SQL进阶 | HAVING子句
概述
????????“HAVING”其用法和含义与“WHERE”关键词相似,但具有更高级别的限定性。在SELECT语句中,“HAVING”关键词用于过滤聚合函数的结果。与“WHERE”关键词不同的是,“HAVING”关键词不能用于过滤单个行,它主要用于过滤由GROUP BY子句分组的结果集。
寻找缺失的编号
? ? ? ? 有这样一张表,它的编号不是连续性的,需要判断这张表是否存在有缺失的编号。


select '存在缺失的编号' as gap
from seqtbl
having count(*) <> max(seq)????????如果这个查询结果有 1 行,说明存在缺失的编号;如果 1 行都没有,说明不存在缺失的编号。这是因为,如果用 COUNT(*) 统计出来的行数等于“连续编号”列的最大值,就说明编号从开始到最后是连续递增的,中间没有缺失。如果有缺失,COUNT(*) 会小于 MAX(seq),这样 HAVING 子句就变成真了。
????????而在这条SQL中,并没有与GROUP BY子句结合使用,由此可以看出HAVING子句也可以单独使用,对象则是整个查询结果集合。
????????接下来,再来查询一下缺失编号的最小值。求最小值要用 MIN 函数,因此我们像下面这样写SQL 语句。
-- 查询缺失编号的最小值
select min(seq + 1) as gap
from seqtbl
where (seq + 1) not in (select seq from seqtbl) ?
?
????????使用 NOT IN 进行的子查询针对某一个编号,检查了比它大 1 的编号是否存在于表中。然后,“3, 莱露”“6, 玛丽”“8, 本”这几行因为找不到紧接着的下一个编号,所以子查询的结果为真。如果没有缺失的编号,则查询到的结果是最大编号 8 的下一个编号 9。?
用 HAVING 子句进行子查询 :求众数

-- 求众数的sql语句1:使用谓词
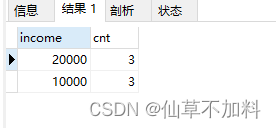
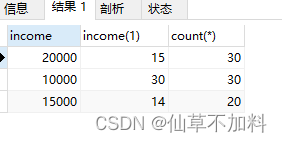
select income,count(*) as cnt from graduates
group by income
having count(*) >= all(select count(*) from graduates group by income);?????????在子查询中对income分组,统计分组后每种收入的记录数,然后再使用ALL谓词判断分组后行号比子查询中所有的行号都大和相等的结果。
????????ALL 谓词用于 NULL 或空集时会出现问题,可以用极值函数来代替。
-- 求众数的sql语句2:使用极值函数
select income,count(*) as cnt
from graduates
group by income
having count(*) >=
(select max(cnt)
from (select count(*) as cnt
from graduates
group by income) tmp);? ? ? ? 在这条SQL中,子查询先获取分组后每个income的行数,再使用MAX函数获取最大值,最后判断分组后的行数大于等于最大的行数获取结果。
?
用 HAVING 子句进行自连接 :求中位数
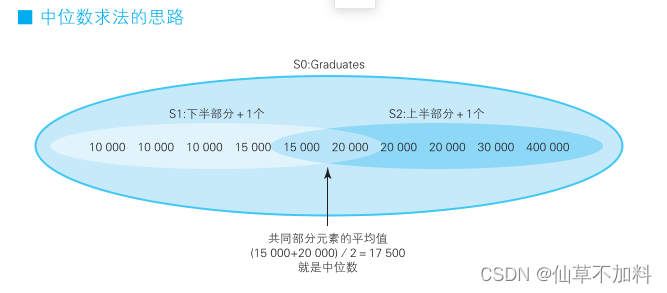
? ? ? ? 这里书上给的思路是将集合里的元素按照大小分为上半部分和下半部分两个子集,同时让这 2 个子集共同拥有集合正中间的元素。这样,共同部分的元素的平均值就是中位数,思路如下图所示。
-- 求中位数的sql语句:在having子句中使用非等值自连接
select avg(distinct income)
from (select t1.income from graduates t1,graduates t2 group by t1.income
-- s1的条件
having sum(case when t2.income >= t1.income then 1 else 0 end) >= count(*)/2
-- s2的条件
and sum(case when t2.income <= t1.income then 1 else 0 end) >= count(*)/2) tmp;
? ? ? ? 这里的代码不是很好理解,我们把这条SQL拆分来看。
-- 获取笛卡尔积
select t1.income,t2.income from graduates t1,graduates t2
-- 上半区条件:如果t1中income 大于 t2中的income,则flag记为 1,小于则记为 0
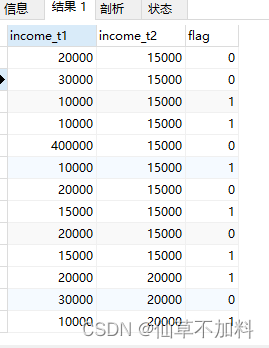
select t1.income as income_t1,t2.income as income_t2,
(case when t1.income >= t2.income then 1 else 0 end) as flag
from graduates t1,graduates t2
-- 下半区条件:如果t1中income 小于 t2中的income,则flag记为 1,小于则记为 0
select t1.income as income_t1,t2.income as income_t2,(case when t1.income <= t2.income then 1 else 0 end) as flag
from graduates t1,graduates t2
-- 分组统计 上半区条件
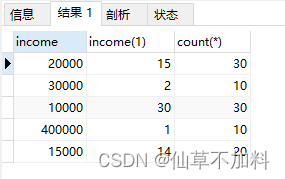
select t1.income,
sum(case when t1.income >= t2.income then 1 else 0 end) as income,count(*)
from graduates t1,graduates t2
group by t1.income
-- 分组统计 下半区条件
select t1.income,
sum(case when t1.income <= t2.income then 1 else 0 end) as income,count(*)
from graduates t1,graduates t2
group by t1.income ?
?
-- 分组统计上半区s1
select t1.income,
sum(case when t1.income >= t2.income then 1 else 0 end) as income,count(*)
from graduates t1,graduates t2
group by t1.income
having sum(case when t1.income >= t2.income then 1 else 0 end) >= count(*)/2
-- 分组统计下半区s2
select t1.income,
sum(case when t1.income <= t2.income then 1 else 0 end) as income,count(*)
from graduates t1,graduates t2
group by t1.income
having sum(case when t1.income >= t2.income then 1 else 0 end) >= count(*)/2
-- 求交集
select t1.income from graduates t1,graduates t2
group by t1.income having sum(case when t1.income >= t2.income then 1 else 0 end) >= count(*)/2
intersect
select t1.income from graduates t1,graduates t2
group by t1.income having sum(case when t1.income <= t2.income then 1 else 0 end) >= count(*)/2
? ? ? ? 拆分开来,这条SQL就清晰很多了。要点在于比较条件“>= COUNT(*)/2”里的等号,这个等号是有意地加上的。加上等号并不是为了清晰地分开子集 S1 和S2,而是为了让这 2 个子集拥有共同部分。如果去掉等号,将条件改成“> COUNT(*)/2”,那么当元素个数为偶数时,S1 和 S2 就没有共同的元素了,也就无法求出中位数了。
查询不包含 NULL 的集合

?????????学生提交报告后,“提交日期”列会被写入日期,而提交之前是NULL。现在我们需要从这张表里找出哪些学院的学生全部都提交了报告(即理学院、经济学院)。做法是:对dpt进行分组,判断分组后个学院的记录数与提交日期不为空的记录数是否相等。
-- 查询“提交日期”列内不包含null的学院1:使用count函数
select dpt from students1
group by dpt
having count(*) = count(sbmt_date);
-- 查询“提交日期”列内不包含null的学院2:使用case表达式
select dpt from students1
group by dpt
having count(*) = sum(case when sbmt_date is not null then 1 else 0 end);
?用关系除法运算进行购物篮分析
????????假设有这样两张表:全国连锁折扣店的商品表 Items,以及各个店铺的库存管理表 ShopItems。
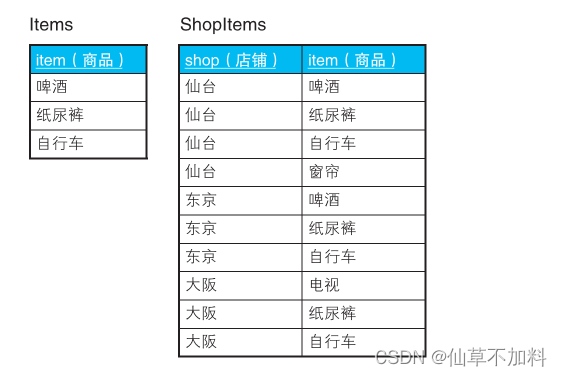
????????这次我们要查询的是囊括了表 Items 中所有商品的店铺。也就是说,要查询的是仙台店和东京店。
select si.shop from shopitems si,items i
where si.item = i.item
group by si.shop
having count(si.item) = (select count(item) from items);????????HAVING 子句的子查询 (SELECT COUNT(item) FROM Items) 的返回值是常量 3。因此,对商品表和店铺的库存管理表进行连接操作后结果是3 行的店铺会被选中;对没有啤酒的大阪店进行连接操作后结果是 2 行,所以大阪店不会被选中;而仙台店则因为(仙台 , 窗帘)的行在表连接时会被排除掉,所以也会被选中;另外,东京店则因为连接后结果是 3 行,所以当然也会被选中。
 ?
?
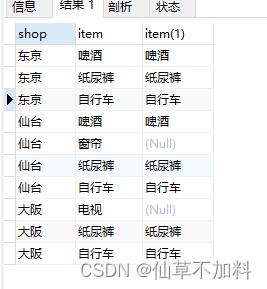
接下来我们把条件变一下,看看如何排除掉仙台店(仙台店的仓库中存在“窗帘”,但商品表里没有“窗帘”),让结果里只出现东京店。
-- 精确关系除法运算:使用外连接和count函数
select si.shop
from shopitems si left outer join items i on si.item = i.item
group by si.shop
having count(si.item) = (select count(item) from items) -- 条件1
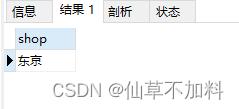
and count(i.item) = (select count(item) from items); -- 条件2使用外连接查询到的结果集如下图所示。在条件1中?得到的结果是东京和大阪,条件2得到的结果只有东京,两者取交集得到最终的结果东京。
?总结
- 表不是文件,记录也没有顺序,所以 SQL 不进行排序。
- SQL 不是面向过程语言,没有循环、条件分支、赋值操作。
- SQL 通过不断生成子集来求得目标集合。SQL 不像面向过程语言那样通过画流程图来思考问题,而是通过画集合的关系图来思考。
- GROUP BY 子句可以用来生成子集。
- WHERE 子句用来调查集合元素的性质,而 HAVING 子句用来调查集合本身的性质。
练习题?
1.在“寻找缺失的编号”部分,我们写了一条 SQL 语句,让程序只在存在缺失的编号时返回结果。请将 SQL 语句修改成始终返回一行结果,即存在缺失的编号时返回“存在缺失的编号”,不存在缺失的编号时返回“不存在缺失的编号”。
-- 1-4-1 修改编号缺失的检查逻辑,是结果总是返回一行数据
select case when
count(*) <> max(seq) then '存在缺失编号' else '不存在缺失编号' end as gap
from seqtbl2.使用正文中的表 Students,查询“全体学生都在 9 月份提交了报告的学院”。
-- 1-4-2 查询全体学生都在9月份提交了报告的学院
select dpt
from students1
group by dpt
having count(*) = sum(case when
sbmt_date between '2005-09-01' and '2005-09-30' then 1 else 0 end); ?
?
3.对于没有备齐全部商品类型的店铺,我们也希望返回的一览表能展示这些店铺缺少多少种商品。my_item_cnt 是店铺的现有库存商品种类数,diff_cnt 是不足的商品种类数。
-- 1-4-3 查询没有备齐全部商品类型的店铺
select si.shop,count(si.item = i.item) as my_item_cnt,(select count(item) from items) - count(si.item = i.item) as diff_cnt
from shopitems si left join items i on si.item = i.item
group by si.shop;
select si.shop,count(si.item) as my_item_cnt,(select count(item) from items) - count(si.item = i.item) as diff_cnt
from shopitems si,items i
where si.item = i.item
group by si.shop;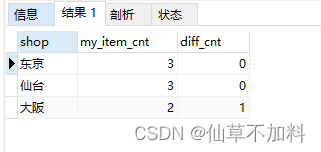
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- odoo17后台启动过程5——Ir.http
- STM32定时器之输入捕获实验和PWM控制呼吸灯实验
- 2024新趋势下的“电力行业数字化转型建设方案”
- String类常用方法(Java)
- 实战篇:一文讲清楚商品分析之返货品画像分析怎么做
- 【vue】jenkins打前端包时报错:第 8 行:cd: dist: 没有那个文件或目录
- 排查 JVM 中的 OOM 问题详细指南
- 基本数据类型、标识符、键盘录入(java)
- BurpSuite基本使用(持续更新中)
- Python实现基于多元线性回归模型进行统计学相互作用和方差分析(anova算法)项目实战