【Spark精讲】记一个SparkSQL引擎层面的优化:SortMergeJoinExec
SparkSQL的Join执行流程
如下图所示,在分析不同类型的Join具体执行之前,先介绍Join执行的基本框架,框架中的一些概念和定义是在不同的SQL场景中使用的。
在Spark SQL中Join的实现都基于一个基本的流程,根据角色的不同,参与Join的两张表分别被称为"流式表"和"构建表",不同表的角色在Spark SQL中会通过一定的策略进行设定,通常来讲,系统会默认大表为流式表,将小表设定为构建表。
流式表的迭代器为StreamIterator,构建表的迭代器为BuildIterator。通过遍历StreamIterator中的每条记录,然后在BuildIterator中查找相匹配的记录,这个查找过程被称为Build过程,每次Build操作的结果为一条JoinedRow(A,B),其中A来自StreamIterator,B来自BuildIterator,这个过程为BuildRight操作,而如果B来自StreamIterator,A来自BuildIterator,则为BuildLeft操作。
对于LeftOuter、RightOuter、LeftSemi、RightSemi,他们的build类型是确定的,即LeftOuter、LeftSemi为BuildRight类型,RightOuter、RightSemi为BuildLeft类型。
在具体的Join实现层面,Spark SQL提供了BroadcastHashJoinExec、SortMergeJoinExec、ShuffledHashJoinExec、CartesianProductExec、BroadcastNestedLoopJoinExec五种机制。
Join策略的优先级顺序:
-
Broadcast Hash Join > Sort Merge Join > Shuffle Hash Join > Cartesian Join > Broadcast Nested Loop Join.

SortMergeJoinExec执行流程
用一个实际的例子来说明
select name,score from student join exam on student.id = exam_student_id;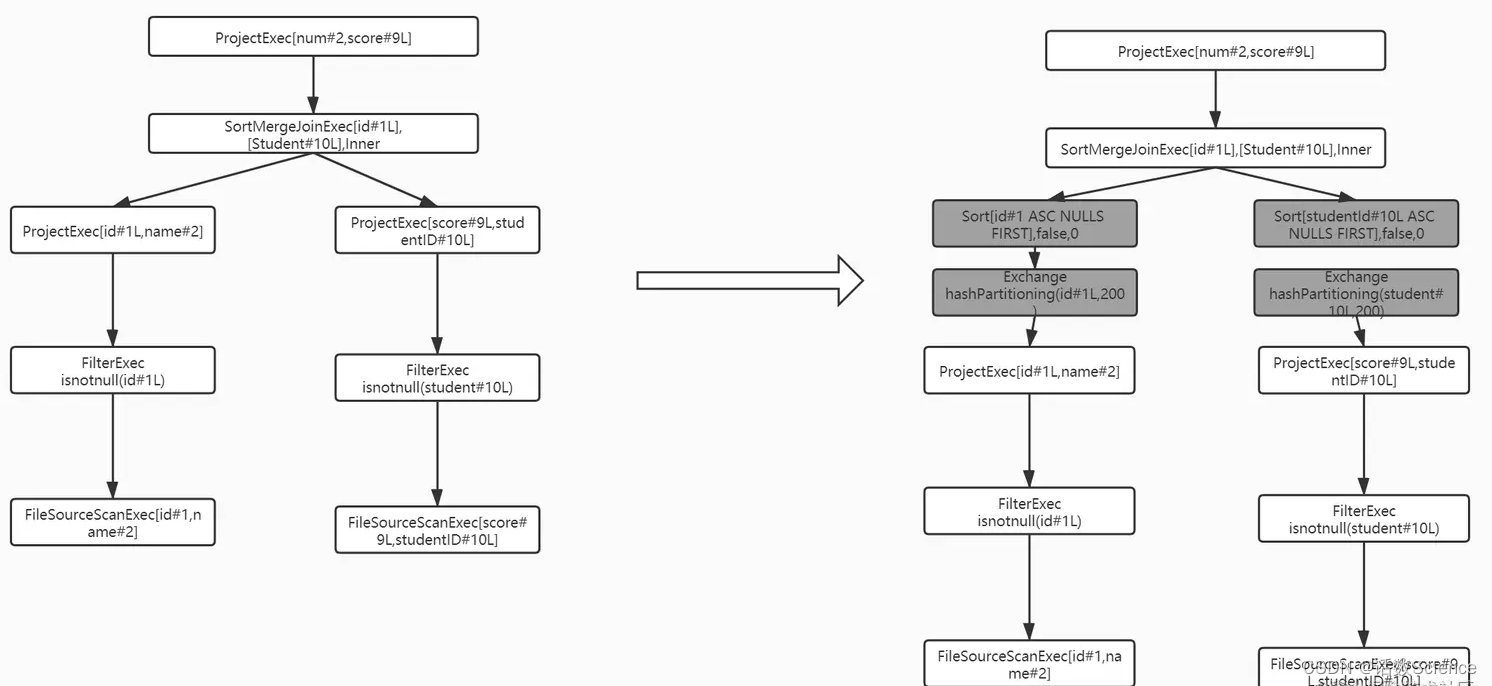
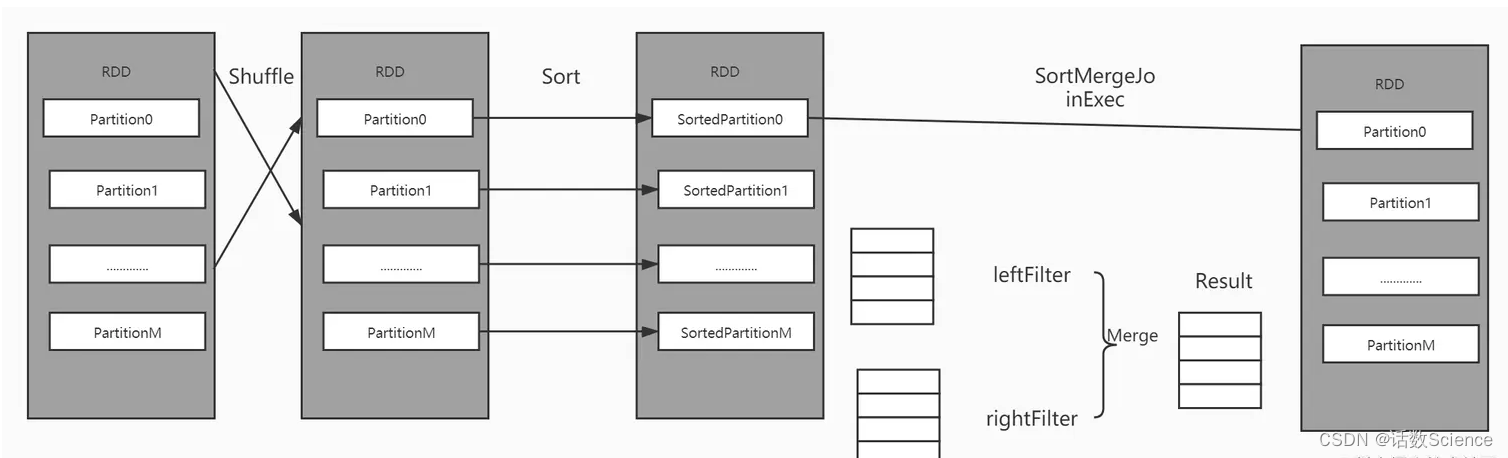
SortMergeJoin的实现方式并不用将一侧的数据全部加载后进行Join操作,其前提条件是需要在Join操作前将数据排序,为了让两条记录链接到一起,需要将具有相同Key记录分发到同一个分区,因此一般会进行一次Shuffle操作(即物理执行计划中的Exchange节点),根据Key分区,将连接到一起的记录分发到同一个分区内,这样在后续的Shuffle阶段就可以将两个表中具有相同Key记录分到同一个分区处理.
经过Exchange节点操作之后,分别对两个表中每个分区里的数据按照key进行排序(图中的SortExec节点) ,然后在此基础上进行sort排序,在遍历流式表,对于每条记录而言,都采用顺序查找的方式从构建查找表中查找对应的记录,由于排序的特性,每次处理完一条记录后只需要从上一次结束的位置开始查找,SortMergeJoinExec执行时就能够避免大量无用的操作,对于提升性能很有帮助,具体原理如下:
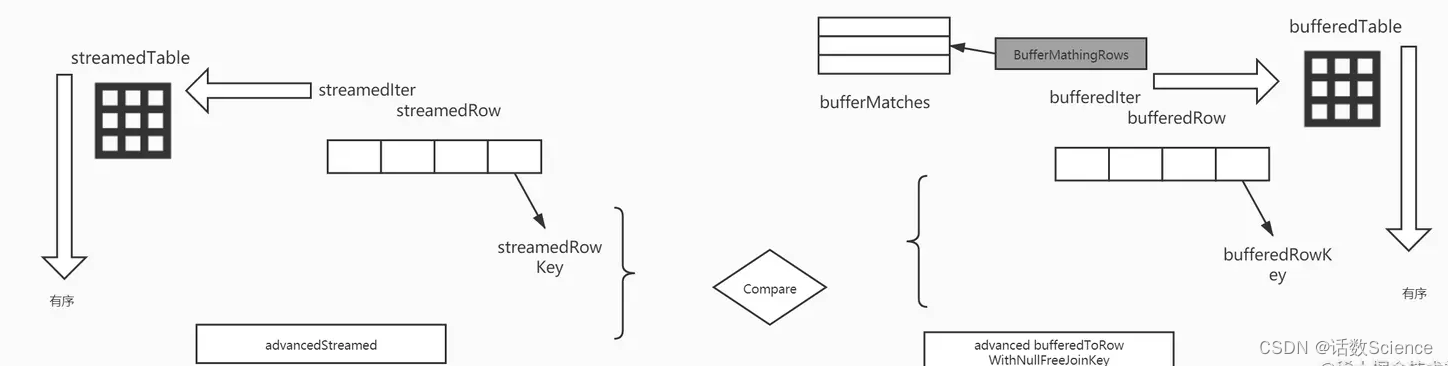
对于查找数据匹配的核心类SortMergeScanner,在SortMergeJoinScanner的构造参数中会传入StreamedTable迭代器和BufferTable的迭代器(BufferTable),因为二者是已经排序好的,所以只需要不断以动迭代器,得到新的数据进行比较即可
SortMergeExec的性能优化:预排序Join
在Shuffle之前,Map阶段会按照key的hash值对数据进行重分区,相同的key被分到同一个分区内,不同Mapper中相同分区的数据会被Shuffle到同一个Reducer。Reducer会对来自不同Mapper的数据进行排序,然后对排序的数据进行Join。
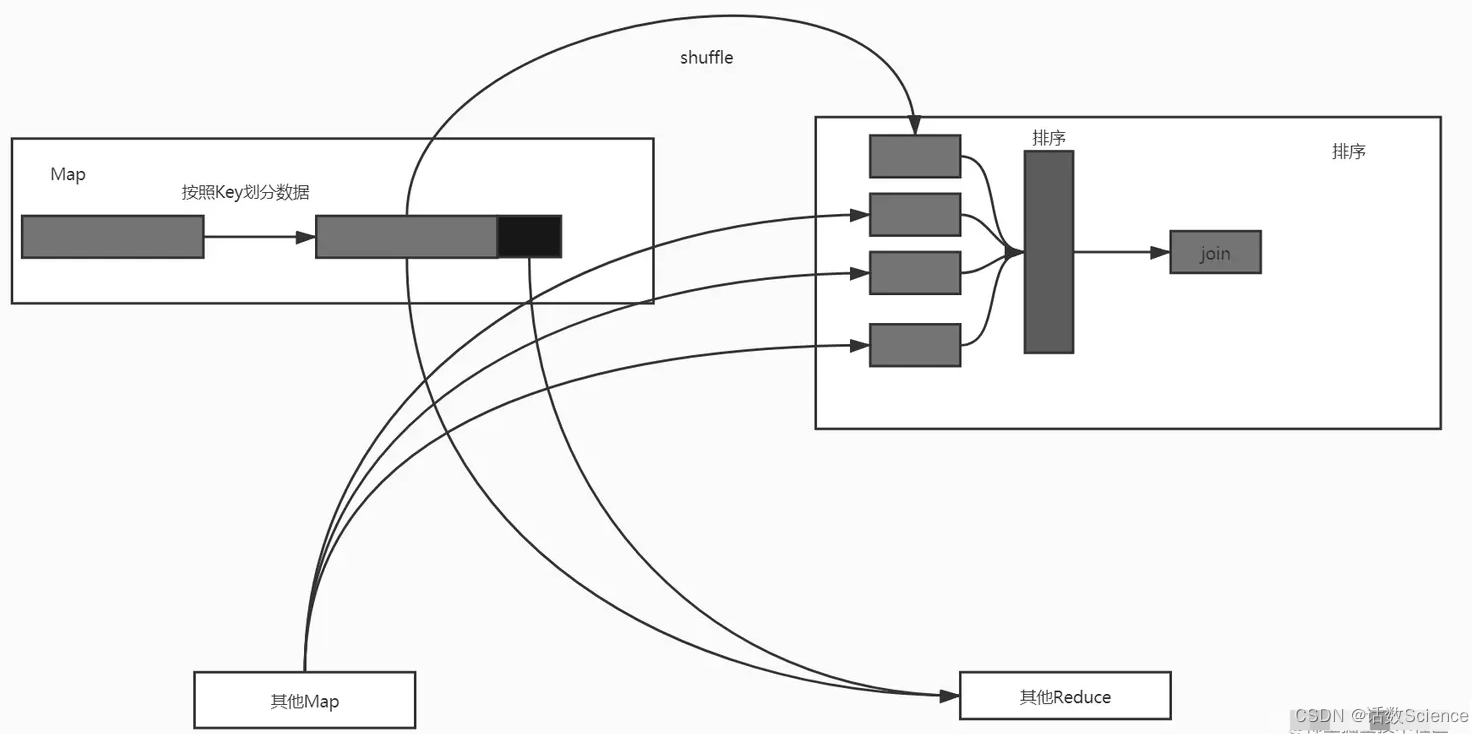
这种机制的不同之处是,当Reducer数量较少时,会造成Reducer处理的数据量比较大。所以可以把数据排序提前到Mapper阶段,Map阶段会按照key的hash值对数据重新分区并按照key进行排序,Recuder只需要对来自不同Mapper的数据进行归并排序。mergeSpill将所有insertRecord中的小文件进行合并,每次从spilled文件中取出一个属于当前partition的最小值并写入文件中,如果没有当前partition的数据,则换到下一个partition,直到所有数据被取出。
def joinShuffleWrite(Iterator<Product2<K,V>> records){
while(records.hasNext())
sorter.insertRecord(record.next())
end while
mergeSpills()
}
def insertRecord(Object record){
if(meomryBuffer.size() >= threshold){
sortAndSpill(meomoryBuffer)
}
//TODO add record to memory
}
def mergeSpills(){
while( currentPartitionId!=null){
if(record!=null){
//TODO wirte record to output file
}else{
if(has next Partition){
currentPartitionId = next Partition
}else{
currentPartitionId = null
}
}
}
}本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- React + valtio 响应式状态管理
- 清理优化,卸载高效——PP Cleaner & Uninstaller Pro for Mac
- JoyRL策略梯度
- 724. 寻找数组的中心下标
- C++之STL库简介
- 嵌入式学习第二天
- nodejs+vue+微信小程序+python+PHP基于Android自习室管理系统的设计与实现-计算机毕业设计推荐
- 巨匠纺?品鉴窗帘是一线品牌吗,产品质量怎么样
- 探索UX设计师的日常任务,赶紧看看
- Java电子招投标采购系统源码-适合于招标代理、政府采购、企业采购、等业务的企业