(2024,InstDiffEdit,基于掩蔽的图像编辑,图像修复)使用即时注意力掩蔽实现高效的基于扩散的图像编辑
Towards Efficient Diffusion-Based Image Editing with Instant Attention Masks
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
基于扩散的图像编辑(Diffusion-based Image Editing,DIE)是一个新兴的研究热点,通常使用语义掩码来控制扩散编辑的目标区域。然而,大多数现有解决方案通过手动操作或离线处理获得这些掩码,极大地降低了其效率。在这篇论文中,我们提出了一种新颖且高效的图像编辑方法,用于文本到图像(T2I)扩散模型,称为即时扩散编辑(Instant Diffusion Editing,InstDiffEdit)。具体而言,InstDiffEdit 的目标是利用现有扩散模型的跨模态注意力能力,在扩散步骤中实现即时的掩码引导。为了减少注意力图的噪声并实现完全自动化,我们为 InstDiffEdit 配备了一个无需训练的精练方案,以自适应地聚合注意力分布,实现自动且准确的掩码生成。与此同时,为了补充对DIE的现有评估,我们提出了一个名为 Editing-Mask 的新基准,用于检验现有方法的掩码准确性和局部编辑能力。为了验证 InstDiffEdit,我们还在 ImageNet 和 Imagen 上进行了大量实验证明,并将其与一系列最先进的方法进行了比较。实验结果显示,InstDiffEdit 不仅在图像质量和编辑结果方面优于最先进的方法,而且推理速度更快,即 +5 到 +6 倍。
我们的代码位于 https://anonymous.4open.science/r/InstDiffEdit-C306/
3. 基础
Latent Diffusion Models,LDM。
![]()
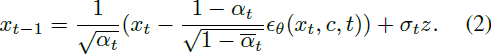
LDM 中的交叉注意力。

4. 方法
4.1 概览
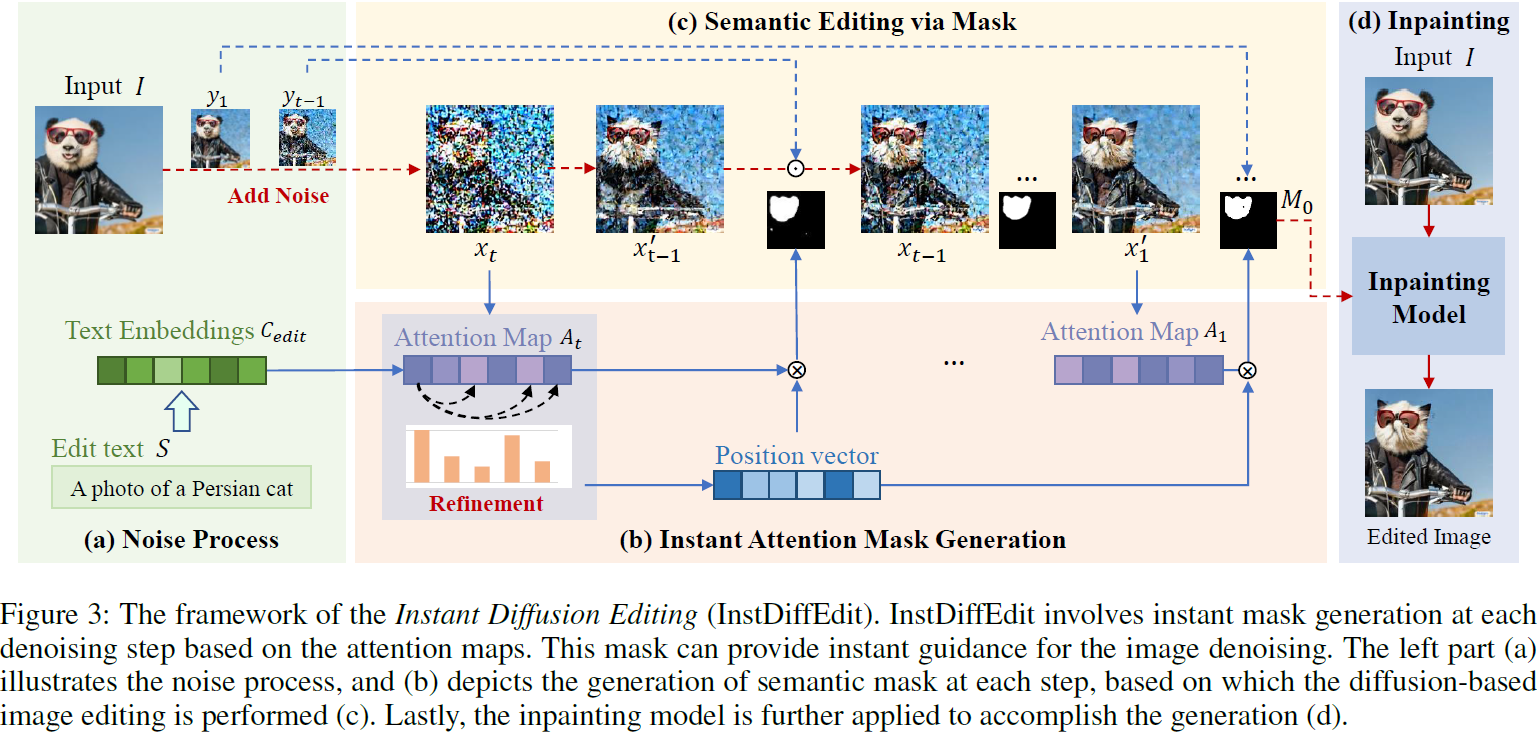
在本文中,我们提出了一种基于文本到图像扩散模型的新颖而高效的图像编辑方法,称为即时扩散编辑(InstDiffEdit),其结构如图 3 所示。
具体而言,类似于现有方法(Avrahami、Lischinski 和 Fried 2022),我们的目标是通过为输入图像添加语义掩码来实现目标图像编辑,在此基础上进行扩散步骤以实现目标版本。这个过程可以被定义为:??
![]()
其中,x'?? 和 y? 分别表示在步骤 t 时预测的有噪潜在图像及其潜在表示,而 M 则是掩码。然后,我们可以得到用于编辑的嘈杂潜在图像 x?。
这基于最近扩散模型的进展(Avrahami、Lischinski和Fried 2022),该模型可以使用掩码限制编辑区域,并用当前时间步的噪声图像替换预测图像中未被掩码的区域。这允许基于掩码的方法在编辑时保留未被掩码区域的背景。然而,生成这种语义掩码通常需要手动努力(Hertz等人,2022;Patashnik等人,2023)或离线处理(Avrahami、Lischinski和Fried 2022;Lugmayr等人,2022)。在这种情况下,Inst-DiffEdit 利用 LDMs 中的注意力图进行扩散期间的即时掩码生成。如图 2 所示,LDMs 中的注意力图很好地捕捉了图像和文本之间的语义对应关系。
然而,它也遇到了一些问题。为了指定编辑目标的注意力图,例如图 2 中的 "cat",该方法仍然需要手动努力,因为我们在应用过程中不知道用户指令的长度和内容。直接使用 "start token" 的图作为权衡对于有效的编辑来说仍然太嘈杂。

在这种情况下,我们为 InstDiffEdit 配备了一个用于掩码生成的自动精练方案。如图 3 所示,给定输入图像潜在特征 x? 和文本特征 C_edit,我们可以从等式 3 中在去噪过程中得到 latent 的注意力图 A。然后,我们提出了一个无参数的注意力掩码生成模块 G(·),以获取语义掩码
![]()
随后,使用这个即时掩码,我们可以在扩散步骤中直接执行目标图像编辑,可以重新写为:?
![]()
其中,M_t 是在时间步 t 由注意力掩码模块计算的掩码,?_θ 表示扩散模型。
最后,为了获得更好的生成结果,我们采用一种策略,即使用在最后去噪步骤中生成的掩码作为最终掩码,并通过 LDMs 中的修补方式生成最终的编辑结果。
在下一小节中,我们将详细定义所提出的注意力掩码生成模块。

4.2 即时注意力掩码生成
在 InstDiffEdit 中,我们使用在去噪过程中生成的注意力图作为掩码生成的信息源。然而,输入文本通常由多个标记组成,每个标记的注意力信息都有自己的焦点,并且随着句子长度和词组成的变化而变化很大。因此,模型很难自动定位目标单词的注意力结果。
在实践中,我们使用起始标记的注意力图作为进一步注意力掩码精练的基本信息。简言之,在预先训练良好的 T2I 扩散模型中,起始标记通常表达整个句子的语义。如图 2 所示,与起始标记对应的注意力的焦点区域与语义描述的编辑区域高度重叠。然而,起始标记包含整个句子以及原始图像信息的一部分,因此它的注意力分布仍然杂乱。
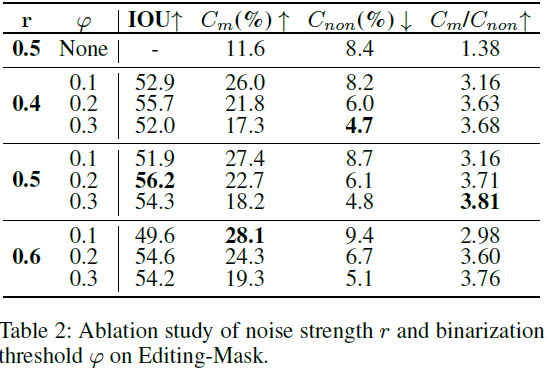
在这种情况下,我们采用关键信息提取的思想来消除嘈杂信息并获取具有语义信息的最相关内容。假设噪声强度为 r,去噪过程从时间步 τ(τ = r * T,T = 1000)开始,可以使用等式 3 获得相应的注意力图 A_τ。具体而言,我们利用起始标记的注意力图 A^τ_start ∈ R^(16×16) 作为参考信息,然后通过计算与参考图的所有相似性来检索注意力图 A^τ_index ∈ R^(16×16)。这使我们能够确定需要修改的对象的位置:?

其中,cosine(·) 表示语义相似性,N 是句子中所有标记的长度。
为了获得更准确的掩码信息,我们进一步聚合与概念相关的信息并消除不相关的信息。具体而言,我们计算 A^τ_index 与文本标记的注意力图之间的相似性,以获得相似性向量 S ∈ R^(1×N):
![]()
原则上,每个标记的注意力图的相似性与句子的语义相似性密切相关。由于注意力图与核心语义相关联,相似性会更大,反之亦然。
之后,我们可以通过使用两个阈值过滤相似性向量来获得一个位置向量,以加权注意力信息:

由于注意力图的大维度,计算去噪过程的每一步的语义相似性可能会很耗时。为了缓解这个问题,我们建议仅在去噪过程的第一步 τ 中计算位置向量 P。
最后,我们通过在时间步 t ∈ {τ, . . . , 0} 中使用注意力图 A_t 和位置向量 P,得到细化的注意力图 A^ref_t(A^ref_t = P·A_t)。然后,对其进行高斯滤波并用阈值 φ 进行二值化,以获得最终的掩码 M_t:

其中,(x, y) 指的是图像潜在空间中的一个点。值得注意的是,上述即时注意力掩码生成模块是无需训练的,因此可以直接插入大多数现有的 T2I 扩散模型中。同时,通过细化处理,得到的掩码比精练之前的更为优越。
4.3 通过掩码的语义编辑?
通过掩码生成模块,在图像去噪过程的每一步都获得一个掩码。因此,通过混合掩码,可以通过等式 4 为去噪提供引导。
然而,由于在掩码区域内的所有信息基本上被丢弃,生成的图像通常具有局部语义一致性,但不考虑全局语义,从而导致伪影。此外,当噪声水平较低时,一些编辑操作无法实现,例如颜色修改。因此,我们还为 InstDiffEdit 配备了一种基于修补的方法用于语义图像编辑。
修补方法(Rombach等人,2022)使用完全随机的噪声初始化掩码区域中的信息,并在生成过程中考虑全局信息,从而消除由原始图像信息引起的伪影和编辑失败。然而,修补的性能高度依赖于掩码的准确性。
因此,我们结合了两种方法的优势,通过在去噪过程中使用注意力图生成掩码,从而在去噪过程中引导图像生成并获得更准确的掩码。
最后,我们在去噪的最后一步生成的掩码上使用修补方法,生成一张无伪影且与原始图像中的其余信息更一致的图像。值得注意的是,这两种掩码编辑方法的组合仅在语义图像编辑的计算成本上略微增加。
5. 实验


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C++运算符重载之复数加法
- linux环境安装可操作图库语言Gremlin的图框架HugeGraph
- 【扩散模型】10、ControlNet | 用图像控制图像的生成(ICCV2023)
- zabbix安装部署
- 初入职场不会Git?经常被团队成员怼?手把手教你如何使用git
- SQL Server定时调用指定WebApi接口
- Python Socketio 介绍
- 互联网加竞赛 基于机器学习与大数据的糖尿病预测
- 通过232转Profinet将霍尼韦尔扫码枪连接到PLC上
- 羊奶vs牛奶,羊大师告诉你谁是更营养的选择?