行列转化【附加面试题】
发布时间:2024年01月18日
在MySQL中,行列转换是一种常见的操作。它包括行转列和列转行两种情况。
- 行转列:行转列是将表中的某些行转换成列,以提供更为清晰、易读的数据视图。例如,假设我们有一个包含科目和分数的表,我们可以使用SUM和CASE语句将每个科目的分数转换为单独的列。此外,从MySQL 8.0版本开始,还提供了PIVOT函数来实现行转列的操作。例如:
SELECT aggregated_column, [pivot_value_1], [pivot_value_2], ..., [pivot_value_n] FROM (select...) AS source_table PIVOT ( aggregate_function (column_for_aggregation) FOR column_for_pivot IN ([pivot_value_1], [pivot_value_2], ..., [pivot_value_n]) ) AS pivot_table; - 列转行:列转行则是将表中的某些列转换成行,每行包含一列的值。具体的操作方法包括使用聚合函数、group_concat函数或动态SQL语句块等。例如,可以使用GROUP_CONCAT函数将某一列的值拼接成一个字符串,然后用聚合函数进行分组。
测试题:
DROP TABLE IF EXISTS `stu`;
CREATE TABLE `stu` (
`sname` varchar(20) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL,
`sub` varchar(20) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL,
`score` varchar(20) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of stu
-- ----------------------------
INSERT INTO `stu` VALUES ('zs', 'chinese', '100');
INSERT INTO `stu` VALUES ('zs', 'math', '99');
INSERT INTO `stu` VALUES ('zs', 'english', '98');
INSERT INTO `stu` VALUES ('li', 'chinese', '80');
INSERT INTO `stu` VALUES ('li', 'math', '89');
INSERT INTO `stu` VALUES ('li', 'english', '88');
INSERT INTO `stu` VALUES ('ww', 'chinese', '70');
INSERT INTO `stu` VALUES ('ww', 'math', '79');
INSERT INTO `stu` VALUES ('ww', 'english', '78');
SET FOREIGN_KEY_CHECKS = 1;
初始化数据:?
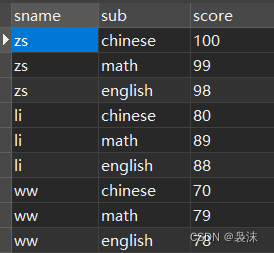
现在进行行列转换:
select sname,
case sub when "chinese" then score end "语文",
case sub when "math" then score end "数学",
case sub when "english" then score end "英语"
from stu;?
?现在进行分组统计,然后合并:
select sname,
max(case sub when "chinese" then score end) "语文",
min(case sub when "math" then score end) "数学",
avg(case sub when "english" then score end) "英语"
from stu
GROUP BY sname;
现在行列转化已经完成!
行转化为列:
小结:case [列名] when [条件] then [数据] end
面试题1:
人员情况表(employee)中字段包括,员工号(ID),姓名(name),年龄(age),文化程度(wh):
包括四种情况(本科以上,大专,高中,初中以下),
现在我要根据年龄字段查询统计出:
表中文化程度为本科以上,大专,高中,初中以下,各有多少人,占总人数多少。
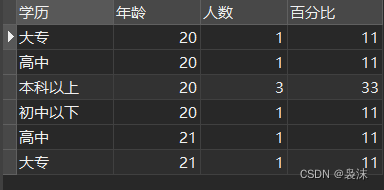
结果如下A:
学历 年龄 人数 百分比
本科以上 20 34 14
大专 20 33 13
高中 20 33 13
初中以下 20 100 40
本科以上 21 50 20
。。。。。。
SQL 查询语句如何写?
create table employee(id int primary key auto_increment,
name varchar(20),
age int(2),
wh varchar(20)
) ;
insert into employee(id,name,age,wh) values (null,'a',20,'本科以上') ;
insert into employee(id,name,age,wh) values (null,'b',20,'本科以上') ;
insert into employee(id,name,age,wh) values (null,'c',21,'本科以上') ;
insert into employee(id,name,age,wh) values (null,'d',20,'本科以上') ;
insert into employee(id,name,age,wh) values (null,'e',20,'大专') ;
insert into employee(id,name,age,wh) values (null,'e',21,'大专') ;
insert into employee(id,name,age,wh) values (null,'e',21,'高中') ;
insert into employee(id,name,age,wh) values (null,'e',20,'高中') ;
insert into employee(id,name,age,wh) values (null,'e',20,'初中以下') ;?起始数据:

通过wh[文化]、age[年龄]分组,即可统计出来:?
select wh '学历',age '年龄',count(*) '人数', round((count(*)/(select count(0) from employee)) * 100) '百分比'
from employee
GROUP BY wh ,age
ORDER BY age;
面试题2:
-- 8:00--12:00 为迟到, 12:00--18:00 为早退
-- 打卡表 card
create table card(
cid int(10),
ctime timestamp ,
cuser int(10)
);
-- 人员表 person
create table person(
pid int(10),
name varchar(10)
) ;
-- 插入人员表的数据
insert into person values(1,'a');
insert into person values(2,'b');
-- 插入打卡的数据
insert into card values(1,'2009-07-19 08:02:00',1);
insert into card values(2,'2009-07-19 18:02:00',1);
insert into card values(3,'2009-07-19 09:02:00',2);
insert into card values(4,'2009-07-19 17:02:00',2);
insert into card values(5,'2009-07-20 08:02:00',1);
insert into card values(6,'2009-07-20 16:02:00',1);
insert into card values(7,'2009-07-20 07:02:00',2);
insert into card values(8,'2009-07-20 20:02:00',2);
-- 查询 迟到 早退的员工姓名?
查询结果如下:
工号 姓名 打卡日期 上班打卡 下班打卡 迟到 早退
1 a 2009-07-19 08:02:00 18:02:00 是 否
1 a 2009-07-20 08:02:00 16:02:00 是 是
2 b 2009-07-19 09:02:00 17:02:00 是 是初始化表:?
?

-- 先查出每一个员工打卡的时间
select p.*,c.ctime
from person p join card c on c.cuser = p.pid;
-- 将日期格式化
select p.pid "工号",p.name "姓名",DATE_FORMAT(c.ctime,'%y-%m-%d') "打卡日期",DATE_FORMAT(c.ctime,'%h:%i:%s') "打卡时间"
from person p join card c on c.cuser = p.pid;
-- 将日期分离成上下午
select p.pid "工号",p.name "姓名",DATE_FORMAT(c.ctime,'%y-%m-%d') "打卡日期",DATE_FORMAT(c.ctime,'%h:%i:%s') "打卡时间"
from person p join card c on c.cuser = p.pid
文章来源:https://blog.csdn.net/qq_58341172/article/details/135658646
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- MySQL定期整理磁盘碎片
- Hack The Box-Sherlocks-Tracer
- springboot(ssm二手手机交易平台 二手机商城系统Java系统
- 大家转行软件测试,简历都是咋写的?
- web开发学习笔记(3.vue)
- 106、Text-Image Conditioned Diffusion for Consistent Text-to-3D Generation
- 从农业到宗教——软件产品开发的五种境界
- 模型部署flask学习篇(二)---- flask用户登录&用户管理
- 【PAT甲级】1175 Professional Ability Test
- 【QT 自研上位机 与 ESP32下位机联调>>>串口控制GPIO-基础样例-联合文章】