书生·浦语大模型--第四节课笔记--XTuner大模型单卡低成本微调
发布时间:2024年01月24日

Finetune简介
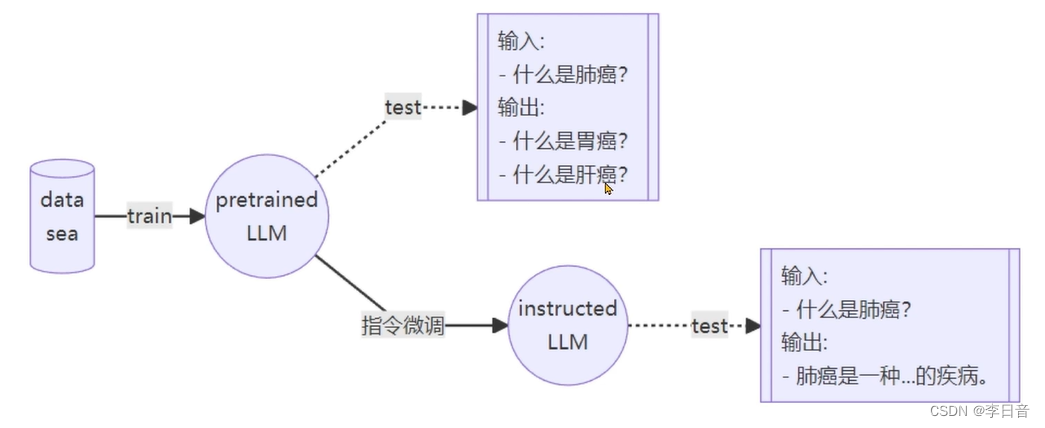
增量预训练和指令跟随

通过指令微调获得instructed LLM
指令跟随微调
一问一答的方式进行
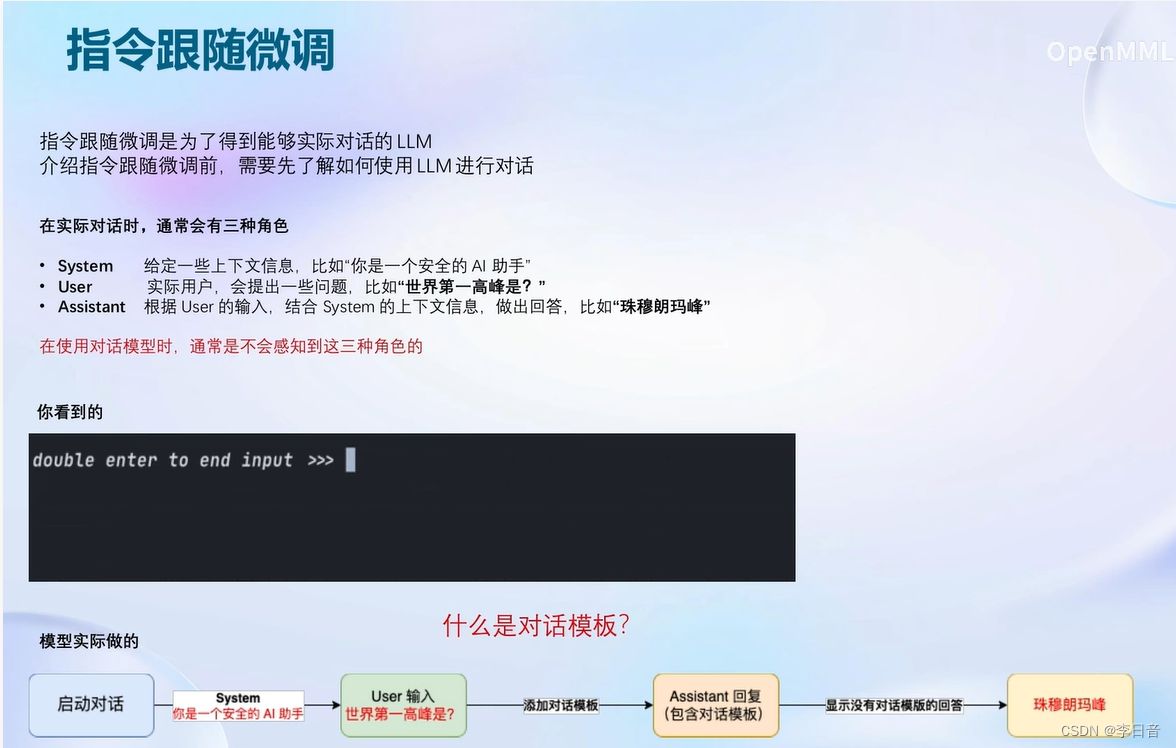
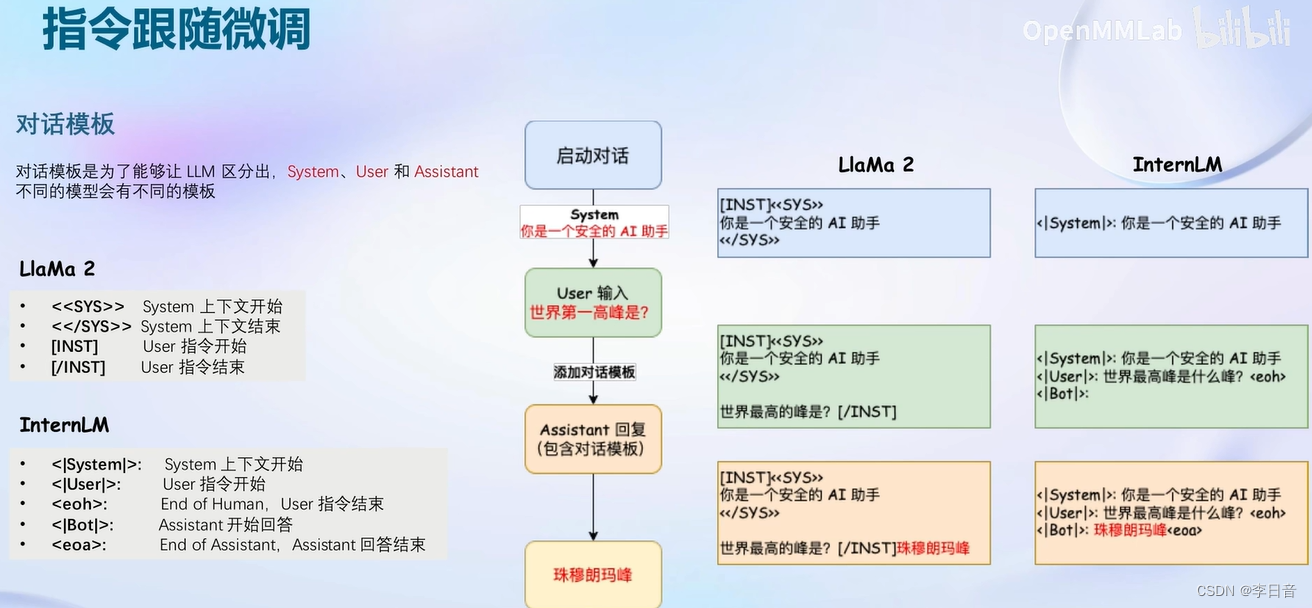
对话模板
计算损失

增量预训练微调
不需要问题只需要回答,都是陈述句。计算损失时和指令微调一样

LoRA QLoRA
不需要太大的显存开销。增加旁路分支Adapter。

比较:
- 全参数微调:整个模型加载到显存中,所有模型的参数优化器也要加载到显存中
- LoRA微调:模型也需要加载到显存中,但是参数优化器只需要LoRA部分
- QLoRA微调:加载模型时就4bit量化加载,参数优化器还可以在CPU和GPU之间调度,显存满了可以在内存里跑

XTuner介绍

快速上手


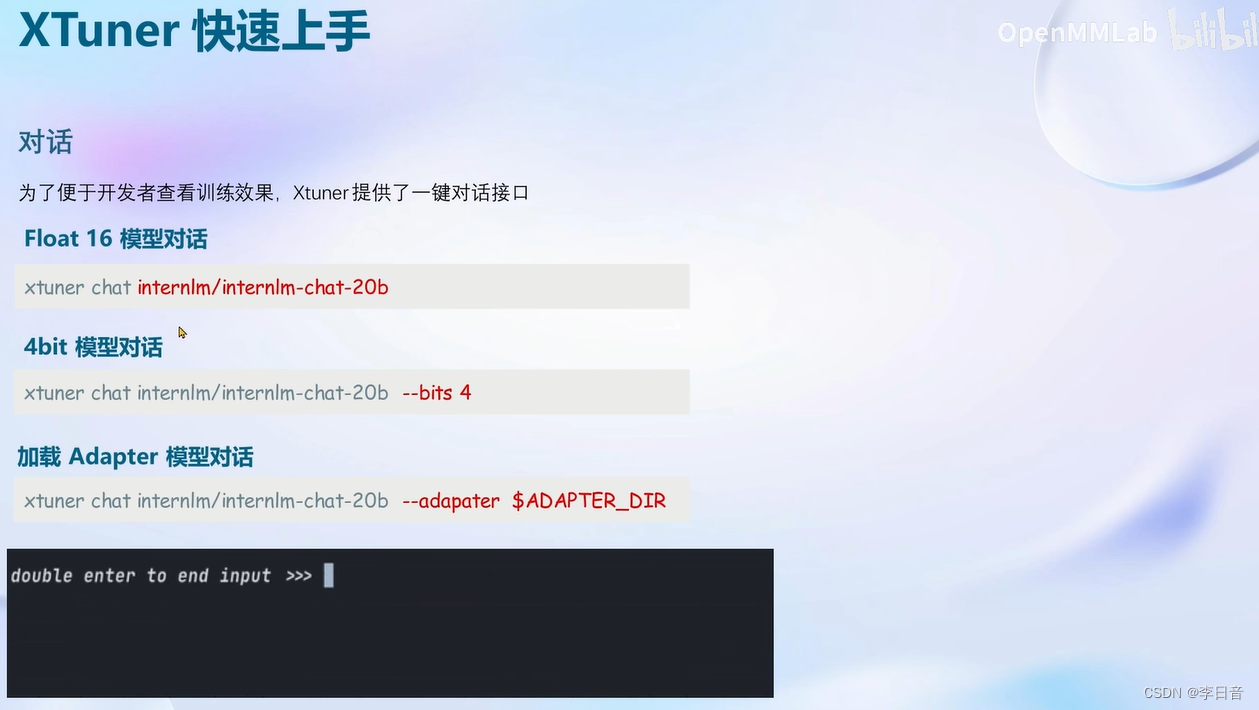
8GB显卡玩转LLM
动手实战环节
文章来源:https://blog.csdn.net/lalala12ll/article/details/135738066
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java 新手如何使用Spring MVC 中的双向数据绑定?
- 2023年中国产业格局巨变:电子行业崛起、新能源汽车崭露头角,500强企业大揭秘!
- 【随想】每日两题Day.20(实则一题)
- 【nacos】nacos配置中心自制工具类 获取配置dataid级全文 不使用自带注入和refresh 观察者+监听器实现
- Github项目推荐-vocal-separate
- 创建局域网git裸仓库
- 仰望星空,也要鲜花与掌声
- gem5学习(15):Memory system
- Vue独立组件开发-动态组件
- 【易经】-- 风水基础