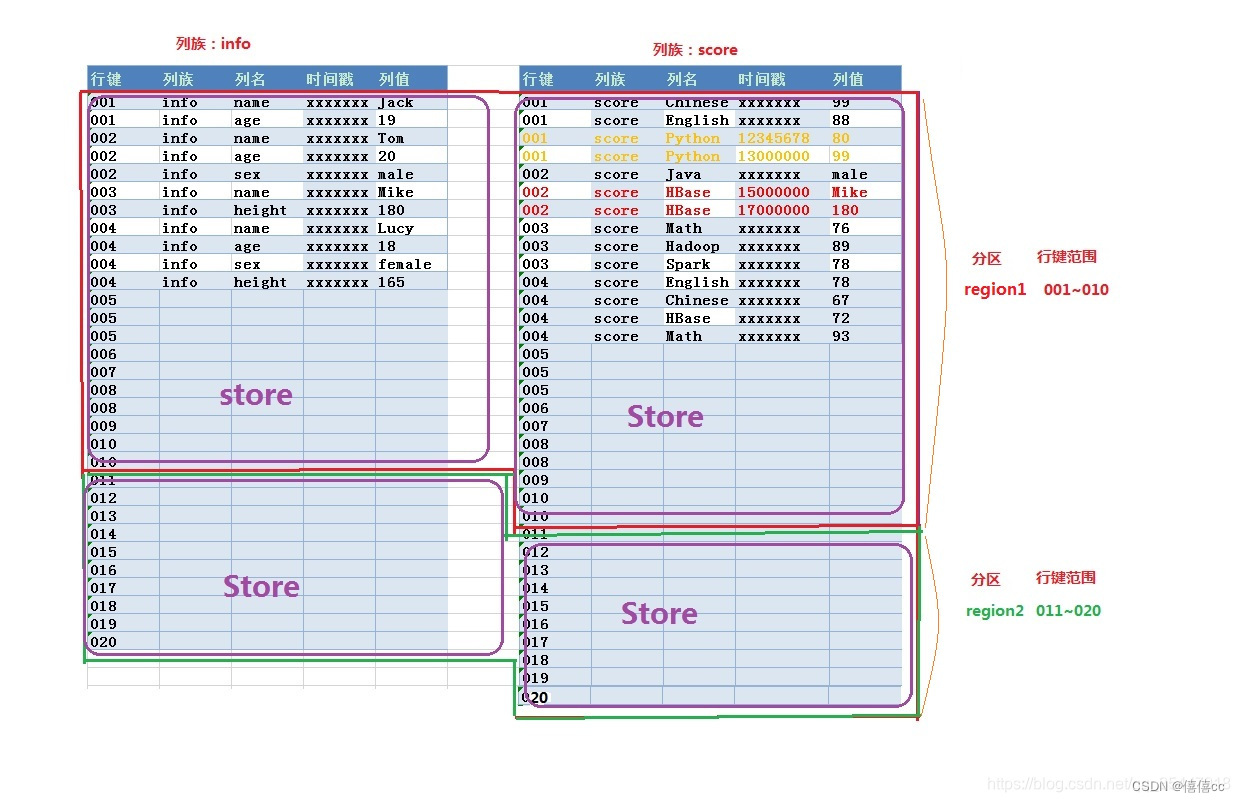
2)对Region和Store关系的讲解

5)HBase的读、写流程
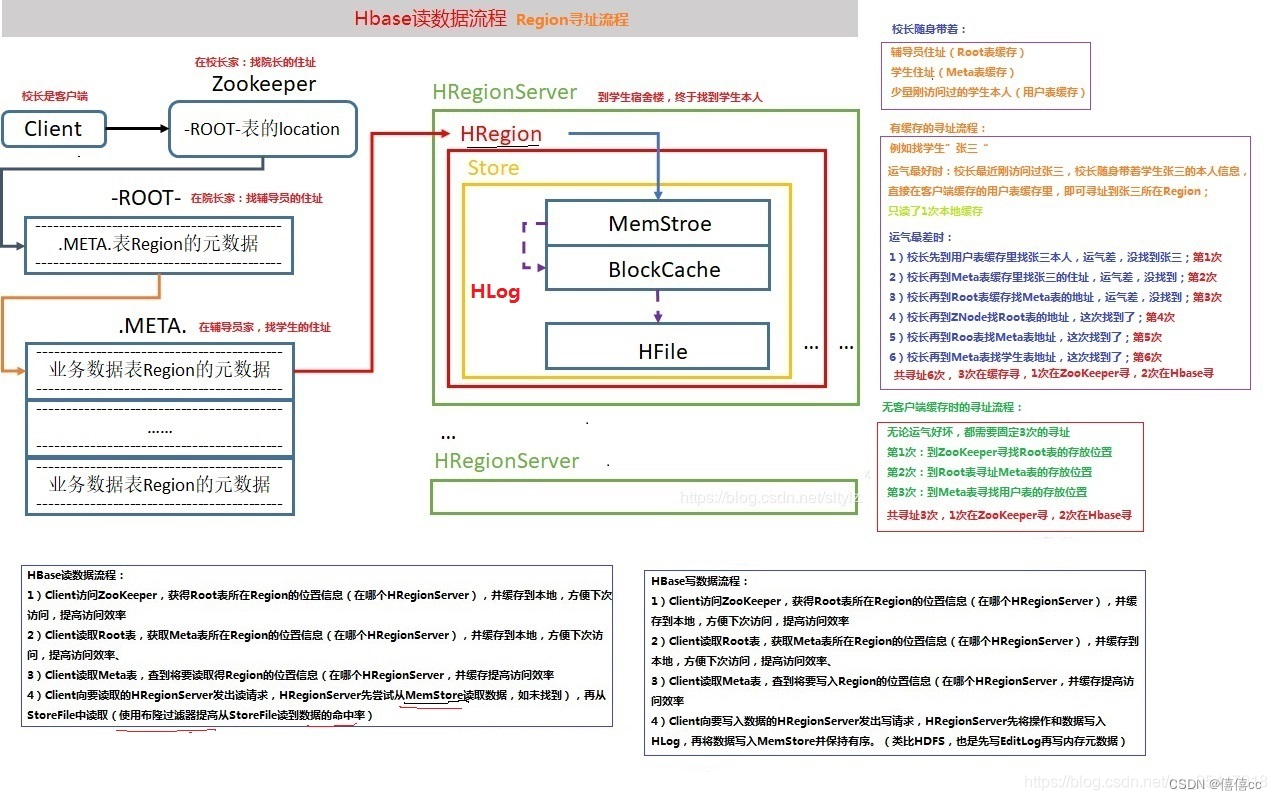
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- AI动作冒险电影《角斗士2:破晓之争》(上)
- 企业为什么要选择软件定制开发?
- 基于SSM的校园二手交易网站设计与实现(有报告)。Javaee项目。ssm项目。
- IDEA GitHub令牌原理(Personal Access Token)
- Depop下单购物教程,自养号优势及需要满足哪些技术要求?
- uniapp——自定义导航栏的封装
- 社交媒体的力量:独立站如何利用海外社媒进行引流
- 浏览器的工作原理 - 从输入URL 按下回车到页面展示过程发生了什么?
- 哈希应用之位图+布隆过滤器