【项目调研】村头王大爷家女儿王大红用GPT学习了基于datavines的数据质量实践教程
基于datavines的数据质量实践教程
1,数据质量检测的维度
数据完整性(Completeness):这涉及到数据是否完整无缺,包括数据的必要字段是否齐全,以及数据实例是否没有缺失。
完整性可以通过统计缺失数据的比例,和比对数据以及底稿系统数据的一致性来进行评估。
数据一致性(Consistency): 数据的一致性是指在不同应用系统和数据源中数据具有相同的含义和取值范围。
评价一致性需要考察数据接口的定义、数据标准的制定和数据转换处理的准确性。
数据及时性(Timeliness):数据及时性是指数据在产生或更新后能够及时使用。评价及时性需要考虑数据生成、数据传输和数据处理的速度和时效性。【数据的生产时间和到达时间】
数据可用性(Accessibility):数据可用性是指数据在需要时可以被获取和使用的程度。评价可用性需要考虑数据的存储和检索方式、数据的可访问性和数据的安全性。
数据准确性(Accuracy):准确性涉及数据与真实情况的一致性和精确性。评价准确性需要考虑数据的来源、采集过程、处理过程和存储过程。
数据唯一性(Uniqueness):唯一性用于度量哪些数据是重复数据或者数据的哪些属性是重复的。2
数据关联性(Integration):关联性用于度量哪些关联的数据缺失或者未建立索引。
数据规范性(Conformity):规范性用于度量哪些数据未按统一格式存储。
2,datavines的作用和安装
2.1 作用
datavines 主要用于数据质量的管理。
附加的功能还有告警、元数据查看、数据概览。
2.2 安装
2.2.1 从源码编译安装–环境依赖
在安装Datavines之前请确保你的服务器上已经安装下面软件:
Git,确保 git clone的顺利执行
JDK,确保 jdk = 8
Maven, 确保项目的顺利打包(当然你也可以在本地打包以后上传至服务器)
2.2.2 下载代码
git clone https://github.com/datavane/datavines.git
cd datavines
2.2.3 数据库准备
Datavines 的元数据是存储在关系型数据库中,目前支持 MySQL 和 PostgreSQL ,默认使用 PostgreSQL ,下面以MySQL为例说明安装步骤:
创建数据库 datavines
执行 script/sql/datavines-mysql.sql 脚本进行数据库的初始化
下面的项目构建也是以MySQL为例
2.2.4 项目构建
打包并解压
mvn clean package -Prelease
cd datavines-dist/target
tar -zxvf datavines-1.0.0-SNAPSHOT-bin.tar.gz
2.2.5 配置
解压完成以后进入目录
cd datavines-1.0.0-SNAPSHOT-bin
修改配置信息
cd conf
vi application.yaml
主要是修改数据库信息
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/datavines?useUnicode=true&characterEncoding=UTF-8
username: root
password: 123456
如果你是使用Spark做为执行引擎,并且是提交到Yarn上面去执行的,那么需要在common.properties中配置yarn相关的信息
standalone 模式
yarn.mode=standalone
yarn.application.status.address=http://%s:%s/ws/v1/cluster/apps/%s #第一个%s需要被替换成yarn的ip地址
yarn.resource.manager.http.address.port=8088
ha 模式
yarn.mode=ha
yarn.application.status.address=http://%s:%s/ws/v1/cluster/apps/%s
yarn.resource.manager.http.address.port=8088
yarn.resource.manager.ha.ids=192.168.0.1,192.168.0.2
2.3 启动服务
cd bin
sh datavines-daemon.sh start mysql
查看日志,如果日志里面没有报错信息,并且能看到[INFO] 2022-04-10 12:29:05.447 io.datavines.server.DatavinesServer:[61] - Started DatavinesServer in 3.97 seconds (JVM running for 4.69)的时候,证明服务已经成功启动
2.4 访问服务
访问前端页面
在浏览器输入:localhost:5600,就会跳转至登录界面,输入账号密码 admin/123456
3,datavines 主要功能模块介绍
平台主要分为: 数据源、告警、错误数据、用户、标签、全局参数、数据质量校验、定时任务等模块。
支持的数据源有:
MySQL
Doris
StarRocks
Hive
PostgreSQL
ClickHouse
Trino
Presto
Impala
Databend
针对每个数据源,有元数据管理,定时采集数据库表的元数据信息。
每个数据源点击下钻之后, 就是平台的主要功能, 数据质量的检测。
数据检测支持单表检测和两表比对检测。
单表检测的支持项如下:
自定义聚合SQL
非空检查
空值检查
平均值检查
平均长度检查
无值检查
Distinct检查
重复值检查
枚举值检查
枚举值[不在]检查
字段长度检查
正则表达式[不匹配]检查
正则表达式[匹配]检查
最大值检查
最大长度检查
最小值检查
最小长度检查
标准差检查
总值检查
唯一性检查
值范围检查
方差检查
及时性检查
表行数检查
支持的多表检测有如下:
两表值比对
跨表准确性
同时根据检测规模的大小,可以使用jdbc 引擎(也叫做本地引擎),或者spark 引擎进行数据质量检测。
4,基于datavines的数据质量检测实践
关于数据质量检测说明:
支持的期望值类型有:
无
固定值
日均值
周均值
月均值
最近7天均值
最近30天均值
表总行数
目标表总行数
支持的计算公式有:
实际值
|实际值-期望值|
实际值-期望值
|实际值-期望值|/期望值*100%
实际值/期望值*100%
比对公式 指的是在进行结果判断时所使用的计算公式,一般配合比较符(comparator)和阈值(threshold)一起使用,完整的判断公式为 [比对公式][比较符] [阈值]
检查结果的判断公式为:[比对公式][比较符] [阈值],如果结果为真,就是成功,否则为失败
举个例子:[实际值-期望值] [>] [0], 实际值为10,期望值为9,代入公式以后就是 [10-9][>][0],这个结果为真,那么检查结果就是成功。
比较符有这些: =, !=, >, >=, <, <=
4.1 数据完整性(Completeness)
对于一个订单表,完整性可以通过统计缺失数据的比例来评估。
例如,通过计算某个订单表中缺失订单日期字段的比例,来判断数据的完整性。
CREATE TABLE orders (
order_id INT PRIMARY KEY,
order_date DATE,
customer_id INT,
total_amount DECIMAL(10, 2)
);
INSERT INTO orders (order_id, order_date, customer_id, total_amount)
VALUES
(1, '2022-01-01', 1001, 50.00),
(2, '2022-01-02', 1002, 75.00),
(3, NULL, 1003, 100.00);
在datavines配置针对order_date的数据完整性检查, 如下表示, order_date 非空占比的行数,占总行数的65%以上。

4.2 数据一致性(Consistency)
假设有一个客户表和一个订单表,数据一致性可以通过比对客户表和订单表中的客户ID字段来评估。
例如,检查订单表中的每个订单的客户ID是否在客户表中存在,以确保数据的一致性。
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(50),
email VARCHAR(100)
);
CREATE TABLE orders (
order_id INT PRIMARY KEY,
order_date DATE,
customer_id INT,
total_amount DECIMAL(10, 2),
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
INSERT INTO customers (customer_id, customer_name, email)
VALUES
(1001, 'John Doe', 'johndoe@example.com'),
(1002, 'Jane Smith', 'janesmith@example.com');
INSERT INTO orders (order_id, order_date, customer_id, total_amount)
VALUES
(1, '2022-01-01', 1001, 50.00),
(2, '2022-01-02', 1002, 75.00),
(3, 2022-01-03, 1003, 100.00);
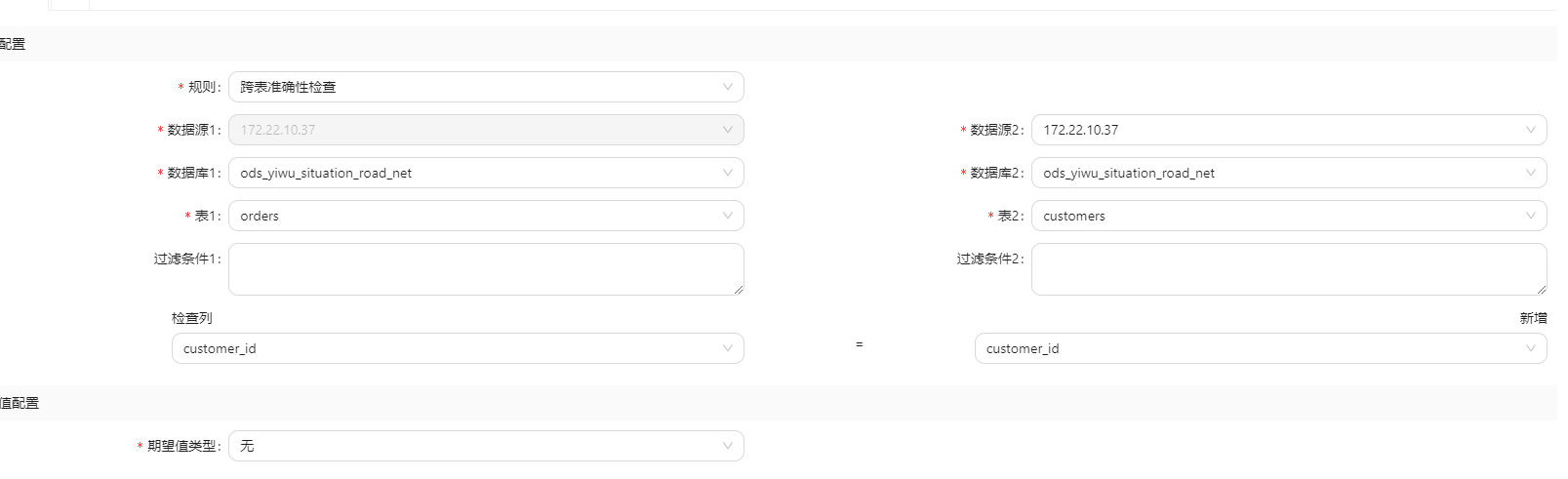
在datavines 中配置任务, 如下表示,在表orders 中存在customer_id 但是在customer 表中不存在customer_id 的总行数,应该为0, 因为ordres 中的所有id都必须来源于customer表
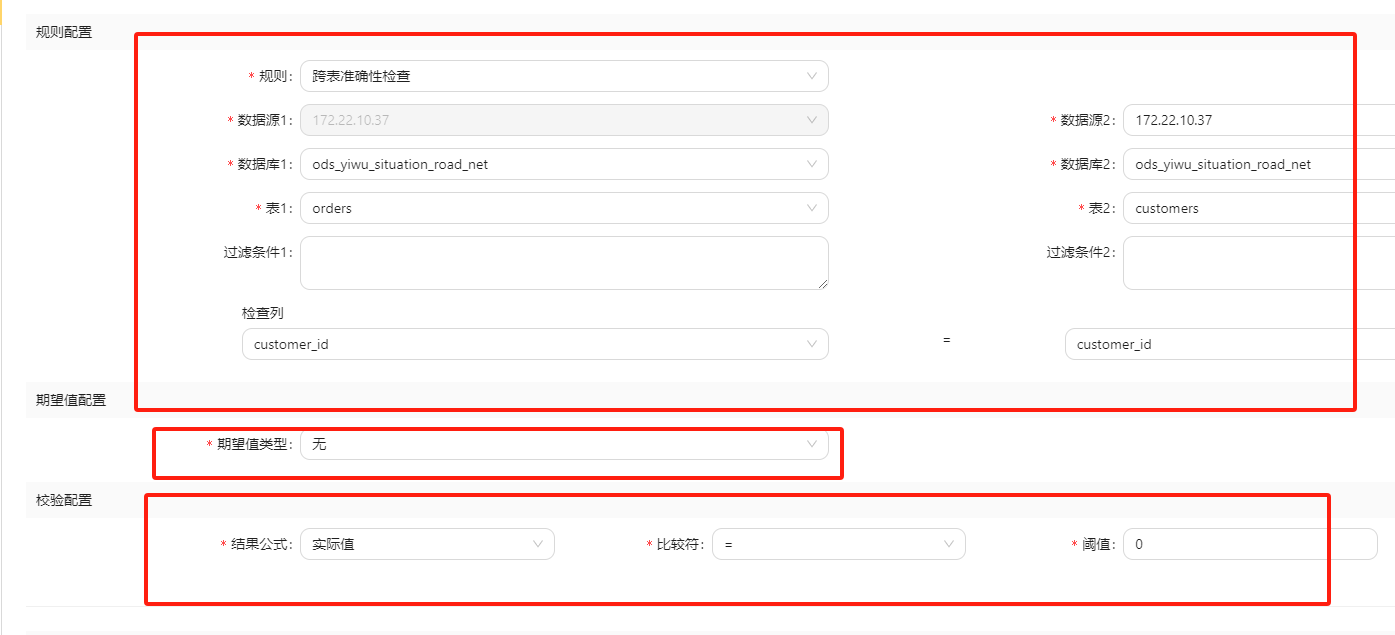
如上的执行结果将会失败, 因为没有id为1003 的customer
4.3 数据及时性(Timeliness)
考虑一个日志表,数据及时性可以通过记录日志的时间戳和当前时间进行比较来评估。
例如,检查日志表中最近一次日志的时间戳与当前时间的差距,以判断数据的及时性。
CREATE TABLE logs (
log_id INT PRIMARY KEY,
log_message VARCHAR(200),
log_timestamp TIMESTAMP
);
INSERT INTO logs (log_id, log_message, log_timestamp)
VALUES
(1, 'Error occurred', '2022-01-01 10:00:00'),
(2, 'Warning: low disk', '2022-01-01 11:30:00'),
(3, 'Information updated', '2022-01-01 12:45:00');
如下配饰数据的及时性,查看数据时间,是否落在某个规定的时间区间内。结果为false, 2022-01-01 10:00:00的数据不再区间内。
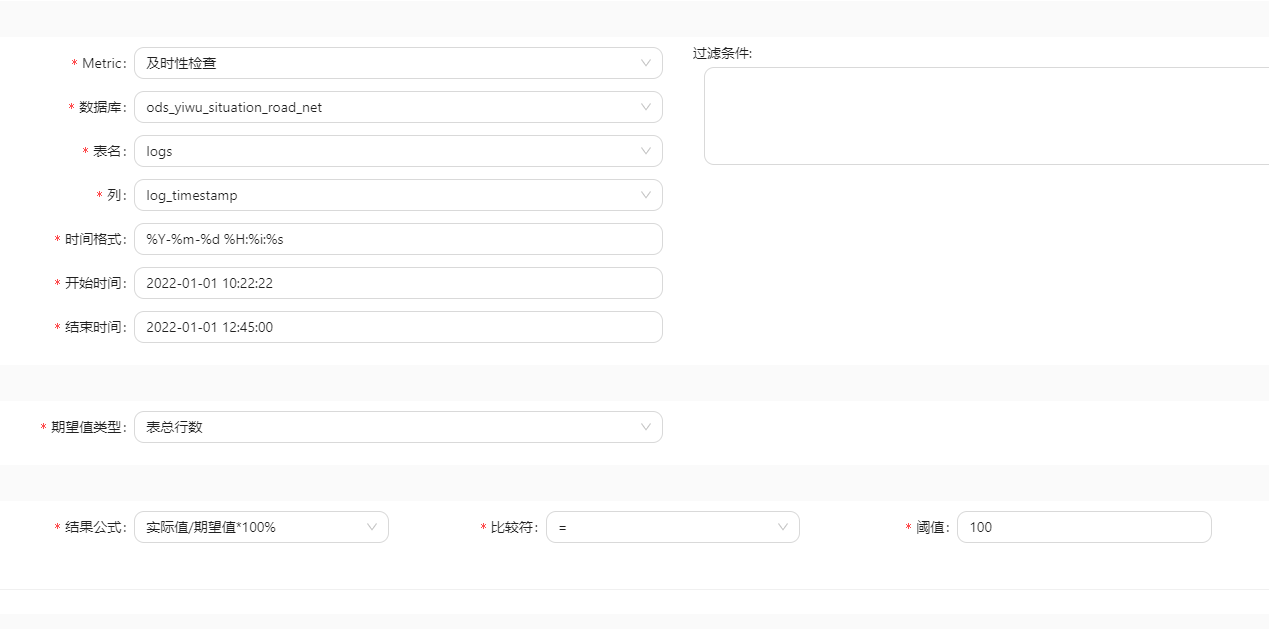
4.4 数据可用性(Accessibility)
对于一个用户表,数据可用性可以通过检查数据的存储方式和访问权限来评估。【数据的准确性、一致性、及时性、唯一性、完整性、关联性和规范性达到标准,并且对特定的人,给与特定的访问权限】
例如,确保用户表的存储方式符合安全性要求,并且只有授权用户可以访问数据。
CREATE TABLE users (
user_id INT PRIMARY KEY,
username VARCHAR(50),
password VARCHAR(100)
);
INSERT INTO users (user_id, username, password)
VALUES
(1, 'john.doe', 'hashed_password'),
(2, 'jane.smith', 'hashed_password');
4.5 数据准确性(Accuracy)
考虑一个产品价格表,数据准确性可以通过比对产品价格表中的价格与实际产品价格来评估。
例如,从外部数据源获取实际产品价格,并与产品价格表中的价格进行比较,以判断数据的准确性。
CREATE TABLE products (
product_id INT PRIMARY KEY,
product_name VARCHAR(100),
actual_price DECIMAL(10, 2)
);
INSERT INTO products (product_id, product_name, actual_price)
VALUES
(1, 'Product A', 20.00),
(2, 'Product B', 35.00);
如下,所有的数据,价格区间必须落在25到50之间,所以检测会失败。
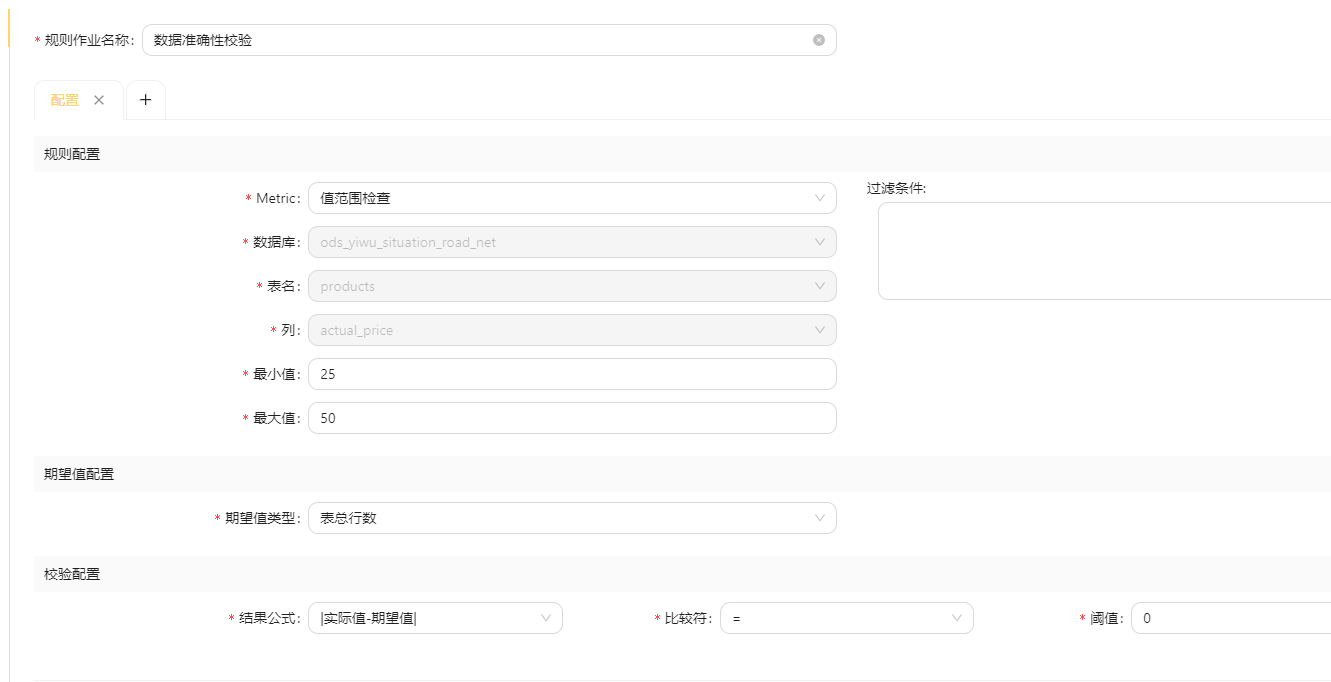

4.6 数据唯一性(Uniqueness)
对于一个学生表,数据唯一性可以通过检查学生表中的学生ID字段是否具有唯一性来评估。
例如,确保学生表中每个学生的学生ID都是唯一的,没有重复值。【此处只是示例,一般检查身份证是否唯一,手机号是否唯一, 当然,如果学生id不是主键,也可以检查学生id是否唯一】
CREATE TABLE students (
student_id INT PRIMARY KEY,
student_name VARCHAR(50),
email VARCHAR(100)
);
INSERT INTO students (student_id, student_name, email)
VALUES
(1001, 'John Doe', 'johndoe@example.com'),
(1002, 'Jane Smith', 'janesmith@example.com');
如下检查email 字段是否唯一, 这项检查通过,因为给出的数据,email 是唯一的。
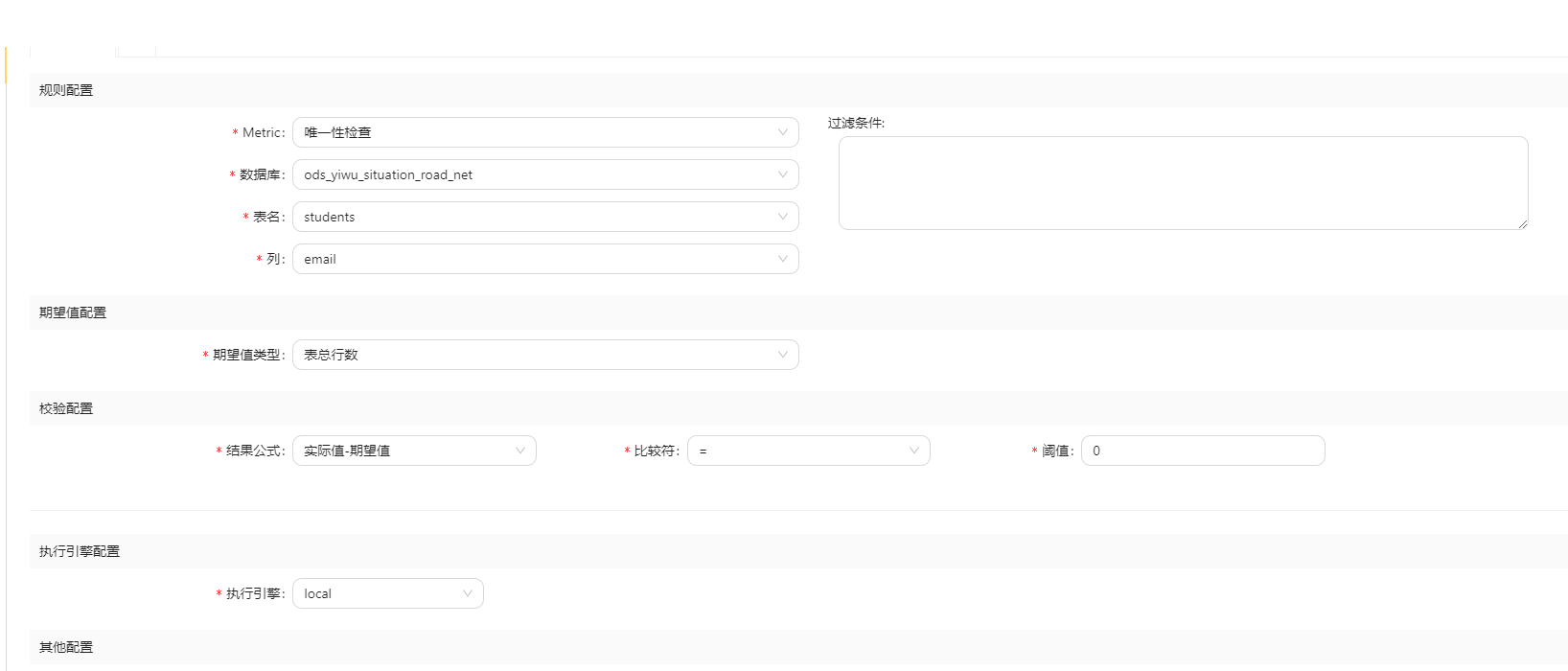
4.7 数据关联性(Integration)
对于多个数据表之间的关联,关联性可以通过检查关联字段是否缺失或者建立索引来评估。
例如,确保订单表和用户表之间的关联字段都存在,并且建立了索引以提高查询效率。
CREATE TABLE users (
user_id INT PRIMARY KEY,
username VARCHAR(50),
email VARCHAR(100)
);
CREATE TABLE orders (
order_id INT PRIMARY KEY,
order_date DATE, customer_id INT,
total_amount DECIMAL(10, 2),
FOREIGN KEY (customer_id) REFERENCES users(user_id)
);
INSERT INTO users (user_id, username, email)
VALUES
(1, 'john.doe', 'johndoe@example.com'),
(2, 'jane.smith', 'janesmith@example.com');
INSERT INTO orders (order_id, order_date, customer_id, total_amount)
VALUES
(1, '2022-01-01', 1, 50.00),
(2, '2022-01-02', 2, 75.00),
(3, '2022-01-03', 3, 100.00);
如下配置数据关联性, 查看orders表的所有customer_id 是否都是来源于表格customers。
配置的含义可以理解为,期望所有的orders表的customer_id 都是来源于customers
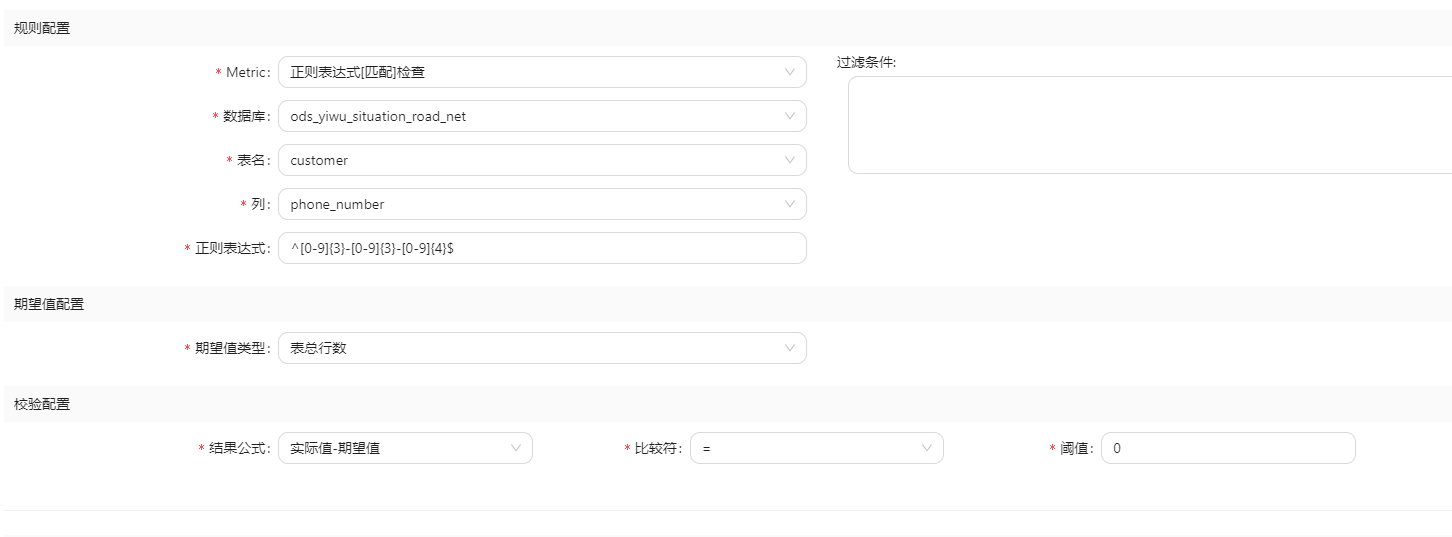
4.8 数据规范性(Conformity)
对于一个员工表,规范性可以通过检查员工表中的数据是否按照统一的格式存储来评估。
例如,确保员工表中的电话号码都遵循统一的格式,如使用统一的国际区号格式。
CREATE TABLE customer (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(50),
phone_number VARCHAR(20)
);
INSERT INTO customer (customer_id, customer_name, phone_number)
VALUES
(1, 'John Doe', '123-456-7890'),
(2, 'Jane Smith', '987-654-3210'),
(3, 'Mike Johnson', '555-123-4567');
如下使用正则匹配,检测数据是否符合规范。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 某金属加工公司的核心人才激励体系搭建项目纪实
- GPT编程(1)八分类图像数据集转换为二分类
- 【RocketMQ每日一问】RocketMQ如何保证消息不丢失?
- ArduPilot之开源代码电压/电流校准
- JS中的File(四):文件流Streams API使用详解
- VUE--组件的生命周期及其基本应用
- 2024年安全员-B证证模拟考试题库及安全员-B证理论考试试题
- 2.docker client
- SpringBoot-基本原理(配置文件的优先级、Bean管理、自动配置原理)
- Python入门-函数