《向量数据库指南》RAG 应用中的指代消解——解决方案初探
随着 ChatGPT 等大语言模型(LLM)的不断发展,越来越多的研究人员开始关注语言模型的应用。
其中,检索增强生成(Retrieval-augmented generation,RAG)是一种针对知识密集型 NLP 任务的生成方法,它通过在生成过程中引入检索组件,从已知的知识库中检索相关信息,并将这些信息与 LLM 的生成能力结合,从而提高生成的准确性和可靠性。这种方法可以用于实现各种知识密集型 NLP 任务,如问答、文摘生成、语义推理等。
本文将从解决优化 RAG 系统里的一个具体问题出发,通过展示使用 LLM Prompt Engineering 的方法,来解析传统 NLP 的问题。
01.
解决方案初探
开源项目?Akcio(https://github.com/zc277584121/akcio) 就是一套完整的 RAG 问答系统,用户导入各类私有专业知识,就可以构建专业领域的问答系统。
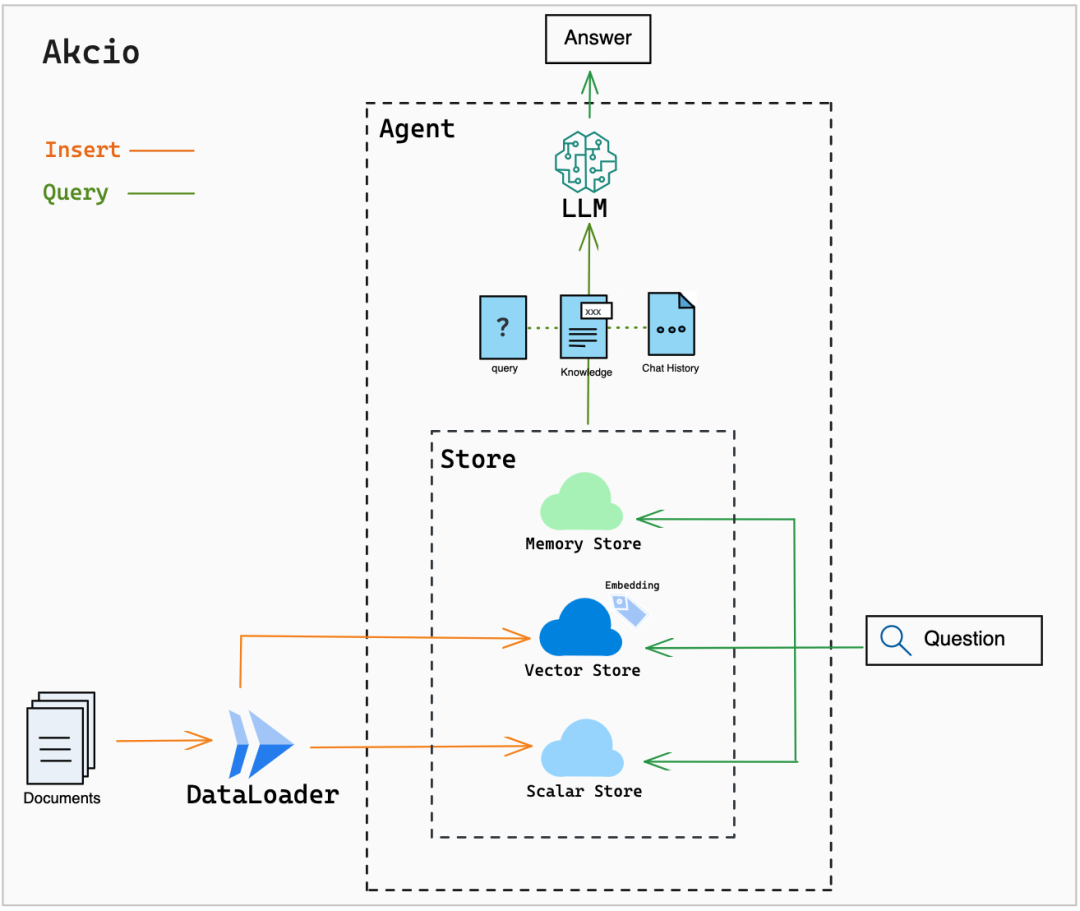
|Akcio 的架构图。专业知识是各类 Documents,通过 DataLoader 导入进 Store。在每次提问 Question 后,LLM 可以结合召回知识,加上 LLM 自身的自然语言生成能力,给出对应的回答。
举个例子,比如我们将一篇名为《2023 大模型落地进展趋势洞察报告》的文章,将它导入 Akcio,就可以问它这篇报告里的问题了,比如:
2023年,大模型行业的应用场景可以分为哪几类?
通过一些召回策略,在 Store 里召回出了《报告》中,与问题最相关的 3 条原文片段:
['在2023年,大模型行业的应用场景可分为生成和决策两类应用场景,决策场景预期业务值更高。',
'大模型行业的生成场景主要有对话交互,代码开发,智能体等。',
'NLP的应用场景有文本分类,机器翻译,情感分析,自动摘要等。']
很显然,最有用的片段是第一条,但没关系,Akcio 会把这 3 条都作为 context,去问 LLM,比如它是这样问的:
请根据下面知识回答问题:
知识:
在2023年,大模型行业的应用场景可分为生成和决策两类应用场景,决策场景预期业务值更高。
大模型行业的生成场景主要有对话交互,代码开发,智能体等。
NLP的应用场景有文本分类,机器翻译,情感分析,自动摘要等。
问题:
2023年,大模型行业的应用场景可以分为哪几类?
LLM 就可以给出合理的回答:
大模型行业的应用场景可以分为生成和决策两类应用场景。
这样的话整条链路就走通了。这套架构逻辑看似并不复杂,但如果深入到开发过程中,就会发现其中有一些难点需要解决。
比如在多轮对话的情况下,就需要解决一个问题:如果在最新一轮的提问,里面有些指代上文的代词,那么如果直接用这个问题去做召回,很可能会召回错误的知识,比如:
问1:?2023年,大模型行业的应用场景可以分为哪几类?
答1:?大模型行业的应用场景可以分为生成和决策两类应用场景。
问2:?它们有什么区别,能举例说明吗?
这里的“它们”很显然指的是“生成和决策两类应用场景”,问题的原意是“生成和决策场景有什么区别,能举例说明吗?”。但如果直接用这个问题“它们有什么区别,能举例说明吗?”去做召回,那很有可能召回的是比如这样的知识片段:
['BERT和GPT都是NLP领域的重要模型,但它们的设计和应用场景有很大的区别。',
'大模型和小模型的区别在于其规模和复杂度。大模型通常具有更多的参数和更复杂的结构,需要更多的计算资源和时间来训练和推理。而小模型则相对简单,参数较少,训练和推理速度较快。',
'但没有更多的信息来区分这两个产品,因为它们看起来非常相似。']
显然主体错了,那用这些召回的知识肯定也就不对了,LLM 利用这些无用的知识也不用给用户很好的回答了。
那么要解决这个问题有什么好的办法呢?
首先可以想到的是NLP领域中的一个常见任务:指代消解(Coreference resolution)。指代消解是自然语言处理(NLP)中的一项重要任务,用于确定文本中指代相同实体的词语。该任务旨在识别代词、名词短语等,将它们与先前提到的实体关联起来。例如,在句子“John saw Mary. He waved to her.”中,coreference resolution会将“He”和“John”以及“her”和“Mary”归纳为同一实体。
也许这个任务可以帮助我们解决这个问题,但经过实践发现,无论是通过 spacy,还是 huggingface,目前的开源模型,处理指代消解这个任务都有一定的局限性,只能处理比较简单的场景,比如:
问1:大模型是什么?
问2:它有什么用?
可以找出“它”指的是“大模型”。然而,对于复杂的指代,却不能识别出来,比如:
问1:GPT3是什么?
问2:GPT4又是什么时候发布的?
问3:二者有什么区别?后者有什么优势?
没法识别出“二者”指的是 GPT3 和 GPT4,“后者”指的是“GPT4”。再比如:
问1:GPT4又是什么时候发布的?
答1:GPT4是在?2023?年发布的
问2:这一年在计算机视觉有什么进展?
没法识别出“这一年”指的是“2023年”。
也就是说,现有的 NLP 小模型,只能处理识别“它”,“他”,“她”,“这个”等简单的代词,而对于复杂的指代表述,没法识别处理。
那该怎么办呢?对于复杂语言场景,也许最好的处理就是用大模型,毕竟 ChatGPT 火爆时可是号称是“让 NLP 不存在的”的终极武器。于是,我们可以尝试,让 LLM 来做这个指代消解任务。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Where in memory are my variables stored in C?
- Android APP修改为鸿蒙APP需要注意的问题
- springboot(ssm在线互动学习网站 在线课程管理系统 Java系统
- 力扣454 四数相加Ⅱ
- three.js从入门到精通系列教程007 - three.js绘制空心扇形和实心扇形
- 【Java SE】java中继承详解
- Java中的变量和数据类型
- kill编译异常处理
- 用栈实现队列&&
- 《微信小程序开发从入门到实战》学习八十三