RDD入门——RDD 概念
?RDD 在哪
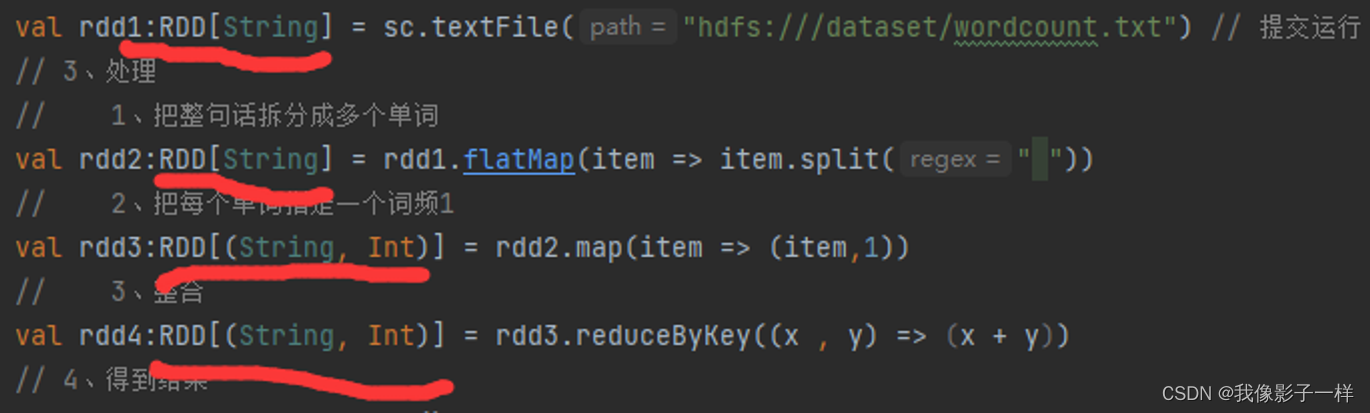
RDD是什么
-
RDD,全称为 Resilient Distributed Datasets ,是一个容错的,并行的数据结构,可以让用户显式地将数据存储到磁盘和内存中,并能控制数据的分区
-
同时,RDD还提供了一组丰富的操作来操作这些数据. 在这些操作中,诸如map, flatMap, filter 等转换操作实现了 Monad 模式,
很好地契合了Scala的集合操作. 除此之外,RDD还提供了诸如join,groupBy,reduceByKey 等更为方便的操作,以支持常见的数据运算
-
通常来讲,针对数据处理有几种常见模型,包括:Iterative Algorithms, Relational Queries, MapReduce, Stream Processing
例如 Hadoop MapReduce 采用了MapReduce模型,Storm则采用了Stream Processing模型.RDD混合了这四种模型,使得 Spark可以应用于各种大数据处理场景,
-
RDD 作为数据结构. 本质上是一个只的分区记录集合. 一个RDD可以包含多个分区,每个分区就是一个DataSet片段
-
RDD之间可以相互依赖,如果RDD的每个分区最多只能被一个子RDD的一个分区使用,则称之为窄依赖,若被多个子RDD的分 区依赖,则称之为宽依赖. 不同的操作依据其特性,可能会产生不同的依赖. 例如mp操作会产生窄依赖,而join 操作则产生宽依赖
RDD的特点
- RDD 是数据集
- RDD 是编程模型
- RDD 相互之间有依赖
- RDD 是可以分区的
补充
RDD的分区:
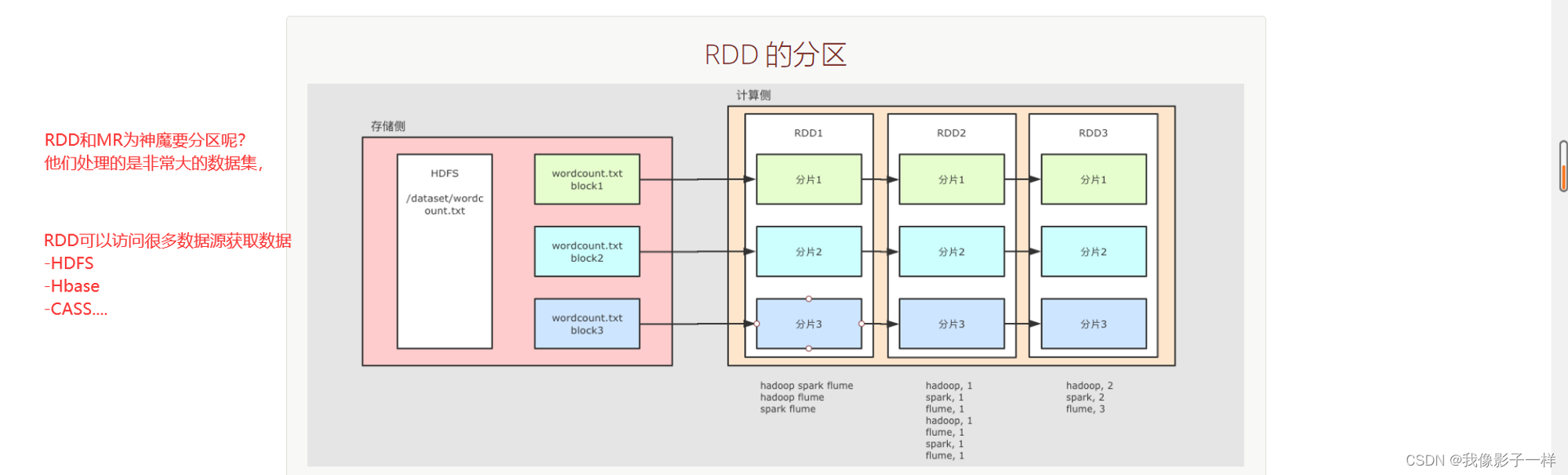
整个 WordCount 案例的程序从结构上可以用上图表示, 分为两个大部分
存储
文件如果存放在 HDFS 上, 是分块的, 类似上图所示, 这个?wordcount.txt分了三块
计算
Spark 不止可以读取 HDFS, Spark 还可以读取很多其它的数据集, Spark 可以从数据集中创建出 RDD
例如上图中, 使用了一个 RDD 表示 HDFS 上的某一个文件, 这个文件在 HDFS 中是分三块, 那么 RDD 在读取的时候就也有三个分区, 每个 RDD 的分区对应了一个 HDFS 的分块
后续 RDD 在计算的时候, 可以更改分区, 也可以保持三个分区, 每个分区之间有依赖关系, 例如说 RDD2 的分区一依赖了 RDD1 的分区一
RDD 之所以要设计为有分区的, 是因为要进行分布式计算, 每个不同的分区可以在不同的线程, 或者进程, 甚至节点中, 从而做到并行计算
总结
- RDD 是弹性分布式数据集
- RDD 一个非常重要的前提和基础是RDD运行在分布式环境下,其可以分区
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【CBY_231225】Kmeans聚类及LSTM时间序列预测
- 图书管理系统——Java web
- vue2中使用Tinymce,刷新页面提示“系统可能不会保存您所做的更改”,去掉该提示的办法
- GPIO简单介绍
- 5.3 内容管理模块 - 课程发布、任务调度、页面静态化、熔断降级
- 最短代码实现随机打乱数组各个元素的顺序
- 网络安全--扫描技术
- 蓝桥杯嵌入式点灯和按键
- Spring Boot与微服务测试:JUnit和Mockito的单元和集成测试实践
- Qt/C++控件设计器/属性栏/组态/可导入导出/中文属性/串口网络/拖曳开发