Redis相关的那些事(一)
发布时间:2023年12月25日
背景
目前工作所负责的工作主要是投放业务,属于读高并发场景,记录一下之前碰到的redis相关的问题。
热点大值Key&缓存击穿问题
问题表现
在某次流量峰值过程中,redis的CPU突然飙升,从监控看起来就是CPU飙升到一定程度,内存突然掉0,然后命中率掉0(实际上是主节点被打挂了,触发了主备切换)。流量和系统调用链路逻辑跟之前并无区别。
原因分析
先看一下计划发布流程和投放端读取计划配置的逻辑:
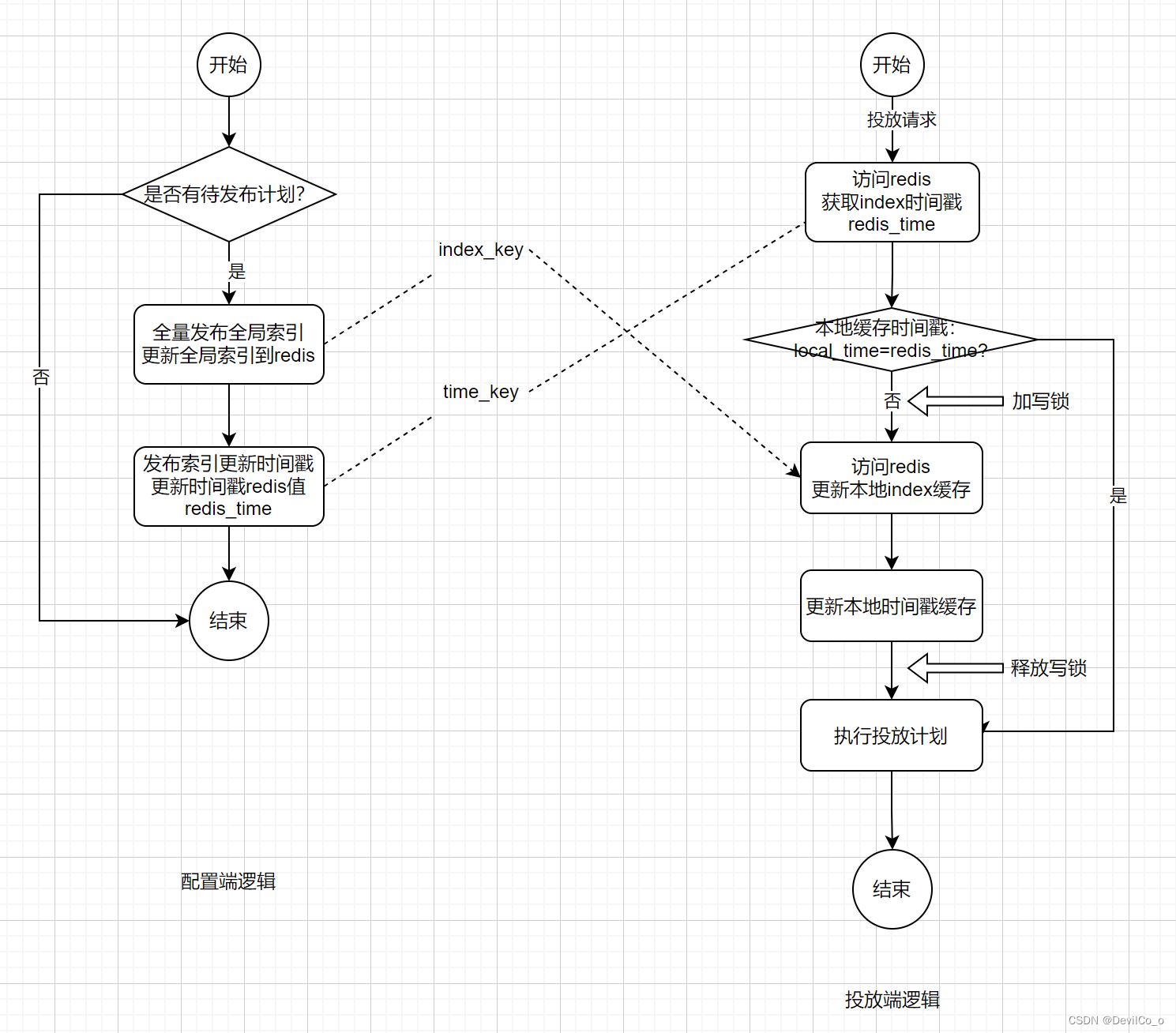
具体逻辑:
- 配置端会生成一个全局的索引index_key,来存放坑位和所关联投放计划的关系(注意这里是一个大值key);
- 配置端每次更新完全局索引后,会在redis刷新一个全局的时间戳time_key,记录索引的最后更新时间;
- 投放端请求进来后,获取redis时间戳缓存(这里是一个热点key),会判断本地索引时间戳缓存是否和redis的时间戳一致,若时间戳不一致,会刷新本地全局index缓存,刷新成功后会刷新本地时间戳缓存;
好处:
- 只要时间戳更新,投放端就会获取最新的索引版本,能保证索引发布后,所有对于所有机器来说就马上生效;
弊端
- 时间戳redis值本来就是个热点key,投放端每次请求都会打到redis;
- 全局索引会是大值key,当QPS很高的时候,每次发布新的索引之后,所有机器会同时触发刷新,若集群的机器数量很多的时候,瞬间会打到同一个redis分片
上面所说的问题就是由于在流量峰值期间,有运营发布了新计划,导致全局索引刷新,瞬间1000+qps打到同一个redis分片获取全局索引,导致分片被打崩。
解决办法:
- 最简单的解决办法就是把全局索引复制多个备份,key值加入后缀,使value分布到redis集群的每个分片中。比如复制20个备份,index_key_{random},投放端机器随机访问0-20后缀的全局索引分片,解决热点问题;
弊端:需要保持多个备份的一致性,可能会存在一致性问题; - 把全局索引根据业务划分为更小的颗粒度。比如在这个场景,可以把全局索引改为资源位-计划的索引,减少value的值大小,而且根据资源位进行索引后,value的分布也自然就打散了;
- 使用压缩工具,减少value的值。因为存放的value为json格式,json格式其实是有很大的压缩空间,使用压缩工具能够大大减少value的值;
- 增加时间戳本地缓存过期时间,使更新本地索引的请求不会同时触发,通过减少并发量解决问题。
弊端:会导致计划发布之后,投放端会有延迟更新,因为本地缓存时间的存在,所以并不会马上去校验索引是否更新。
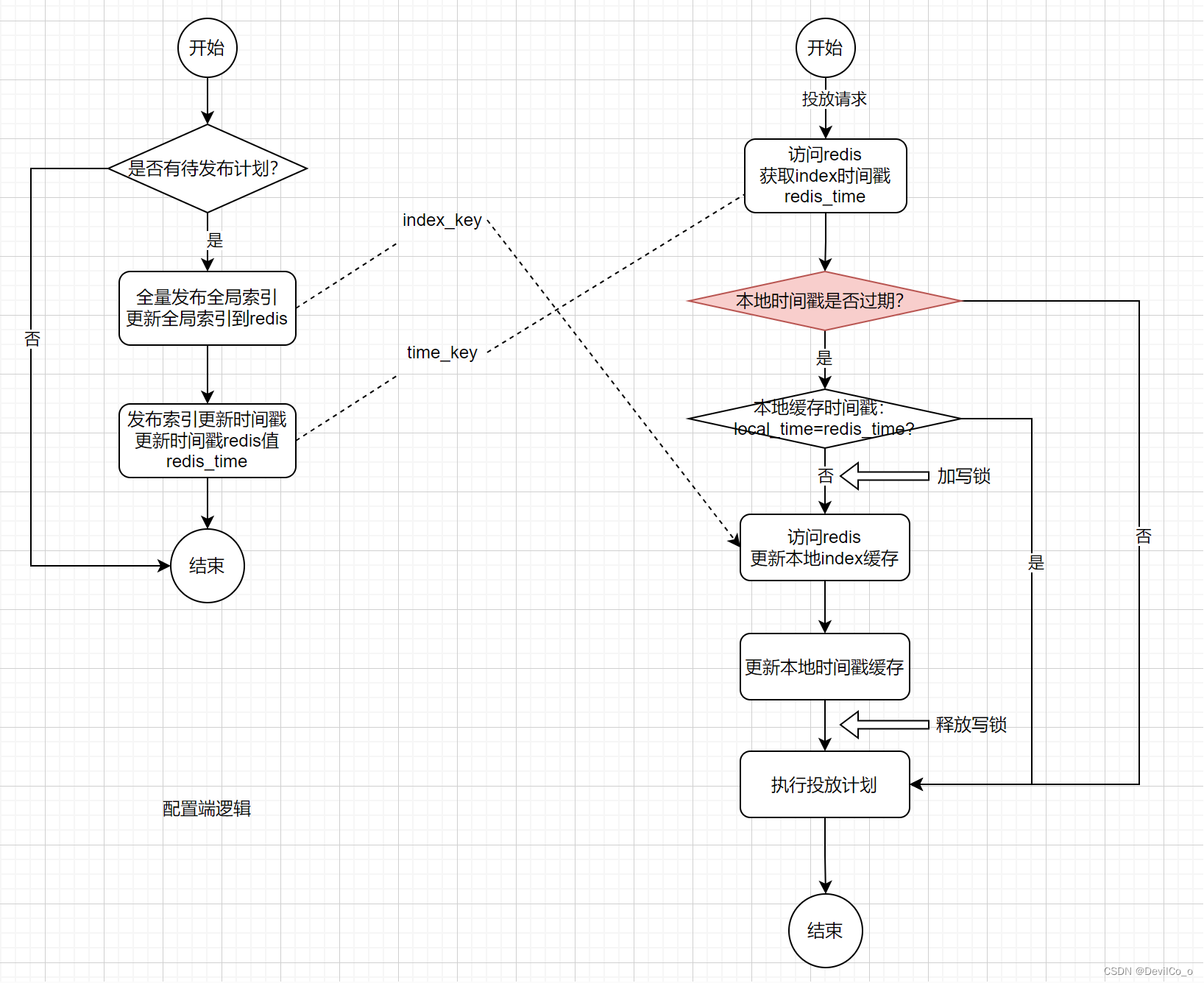
总结
总结一下,解决热点大值key基本就几个思路:
- 通过预热的方式,把热点key打散,把压力分散到整个集群;
- 通过减小value的size,压缩、修改缓存颗粒度;
- 引入缓存过期时间对峰值尖刺进行削峰,减少并发量;
文章来源:https://blog.csdn.net/weixin_42440637/article/details/134772367
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- I.MX6ULL_Linux_驱动篇(52)linux CAN驱动
- Jmeter接口测试(2024版)
- 2023年12月GESP Python五级编程题真题解析
- 随笔03 笔记整理
- Demo: elementplus中select实现触底加载数据(懒加载)
- 迅为RK3568开发板如何修改默认配置并保存
- 大语言模型系列-总述
- 芋道前端框架上线之后发现element-ui的icon图标全部乱码
- 人工智能_机器学习084_使用聚类算法_提取图片主要颜色_对图片进行聚类提取特征_对图片进行压缩---人工智能工作笔记0124
- Java基础进阶01-类加载器,反射