Python学习之路——文件部分【文件的读取】
目录
先解释一下引文的答案
read返回的是字符串类型,可以指定读取的字节数,不指定默认读取全部
readline返回的是字符串,读取文件内一行的内容
readlines返回的是列表,读取文件内的全部内容,以行为单位,列表内的每一个元素就是一行
一、open()打开函数
在Python中,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件,语法如下:
# open(name, mode, encoding)
# name:是要打开的目录文件名的字符串(可以包含文件所在的具体路径)。
# mode:设置打开文件的模式(访问模式):只读、写入、追加等。
# encoding:编码格式(推荐使用utf-8ctrl + 鼠标左键,进入源码,发现encoding并不是第三个参数,所以要使用关键字参数关键字参数![]() https://blog.csdn.net/weixin_57154777/article/details/135400272?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_57154777/article/details/135400272?spm=1001.2014.3001.5501

二、mode常用的三种基础访问模式
| 模式 | 描述 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头,这是默认模式 |
| w | 打开一个文件只用于写入,如果该文件已存在则打开文件,并从开头开始编辑, 原有内容会被删除。如果该文件不存在,创建新文件 |
| a | 打开一个文件用于追加,如果该文件已存在,新的内容将会被写入到已有的内容之后。 如果该文件不存在,创建新文件进行写入 |
三、读-操作相关方法
(一)read方法
文件对象.read(num)num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据。返回的是字符串。
(二)readlines方法
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。
在D盘下创建一个文件python.txt,里面添加内容如下:

使用readlines读取文件内的内容
f = open('D:/python.txt', 'r', encoding='utf-8')
ff = f.readlines()
for line in ff:
print(line)
# 也可以
content = f.readlines()
print(content)
# 不管前面如何操作,一定要记得关闭文件
f.close()
其中有空白行的就是读取到了\n换行符
(三)with open 语法
with open('D:/python.txt', 'r') as f:
f.readlines()
# 通过with open的语句对文件进行操作
# 可以在操作完成后自动关闭文件,避免遗忘掉close方法(四)操作汇总
| 操作 | 功能 |
| 文件对象 = open(file,mode,encoding) | 打开文件获得文件对象 |
| 文件对象.read(num) | 读取指定长度字节 不指定num读取文件全部 |
| 文件对象.readline() | 读取一行 |
| 文件对象.readlines() | 读取全部行,得到列表 |
| for line in 文件对象 | for循环文件行,依次循环得到一行数据 |
| 文件对象.close() | 关闭文件对象 |
| with open() as f | 通过with open语法打开文件,可以自动关闭 |
(五)注意
操作完成之后一定要用close()方法去关闭文件,不然文件就会一直被占用,进行不了其他的操作
(六)代码示例
1、打开文件
2、read读取文件
3、readlines读取文件
# 打开文件
f = open('D:/python.txt', 'r', encoding='utf-8')
# 读取文件 read()
content01 = f.read()
print(content01)
# 读取文件 readLines()
content02 = f.readlines()
print(content02)思考一下,这段代码会不会报错
是的,虽然不会报错,但是readlines读取不到文件的内容,列表为空

这是为什么呢,当然是因为没有关闭文件咯
# 打开文件
f = open('D:/python.txt', 'r', encoding='utf-8')
# 读取文件 read()
content01 = f.read()
print(content01)
# 关闭文件
f.close()
# 读取文件 readLines()
content02 = f.readlines()
print(content02)那现在我添加了关闭文件的方法之后,这样对吗?
答案是不对的,你都把文件关了,还怎么去读取文件里面的内容呢:
这样才是正确的
# 打开文件
f1 = open('D:/python.txt', 'r', encoding='utf-8')
# 读取文件 read()
content01 = f1.read()
print(content01)
f1.close()
# 读取文件 readLines()
f2 = open('D:/python.txt', 'r', encoding='utf-8')
content02 = f2.readlines()
print(content02)
f2.close()
切记一定要关闭文件,如若之后还要操作文件记得要打开,那么要打开就一定要关闭,以此递归思想,绝不会出错
4、readline读取文件
读取文件的一行的内容
print()
print('readline:')
# 读取文件 readLine()——————一次读取一行
f3 = open('D:/python.txt', 'r', encoding='utf-8')
content03 = f3.readline()
print(content03)
# for循环读取文件行
for line in f3:
print(line)
5、文件关闭
文件关闭我们就不能只说文件关闭
我们应该
# 文件的关闭
if f3.closed:
print('文件关闭成功')
else:
f3.close()
print('文件关闭失败,已执行关闭操作') # with open 语法操作文件
with open('D:/python.txt', 'r', encoding='utf-8') as f4:
print(f4.read())
if f4.closed:
print('文件关闭成功')
else:
f4.close()
print('文件关闭失败,已执行关闭操作')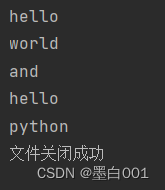
四、练习案例
统计单词在文件内出现的次数
文件内准备如下内容:

统计句子中you的出现次数
上操作
def func03():
f = open('D:/python.txt', 'r', encoding='utf-8')
file_of_str = f.read()
file_of_str = file_of_str.strip()
file_of_str = file_of_str.replace('\n', ' ')
file_of_str = file_of_str.replace('.', ' ')
file_of_str = file_of_str.split(' ')
print('split', file_of_str, type(file_of_str))
count = 0
for word in file_of_str:
if word == 'you':
count += 1
print(count)
f.close()详细操作与解释
def func03():
# 先打开文件进行读取
f = open('D:/python.txt', 'r', encoding='utf-8')
# 查看文件是否打开成功
# print(f.read())
# 或者怕忘记最后去close文件,可以使用
# with open('D:/python.txt', 'r', encoding='utf-8') as f:
# print(f.read())
# 成功读取文件内容之后,将文件内的句子的换行符和英文结尾符以及逗号都替换为空格
# 由于 read 方法读取文件返回的是字符串类型,所以可以
file_of_str = f.read()
file_of_str = file_of_str.strip()
file_of_str = file_of_str.replace('\n', ' ')
file_of_str = file_of_str.replace('.', ' ')
# 将字符串通过空格进行分隔得到列表(或者一开始就可以使用readlines去获取列表)
file_of_str = file_of_str.split(' ')
print('split', file_of_str, type(file_of_str))
# 遍历列表
# 定义一个用于计数的变量,初始化为0
count = 0
for word in file_of_str:
if word == 'you':
count += 1
print(count)
f.close()再次强调一遍,文件操作完成之后,一定要关闭文件
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 掌握私域运营的四大原则,助你打造精准营销
- C语言经典练习3——[NOIP2008]ISBN号码与圣诞树
- nginx反向代理
- 纯HTML代码实现给图片增加水印并下载保存到本地
- 【RT-DETR有效改进】带你分析如何确定改进的基础模型,解决模型无法收敛精度很差的问题(ResNet官方一比一复现)
- JavaScript初级知识(4)
- 当电脑中的回收站消失时,你至少可以用11种方法找到它
- PHP网站响应慢了或者502了,如何快速定位错误信息的
- Linux系统MySQL8 root密码忘记解决方法(亲测有效)
- 使用自带密钥 (BYOK) 的Azure信息保护云退出