Linux---gcc编译
前言
在前面我们学会使用vim对文件进行编辑,如果是C或者C++程序,我们编辑好了内容还需要编译,此时就可以使用gcc和g++进行编译了。
一、gcc编译
编译的方法很简单,gcc编译c语言文件,g++编译c/c++文件,后面接你编辑好的文件名就行,如下。编译完成后生成了可执行文件a.out。

?注意虽然linux文件不看后缀,但是gcc/g++会看后缀,只有cpp、c、cc、cxx后缀才能被编译。如下编译会报错。

二、程序的编译过程
C程序的编译需要以下四个阶段? 预处理、编译、汇编、链接。
我们先来了解一下编译器的发展史:
? ? ? ? 由于计算机只认识二进制,一开始程序员使用二进制与计算机沟通,后面利用二进制写出来了汇编编译器,使汇编代码可以转化为二进制代码,因此程序员可以使用汇编语言进行程序编写,后来又使用汇编语言编写了C语言编译器,因此程序员又可以使用C语言进行代码的编写,这样一来大大的降低了与机器沟通的难度。
? ? ? ? 总结一下就是从二进制到汇编再到C语言
C程序编译的阶段就是这部发展史的反向操作。从C到汇编再到二进制。
下面是编译各个阶段的主要工作
| 预处理阶段 | 头文件展开 去注释 条件编译 宏替换 |
| 编译 | 将C语言编译成汇编代码 |
| 汇编 | 将汇编代码转为可重定位的二进制文件 |
| 链接 | 链接生成可执行文件 |
三、gcc查看编译过程
1.预处理阶段
gcc -E 预处理阶段处理完就停止,运行如下,-o code.i是将结果输出到 code.i。
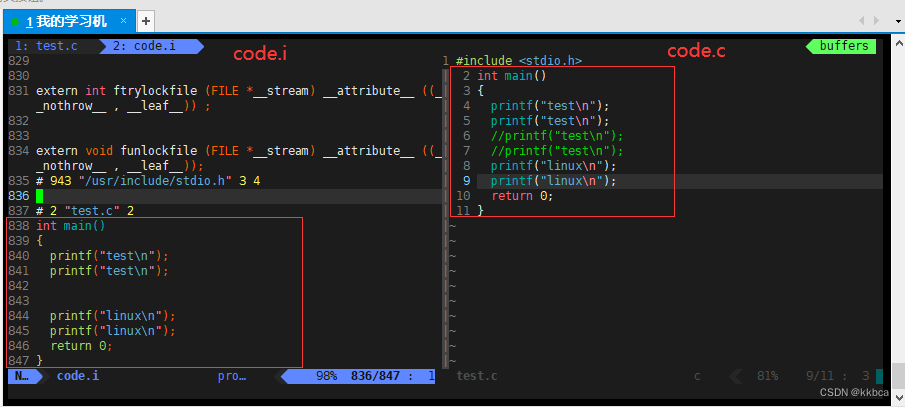
我们通过vim来看看两份文件的区别。 我们发现code.i将头文件展开了,变成了800多行的代码,并且中间缺失的部分是我们所注释掉的,这也印证了gcc -E 是预处理结束就停止。
2.编译
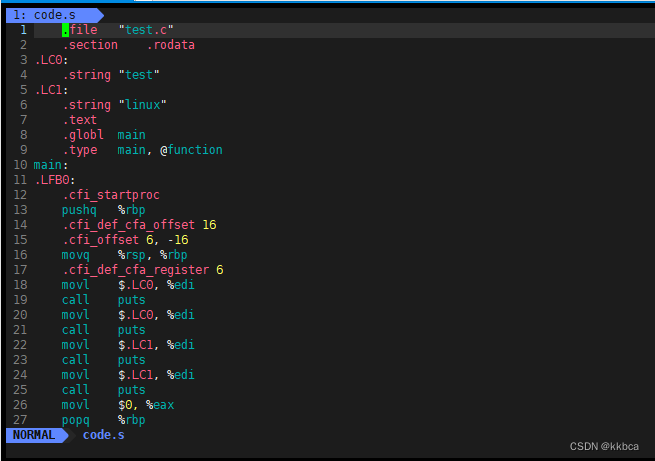
gcc -S是到编译工作做完就停止。运行如下,这里我们已经有了code.i,因此直接拿预处理过的文件继续向下编译。

我们vim code.s查看一下,都是汇编代码?
3.汇编?
gcc -c?执行到汇编工作完成就停下来。

vim code.o查看一下都是乱码,我们已经看不懂了。

用二进制方式查看一下,? od 文件后发现都是二进制。code.o文件已经相当于windows里面的obj文件了。该二进制文件还没有进过链接,还无法执行。

4.链接?
?链接是链接上库里面的内容,.o文件+系统库就可以生成可执行程序了。

这里的系统库分为静态库(.a)和动态库(.so)。 我们使用ldd mybin 来查看我们的可执行程序依赖了那些库。这里发现依赖的三个库都是动态库。

其他库我们可能不清楚,但是图片中的libc.so.6,我们对他进行拆分,去掉前面的lib,再去掉后面的.so.6。我们发现只剩下了一个c,这就是大名鼎鼎的C标准库。?并发现这个库存在我们系统里,他的路径是 /lib64/libc.so.6。
动静态库链接的内容
动态库是C/C++或者其他第三方提供的所有方法的集合,被所有程序以链接的方式关联起来,这也叫动态链接。
动态链接过程:编译器会告诉该程序需要链接的库地址,到时候程序通过这个地址找到库里面的内容并链接起来。
很多文件或者程序都会依赖动态库,如果缺失这个动态库,代码就执行不起来,程序也会崩掉,都会收到影响。
静态库是C/C++或者其他第三方提供的所有方法的集合,被所有程序以拷贝的方式,将需要的代码拷贝到自己的可执行程序中 。
静态库的缺失只会影响自己,不会影响到其他程序。
动静态库链接的优缺点
动态库链接
优点:形成的可执行程序体积小,节省资源。
缺点:可执行程序依赖动态库,库文件丢失,程序崩溃。
静态库连接
优点:形成的可执行程序体积太大,浪费资源
缺点:可以独立运行。
我们分别动静态链接测试一下
普通gcc编译为动态链接,生成code-d

?静态链接可能需要安装静态库,使用下面代码
sudo yum install -y glibc-static
sudo yum install -y libstdc++-static安装好之后进行静态链接,生成code-s ,静态链接在普通编译后面接上一个-static就可以了。
![]()
我们发现他们的大小相差非常大,有着百倍的差距。这也是为啥gcc默认采用动态链接的原因,静态链接文件太大了。

5.总结记忆?
之前的阶段这么多,每一次执行的代码都不一样,但其实很好记忆。
编译方式?-ESc? ?后缀.iso?分别代表(预处理、编译、汇编)
ESc注意前面两个大写,后一个小写,这是键盘左上角的三个
iso为系统镜像后缀,记住这两点就可以了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 协同物联:设备物联与车间数据采集的融合
- 小程序ci自动打包上传到微信平台
- 机器学习 -- 数据预处理
- gRPC-Gateway:高效转换 RESTful 接口 | 开源日报 No.105
- Kimichat使用案例:将一大片无序文本内容整理成有序的Excel表格
- RAID的基本介绍
- 探寻ChatGPT底层模型诞生之路 —— Transformer关键论文解读
- 手把手Docker部署Gitblit服务器
- 【复现】AnimateDiff ControlNet Pipeline复现过程记录
- ML Design Pattern——Bridged Schema