读写分离的手段——主从复制,解决读流量大大高于写流量的问题
应用场景
假设说有这么一种业务场景,读流量显著高于写流量,你要怎么优化呢。因为写是要加锁的,可能就会阻塞你读请求。而且其实读多写少的场景还很多见,比如电商平台,用户浏览n多个商品才会买一个。
大部分人的思路可能是建个缓存来帮助 MySQL 抗住大部分的查询请求。但是这不行,因为应用缓存的原则之一是保证缓存命中率足够高,不然很多请求会穿透缓存,最终打到数据库上。不同用户的请求基本上都不一样。
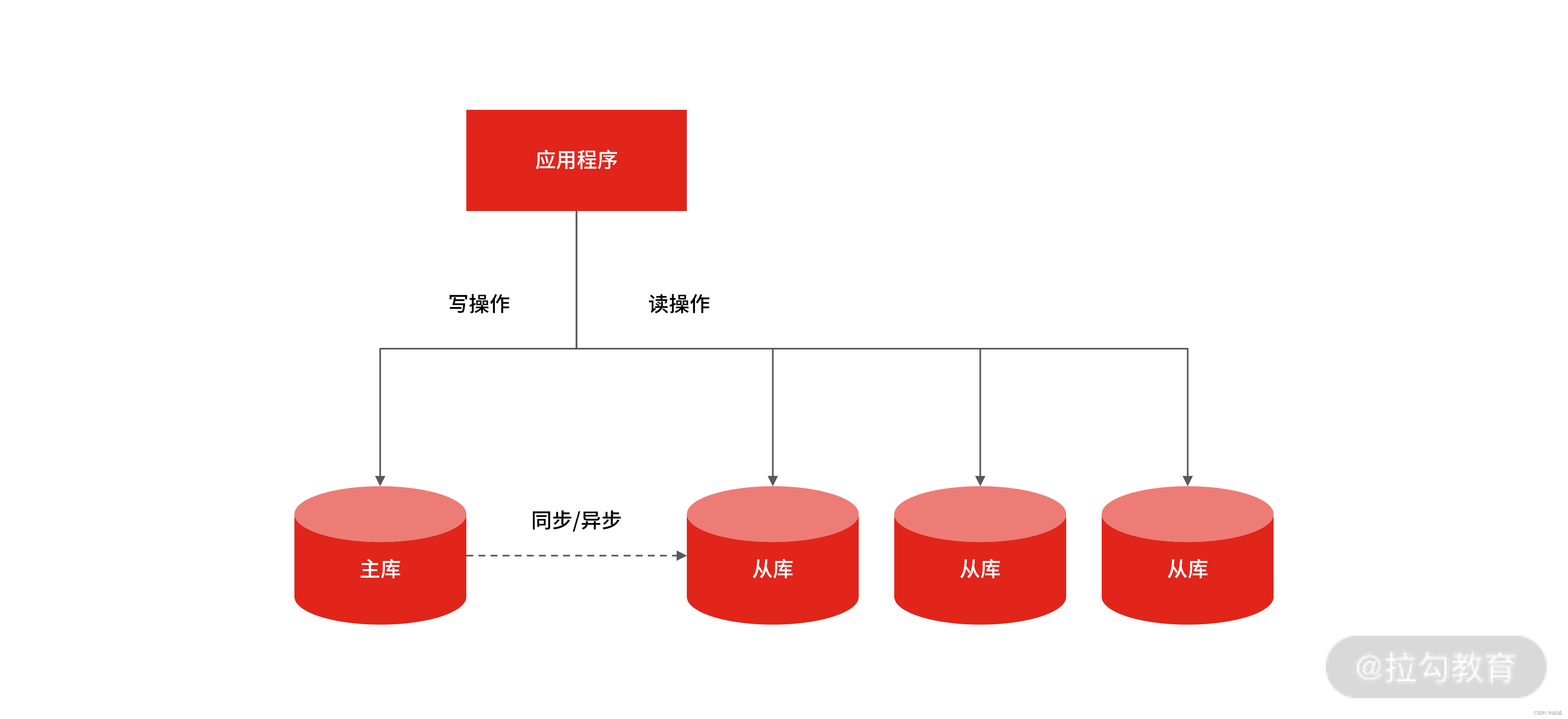
所以你要考虑优化数据库来抗住高查询请求,首先要做的就是区分读写流量区,这样才方便针对读流量做单独扩展,这个过程就是流量的“读写分离”。这是提升MySQL并发性的首选方案,因为当单台 MySQL 无法满足要求时,就只能用多个具有相同数据的 MySQL 实例组成的集群来承担大量的读写请求。
模型种类
那如何实现主从复制呢?答案如下图所示
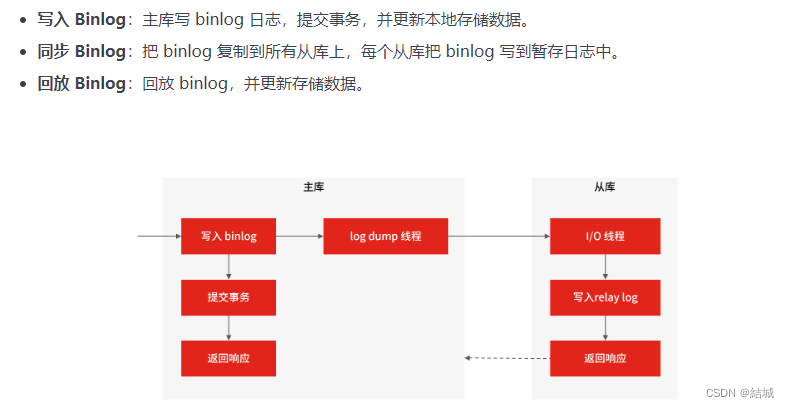
在完成主从复制之后,你就可以在写数据时只写主库,在读数据时只读从库,这样即使写请求会锁表或者锁记录,也不会影响读请求的执行。但是不是说越多从库越好,因为一个从库io线程就需要一个主库log dump线程。所以在实际使用中,一个主库一般跟 2~3 个从库(1 套数据库,1 主 2 从 1 备主),这就是一主多从的 MySQL 集群结构。
同时,主从复制有三种模式:

主从复制的延迟问题怎么解决呢?
比如下面这种情况
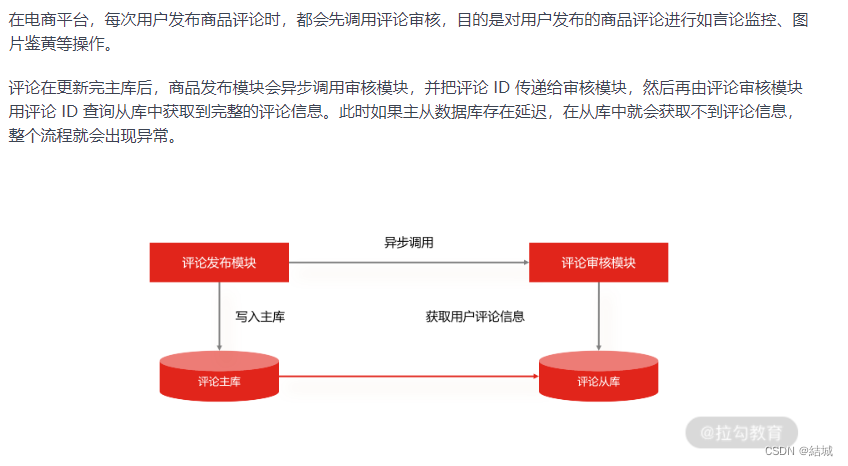
最推荐的是使用数据冗余:可以在异步调用审核模块时,不仅仅发送商品 ID,而是发送审核模块需要的所有评论信息,借此避免在从库中重新查询数据(这个方案简单易实现,推荐你选择)。但你要注意每次调用的参数大小,过大的消息会占用网络带宽和通信时间。
或者加一层缓存,读先读缓存,然后不行再去从库。但这存在一致性问题。
或者直接查询主库,但是要提前明确查询的数据量不大,不然会出现主库写请求锁行,影响读请求的执行,最终对主库造成比较大的压力。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 第二百四十三回 再分享一个Json工具
- C# 代码 - 文件操作相关
- 字节跳动因违反OpenAI服务条款被报道,回应称将澄清误解;OpenAI 官方提示工程指南
- Kubeadm 方式部署K8s集群
- TableConvert:简化API集成,提升广告推广和用户运营效率
- 扎哇面试准备
- 基于Apache POI-操作Excel数据-读写
- 关于java数组的声明及创建
- java+springboot+vue学校二手物品交易管理系统 含卖家
- 常见的并查集题目