【小白学机器学习4】从求f(x)的误差和函数E(θ)的导函数,到最速下降法,然后到随机梯度下降法
发布时间:2024年01月23日
目录
1 从求f(x)的误差和函数E(θ)的导函数,开始通过参数θ去找E(θ)的最小值,从而确定最好的拟合曲线函数f(x)
1.3 f(x) 的误差和E(θ)函数,可以变成通用的函数形式,从而E(θ)只需要关注其参数θ0,θ1...的不同,而找到其最小值
1.4 调整参数θ0,θ1... ,试图找到f(x)的误差和函数E(θ)的最小值
3.1 基础数据,x,y? 模拟函数f(x),误差和函数E(θ)
1 从求f(x)的误差和函数E(θ)的导函数,开始通过参数θ去找E(θ)的最小值,从而确定最好的拟合曲线函数f(x)
1.1 从f(x) 对y 的回归模拟开始
- f(x) 对y 的回归,可看做一种模拟
- 理论上,有无数种模拟曲线 f1(x) ,f2(x)....
- 如何去比较不同的模拟曲线 f1(x) ,f2(x) ... 谁拟合的更好?
- 答案是:比较不同的 f(x) 之间的E(θ)差别,就可以判别哪个f(x)拟合的效果更好
- E(θ)=1/2*(f(xi)-yi)^2
1.2 从比较不同的f(x)的E(θ),引出的问题
- 但是接下来的问题是
- f(x) 基于x?对y 的模拟有无数种可能,每种可能都可能是一个曲线f1(x) ,f2(x) ...,每个曲线与y计算都可以得出一个E(θ)的值
- 有无数种可能的曲线,就有无数种E(θ)值,那么这里是否有最小值?
- 如果有如何找到E(θ)的最小值呢?
1.3 f(x) 的误差和E(θ)函数,可以变成通用的函数形式,从而E(θ)只需要关注其参数θ0,θ1...的不同,而找到其最小值
- 如果把f(x)这个回归函数E(θ),做足够的的抽象,变成通用的函数
- 1次函数,二次函数等等,比如下面的1元2次函数,2元1次函数等,N元N次函数等等
- 通用函数里,需要确定的只是参数
- 从而E(θ)只需要关注起参数θ0,θ1...的不同而找到其最小值
- 所以问题从需要比较比较不同的 f(x) 之间的E(θ)差别,变成了比较 通用的函数形式里 参数θ0,θ1... 等对误差和函数E(θ)的影响
E(θ) 这个函数的可能形式
- 比如1元1次函数
- f(x)=θ0+θ1*x
- 比如1元2次函数
- f(x)=θ0+θ1*x+θ2*x^2
- 比如2元1次函数
- f(x)=θ0+θ1*x1+θ2*x2+θ3*x3
- 更复杂点,比如n元n次函数(更通用的形式)
- f(x)=θ10+θ11*x1+θ12*x1^2+θ13*x1^3+...
- ? ? ? ?θ20+θ21*x2+θ22*x2^2+θ23*x2^3+...
- ? ? ? ?....
1.4 调整参数θ0,θ1... ,试图找到f(x)的误差和函数E(θ)的最小值
- 评判函数就是E(θ) 这个关于误差和的函数。
- 当E(θ)取接近最小值的时候,就说明f(x) 对 y的拟合程度最好。
- 然后就不需要比较不同的 f(x) 之间的E(θ)差别了
- 而变成了比较 通用的f(x) 里 参数θ0,θ1... 等对f(x)的误差和函数E(θ)的影响,是否有最小值,是否可以找到最小值。
2 上述思路对应的操作上的步骤
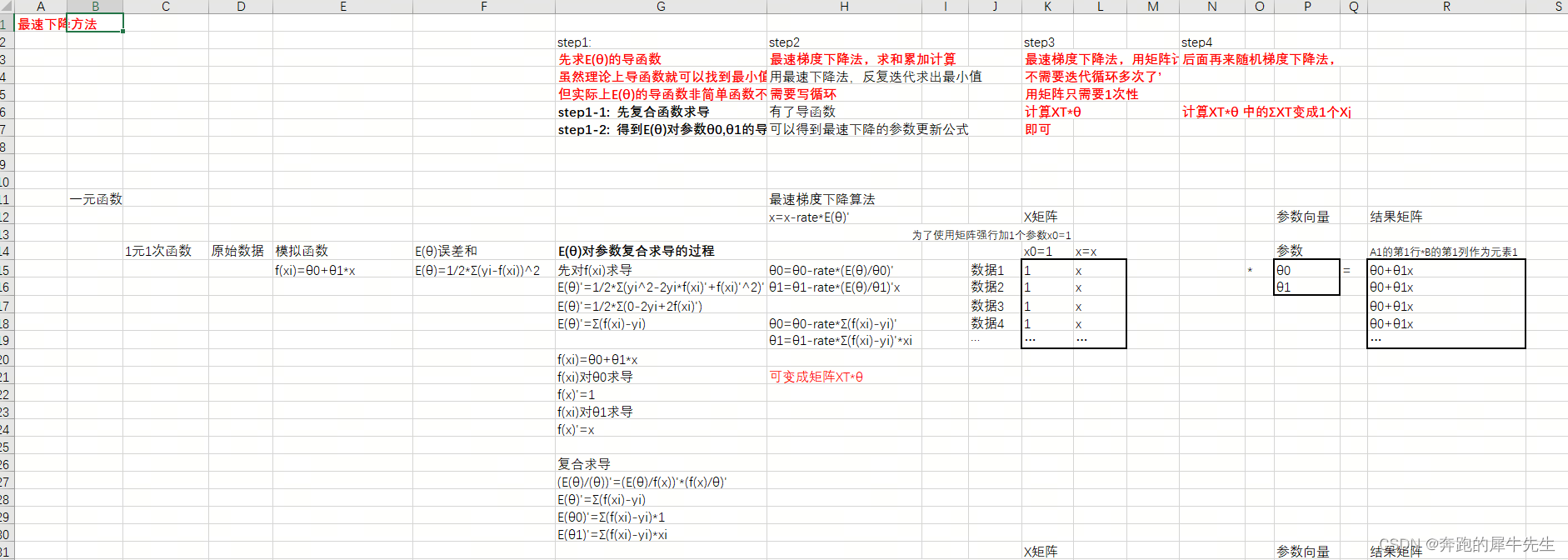
2.1 step1: ?先求E(θ)的导函数
- 虽然理论上导函数就可以找到最小值
- 但实际上E(θ)的导函数非简单函数不好求最小值
- 这里求E(θ)的导函数 不是为了直接找导函数=0,从而找到 函数E(θ)的最小值,从而找到模拟最好的f(x)曲线。
- 而是因为最速下降法的参数更新需要用到E(θ)的导函数。
- x=x-rate*E(θ)'
- step1-1: ?先E(θ)对每个参数θ复合函数求导
- step1-2: ?得到E(θ)对参数θ0,θ1...的导函数
2.2 step2:最速梯度下降法,求和累加计算
- 有了导函数,就可以套用最速下降的参数更新公式
- x=x-rate*E(θ)'
- 其中x 替换为参数θ0,θ1等
- θ=θ-rate*E(θ)'
- 然后用最速下降法,反复迭代 θ=θ-rate*E(θ)' 求出收敛的最小值(如果有)
- 需要写迭代/循环,*Σ(f(xi)-yi) ,反复对参数进行更新
- θ=θ-rate*E(θ)' 函数
- θ0=θ0-rate*Σ(f(xi)-yi)'? ? ? ? ?'需要把所有数据?*Σ(f(xi)-yi) 进行求和
- θ1=θ1-rate*Σ(f(xi)-yi)'*xi? ? ?'需要把所有数据?*Σ(f(xi)-yi) 进行求和
- ...
2.3 step3 :最速梯度下降法,用矩阵计算
- 如果使用矩阵运算,用矩阵只需要1次性计算XT*θ即可
- 不需要迭代循环多次了
- θ=θ-rate*E(θ)' 函数
- θ0=θ0-rate*Σ(f(xi)-yi)'? ? =?θ0- rate*XT*θ? ? ? ? '一步计算即可
- θ1=θ1-rate*Σ(f(xi)-yi)'*xi?=θ1- rate*XT*θ1? ? ?'一步计算即可
- ...
2.4 step4: 用随机梯度下降法对最速下降法进行优化
- 再来随机梯度下降法,
- 计算XT*θ 中的ΣXT变成1个Xj
- 好处
- 减少了计算里,计算更快
- 避免了最速下降法的局部最优的问题
3 举例:1元1次函数
3.1 基础数据,x,y? 模拟函数f(x),误差和函数E(θ)
先从最简单的一元函数开始,其中最简单的是1元1次函数
- 以1元1次函数为例:
- 原始数据 x,y
- 模拟函数 f(x)=θ0+θ1*x
- 误差和 E(θ)=1/2*Σ(yi-f(xi))^2
3.2?E(θ)对参数复合求导的过程
- 复合求导的方法
- f(x/n)'=?f(x/m)' *f(m/n)'
先对f(xi)求导
- E(θ)'=1/2*Σ(yi^2-2yi*f(xi)'+f(xi)'^2)'
- E(θ)'=1/2*Σ(0-2yi+2f(xi)')
- E(θ)'=Σ(f(xi)-yi)
f(xi)对θ0, θ1的求导
- f(xi)=θ0+θ1*x
- f(xi)对θ0求导,f(x)'=1
- f(xi)对θ1求导,f(x)'=x
复合求导
- (E(θ)/(θ))'=(E(θ)/f(x))'*(f(x)/θ)'
- E(θ)'=Σ(f(xi)-yi)
- E(θ0)'=Σ(f(xi)-yi)*1
- E(θ1)'=Σ(f(xi)-yi)*xi
3.3?最速梯度下降算法
- x=x-rate*E(θ)'
- θ0=θ0-rate*(E(θ)/θ0)'
- θ1=θ1-rate*(E(θ)/θ1)'x
- θ0=θ0-rate*Σ(f(xi)-yi)'
- θ1=θ1-rate*Σ(f(xi)-yi)'*xi
- 可变成矩阵XT*θ
?? ?X矩阵?? ?
?? ?为了使用矩阵强行加1个参数x0=1?? ?
?? ?x0=1?? ?x=x
数据1?? ?1?? ?x
数据2?? ?1?? ?x
数据3?? ?1?? ?x
数据4?? ?1?? ?x
…?? ?…?? ?…
参数向量?? ??? ?结果矩阵
?? ??? ?
参数?? ??? ?A1的第1行*B的第1列作为元素1
θ0?? ?=?? ?θ0+θ1x
θ1?? ??? ?θ0+θ1x
?? ??? ?θ0+θ1x
?? ??? ?θ0+θ1x
?? ??? ?…
?? ??? ?

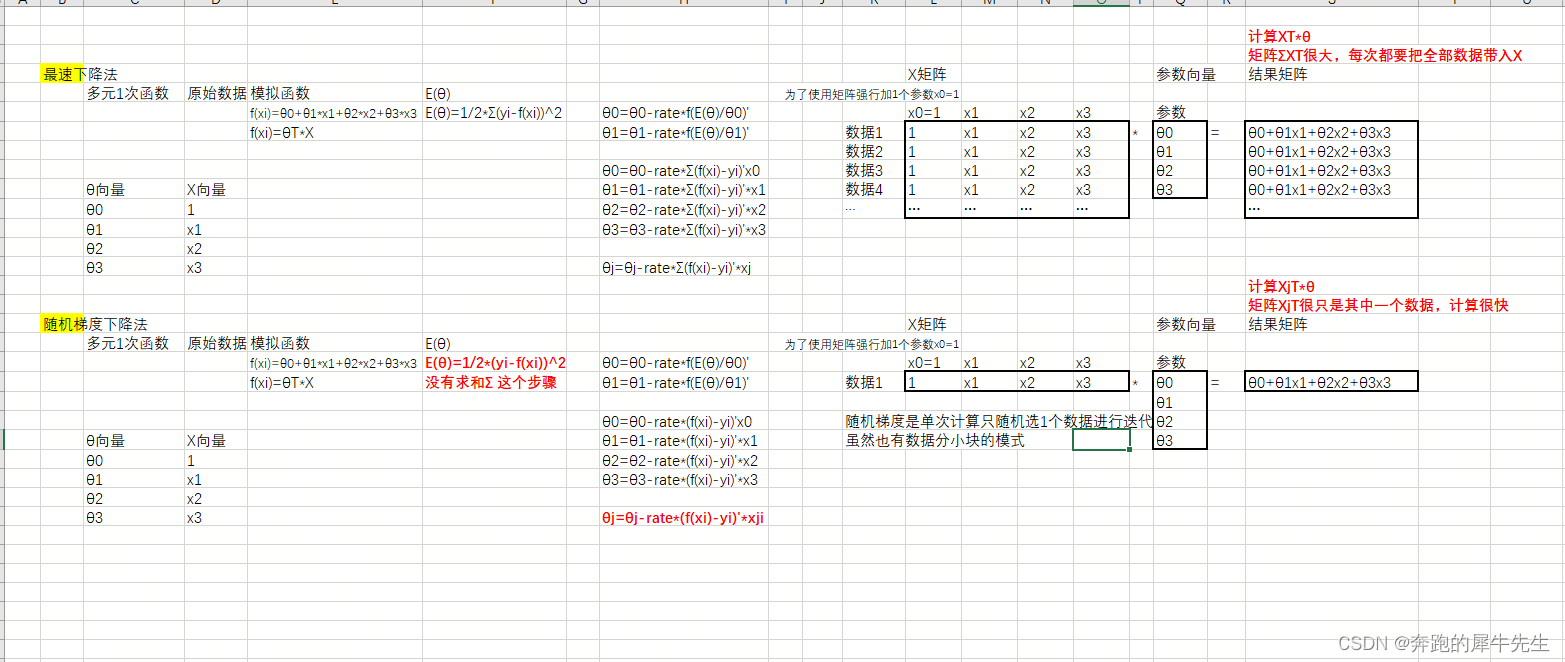
3.4?随机梯度下降法,
- 后面再来随机梯度下降法,
- 计算XT*θ 中的ΣXT变成1个Xj
3.4.1 以多元1次函数为例子
- 模拟函数,多元1次函数,f(xi)=θ0+θ1*x1+θ2*x2+θ3*x3
- 其误差函数 E(θ)=1/2*Σ(yi-f(xi))^2
3.4.2 用最速下降法计算θ的迭代
- θ0=θ0-rate*f(E(θ)/θ0)'
- θ1=θ1-rate*f(E(θ)/θ1)'
求得导函数后展开为
- θ0=θ0-rate*Σ(f(xi)-yi)'x0
- θ1=θ1-rate*Σ(f(xi)-yi)'*x1
- θ2=θ2-rate*Σ(f(xi)-yi)'*x2
- θ3=θ3-rate*Σ(f(xi)-yi)'*x3
可以抽象为
- θj=θj-rate*Σ(f(xi)-yi)'*xj
- 转化为矩阵计算?
3.4.3 随机梯度下降法
- E(θ)
- E(θ)=1/2*(yi-f(xi))^2
没有求和Σ 这个步骤
- θ0=θ0-rate*f(E(θ)/θ0)'
- θ1=θ1-rate*f(E(θ)/θ1)'
求得导函数后展开为
- θ0=θ0-rate*(f(xi)-yi)'x0
- θ1=θ1-rate*(f(xi)-yi)'*x1
- θ2=θ2-rate*(f(xi)-yi)'*x2
- θ3=θ3-rate*(f(xi)-yi)'*x3
可以抽象为
- θj=θj-rate*(f(xi)-yi)'*xji
- 转化为矩阵计算?
4 python的过程
文章来源:https://blog.csdn.net/xuemanqianshan/article/details/135766884
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- MATLAB 最小二乘直线拟合 (35)
- 十三、Ansible Role 详解
- 接口和抽象类
- 实验4——SQL语言:SELECT查询操作
- TS:.d.ts 文件 和 declare 的作用
- burpsuite专业版破解2023.5.21教程并配置抓包(保姆级)
- Jenkins环境配置篇-更换插件源
- leetcode 19. 删除链表的倒数第 N 个结点 java解法
- 小肥柴的Hadoop之旅
- 手持式气象站便携式气象站 手持超声波风速仪