【视野提升】ChatGPT的系统是如何工作的?
发布时间:2024年01月25日
类似ChatGPT的系统是如何工作的?
我们试图在下图中解释它是如何工作的。这个过程可以分为两个部分。
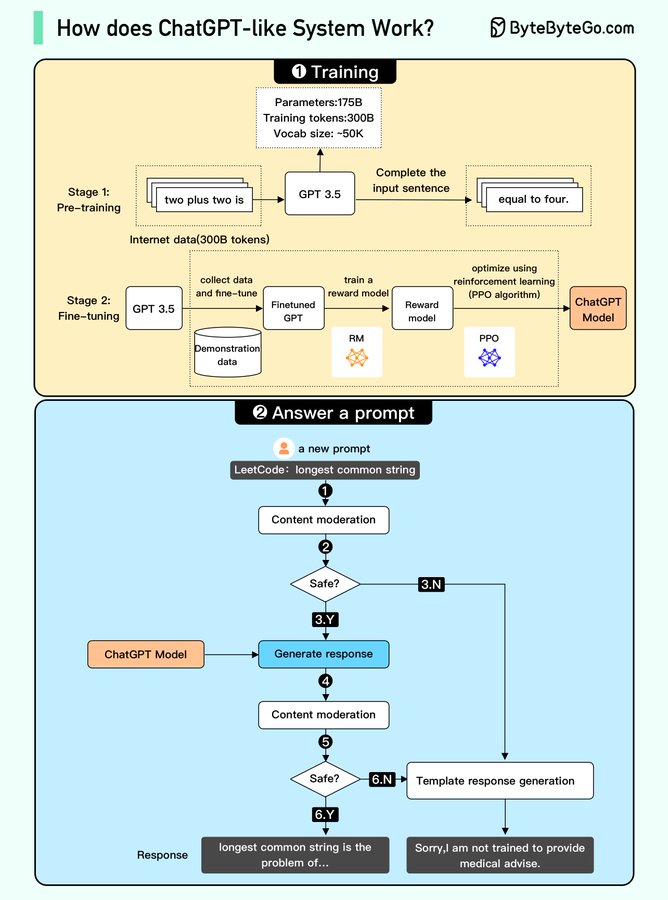
训练
要训练一个ChatGPT模型,有两个阶段:
预训练
在这个阶段,我们在大量互联网数据上训练一个GPT模型(仅解码器转换器)。
目标是训练一个模型,该模型可以根据给定的句子预测未来的单词,使其语法正确且语义有意义,类似于互联网数据。
在预训练阶段之后,模型可以完成给定的句子,但它不能回答问题。
微调:
这个阶段是一个三步过程,将预训练的模型转变为一个问答ChatGPT模型:
-
1). 收集训练数据(问题和答案),并根据这些数据对预训练的模型进行微调。模型将问题作为输入,并学习生成与训练数据相似的答案。
-
2). 收集更多数据(问题、多个答案),并训练一个奖励模型,将这些答案从最相关到最不相关进行排名。
-
3). 使用强化学习(PPO优化)对模型进行微调,使模型的答案更准确。
回答提示
🔹步骤1:用户输入完整的问题,“解释分类算法是如何工作的”。
🔹步骤2:问题被发送到一个内容审核组件。这个组件确保问题不违反安全准则,并过滤不适当的问题。
🔹步骤3-4:如果输入通过内容审核,它被发送到ChatGPT模型。如果输入未通过内容审核,它会直接进入模板响应生成。
🔹步骤5-6:一旦模型生成响应,它再次被发送到内容审核组件。这确保生成的响应是安全的、无害的、无偏见的等。
文章来源:https://blog.csdn.net/weixin_45264425/article/details/135834036
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Npm使用技巧
- 托管在亚马逊云科技的向量数据库MyScale如何借助AWS基础设施构建稳定高效的云数据库
- 【Java集合篇】ConcurrentHashMap是如何保证fail- safe的
- 鸿蒙开发之如何使用ios的页面布局方式开发鸿蒙app
- 机器学习(六) — 评估模型
- 【LeetCode刷题笔记】字符串
- 搭建esp32-idf开发环境并烧入第一个程序
- 类加载机制之双亲委派模型、作用、源码、SPI打破双亲委派模型
- 一文精通 crontab 从入门到出坑
- 新成立的科技公司推广需要哪些设计准备—南京梵构广告