【Spark精讲】一文讲透SparkSQL执行过程
SparkSQL执行过程
逻辑计划
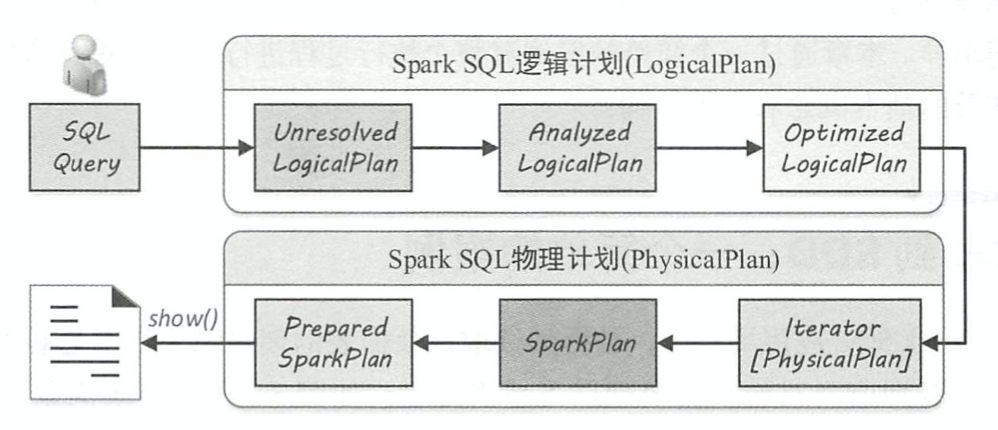
逻辑计划阶段会将用户所写的 SQL语句转换成树型数据结构(逻辑算子树), SQL语句中蕴含的逻辑映射到逻辑算子树的不同节点。 顾名思义,逻辑计划阶段生成的逻辑算子树并不会直接提交执行,仅作为中间阶段 。 最终逻辑算子树的生成过程经历 3 个子阶段,分别对应未解析的逻辑算子树( Unresolved LogicalPlan,仅仅是数据结构,不包含任何数据信息等 )、解析后的逻辑算子树( Analyzed LogicalPlan,节点中绑定各种信息)和优化后的逻辑算子树(Optimized LogicalPlan,应用各种优化规则对一 些低效的逻辑计划进行转换) 。

Spark SQL 逻辑计划在实现层面被定义为 LogicalPlan 类。 从 SQL 语句经过 SparkSqlParser 解析生成 Unresolved LogicalPlan,到最终优化成为 Optimized LogicalPlan,这个流程主要经过 3 个阶段,如上图所示。 这 3 个阶段分别产生 Unresolved LogicalPlan, Analyzed LogicalPlan 和 Optimized LogicalPlan,其中 OptimizedLogicalPlan传递到下一个阶段用于物理执行计划的生戚。
具体来讲,这 3 个阶段所完成的工作分别如下 。
(1)由 SparkSqlParser 中的 AstBuilder执行节点访问,将语法树的各种Context节点转换成对应的 LogicalPlan 节点,从而成为一棵未解析的逻辑算子树(Unresolved LogicalPlan),此时的逻辑算子树是最初形态,不包含数据信息与列信息等。
(2)由 Analyzer将一系列的规则作用在 Unresolved LogicalPlan 上,对树上的节点绑定各种
数据信息,生成解析后的逻辑算子树(Analyzed LogicalPlan)。
(3)由 SparkSQL中的优化器(Optimizer)将一系列优化规则作用到上一步生成的逻辑算子树中,在确保结果正确的前提下改写其中的低效结构,生成优化后的逻辑算子树( Optimized LogicalPlan) 。
物理计划
物理计划阶段将上一步逻辑计划阶段生成的逻辑算子树进行进一步转换,生成物理算子树。 物理算子树的节点会直接生成 RDD 或对 RDD 进行 transformation 操作(注:每个物理计划节点中都实现了对 RDD 进行转换的 execute 方法) 。 同样地,物理计划阶段也包含 3 个子阶段:首 先,根据逻辑算子树,生成物理算子树的列表 Iterator[PhysicalPlan] (同样的逻辑算子树可能对 应多个物理算子树);然后,从列表中按照一定的策略选取最优的物理算子树(SparkPlan);最 后,对选取的物理算子树进行提交前的准备工作,例如,确保分区操作正确、物理算子树节点 重用、执行代码生成等,得到“准备后”的物理算子树(PreparedSparkPlan)。 经过上述步骤后,物理算子树生成的 RDD 执行 action操作(如例子中的 show),即可提交执行 。
从 SQL语句的解析一直到提交之前,上述整个转换过程都在 Spark集群的 Driver端进行, 不涉及分布式环境 。 SparkSession 类的 sql方法调用 SessionState 中的各种对象 ,包括上述不同阶段对应的 SparkSqlParser类、 Analyzer类、 Optimizer类和 SparkPlanner类等 ,最后封装成一个 QueryExecution对象。 因此,在进行 SparkSQL开发时,可以很方便地将每一步生成的计划单独剥离出来分析 。
回到前面的案例, SQL语句较为简单(不包含 Join 和 Aggregation 等操作),因此其转换过程也相对简单。 如图下图所示,左上角是 SQL 语句,生成的逻辑算子树中有 Relation、 Filter 和 Project节点,分别对应数据表、过滤逻辑(age>l8)和列剪裁逻辑 (只涉及3列中的2列)。 下一步的物理算子树从逻辑算子树一对一映射得到, Relation逻辑节点转换为 FileSourceScanExec 执行节点,Project逻辑节点转换为 FilterExec执行节点, Project逻辑节点转换为 ProjectExec执行节点。

生成的物理算子树根节点是 ProjectExec,每个物理节点中的 execute 函数都是执行调用接口,由根节点开始递归调用,从叶子节点开始执行。上图下方展示了物理算子树的执行逻辑,与直接采用 RDD进行编程类似。需要注意的是,FileSourceScanExec叶子执行节点中需要构造数据源对应的 RDD, FilterExec 和 ProjectExec 中的 execute 函数对 RDD 执行相应的transformation 操作。
总的来看, SQL转换为RDD在流程上比较清晰。 虽然实际生产环境中的SQL语句非常复杂,涉及的映射操作也比较烦琐,但总体上仍然遵循上述步骤。
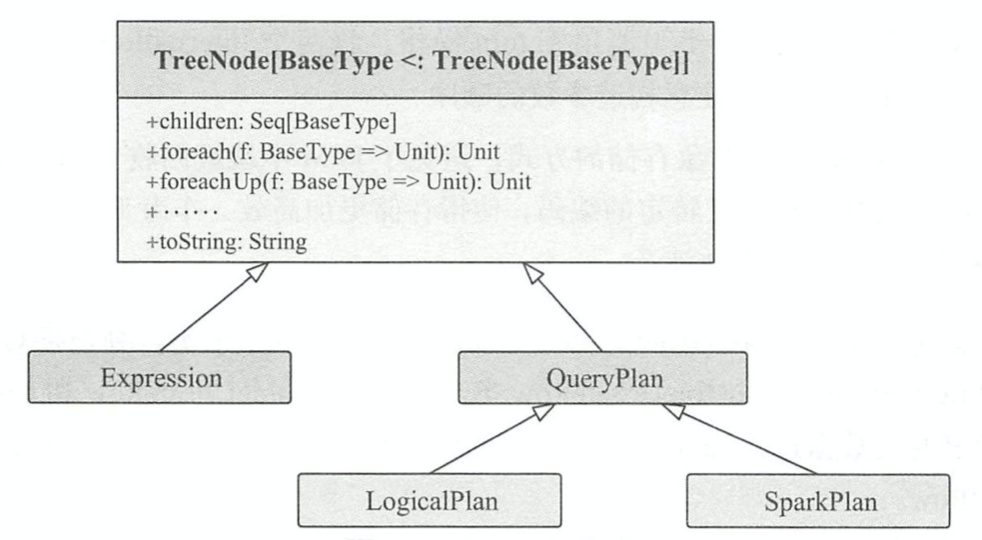
类继承关系
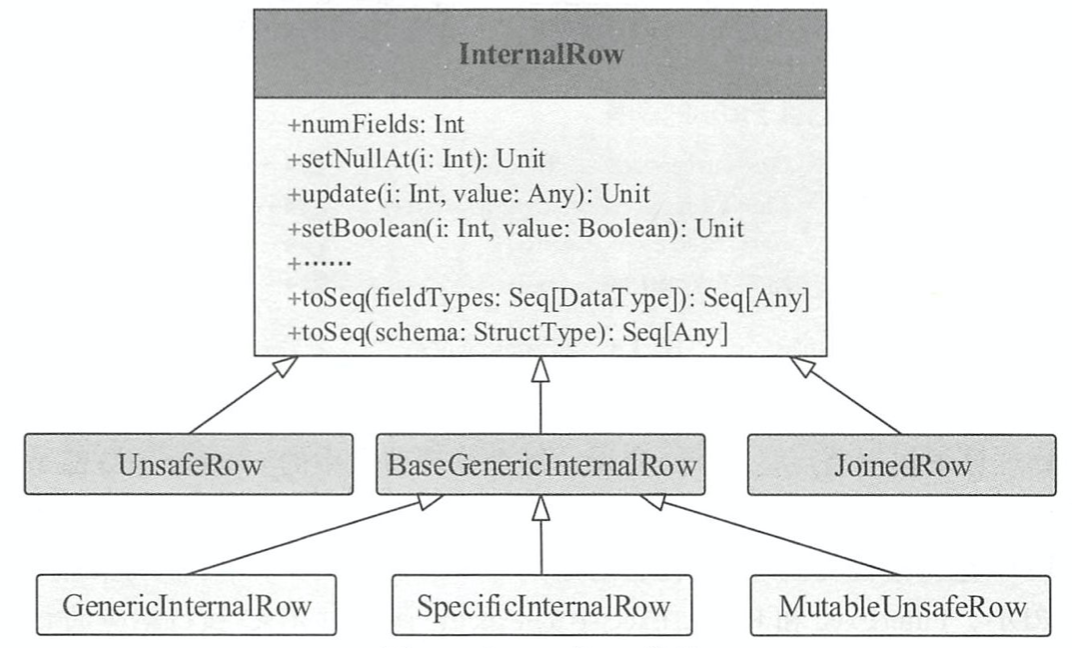
行数据
TreeNode
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- js等于操作符和全等操作符(== 和 ===)的区别,在什么情况下使用
- 亚马逊,速卖通,国际站卖家自己做测评补单有什么价值,怎么做?
- docker运行nginx不生效
- 还在为销售回款发愁吗?派可数据回款模型助力企业快速回款!
- C#编程-显示运算符重载
- C++ //练习 2.9 解释下列定义的含义。对于非法的定义,请说明错在何处并将其改正。
- 系分笔记数据库技术之概念、模式映像和数据库设计
- Selenium Wire - 扩展 Selenium 能够检查浏览器发出的请求和响应
- cpp_05_类_string类
- DTO与VO