【编译原理--复习】
知识点整理
第一章
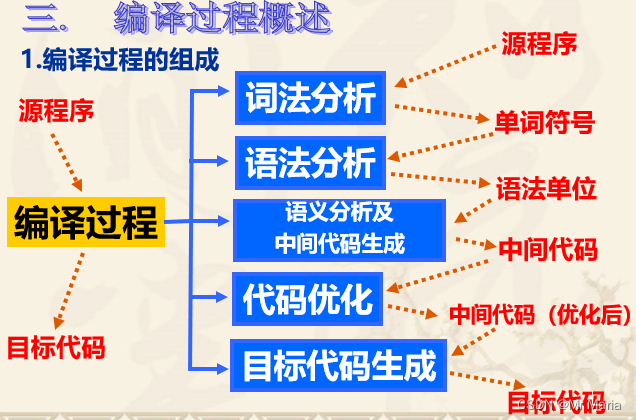
同时伴有表格管理、出错处理
1、词法分析
任务:对构成源程序的字符串进行扫描和分解,识别出单词(如标识符等)符号
输入:源程序
输出:单词符号序列
2、语法分析
任务:根据语言的语法规则对单词符号串(符号序列)进行语法分析,识别出各类语法短语(可表示成语法树的语法单位),判断输入串在语法上是否正确
输入:单词序列
输出:语法分析后的单词序列
3、语义分析
任务:按语义规则对语法分析器归约出的语法单位进行语义分析,审查有无语义错误,为代码生成阶段收集类型信息,并进行类型审查和违背语言规范的报错处理
4、中间代码生成
任务:将语义分析得到的源程序变成一种结构简单,含义明确,容易生成,容易译成目标代码的内在代码形式
常用的中间代码形式是四元式(算符,运算对象1,运算对象2,结果)
5、代码优化
任务:对中间代码或目标代码进行变换改造等优化处理,使生成的代码更高效
6、目标代码生成
任务:将语义分析结果或中间代码生成特定机器上的绝对或可重定位的指令代码或汇编指令代码
- 编译程序必须有词法分析、语法分析、语义分析、代码生成,中间代码生成和代码优化不要求有。
- 任何一个编译程序都必须有目标代码生成部分。
- 编译程序绝大多数时间花在(表格管理)。
- LEX是用于词法分析的工具,YACC是用于语法分析的工具。
- 多遍扫描第一遍扫描的是源程序,其它各遍扫描的是前一阶段的加工结果,即某种形式的中间代码。
- 代码优化不能提高编译程序自身的运行速度,但可使目标代码质量高。
- 无符号常数的识别和拼数工作通常在(词法分析)阶段完成。
- 编译程序是对(高级语言的翻译)。
- 解释程序和编译程序的区别在于(是否生成目标代码)
- 编译程序的工作过程一般可包括词法分析、语法分析、语义分析、中间代码生成、代码优化、目标代码生成基本阶段,同时还伴有表格管理和出错处理。
- 一遍扫描的编译程序的优点是(编译速度快)。
- 将编译程序分成若干个“遍”是为了(使程序的结构更加清晰)。
- 无符号常数的识别和拼数工作通常在(词法分析)阶段完成
- “运算符与运算对象类型不匹配”属于(语义错误)。
- 编译程序是一种(系统)软件。
- 绝大多数程序设计语言是上下文有关语言。
- 语法树描述的是句型。
第二章
1、语言概述
1、语言是由句子组成的集合,是由一组符号构成的集合
2、程序设计语言——所有该语言的程序的全体
语法——表示构成语言句子的各个记号之间的组合规律
语义——表示各个记号的特定含义。(各个记号和记号所表示的对象之间的关系)
语用——表示在各个记号所出现的行为中,它们的来源、使用和影响
文法是一些规则的有限集合,它是以有穷规则集来刻划无穷句子集合的工具
BNF是一种广泛采用的( 描述文法)工具。
2、文法及产生式
产生式——设VN ,VT 分别是非空有限的非终结符号集和终结符集。V = VN ∪ VT ,VN ∩ VT = ? 。所谓产生式是一个序偶对(α ,β),其中 α ∈ V+,β ∈ V*,通常表示为:α → β 或 α ::= β,产生式也叫规则、重写规则、生成式。
文法 G 是一个四元组,G = (VN,VT,P,S)。其中,VN,VT 分别是非空有限的非终结符集和终结符集,且 VN ∩ VT = ?;P为产生式集;S ∈ VN 为文法的开始符号(或识别符),它是一个非终结符,至少要在一条规则中作为左部出现。
3、文法分类
- 0型(短语文法,图灵机):
产生式形如: α → β
其中:α ∈ ( V T ∪ V N ) ?且至少含有一个非终结符;β ∈ ( V T ∪ V N ) ?
α、β都是由终结符和非终结符组成的任意串,但α含有一个非终结符(全是终结符就没法定义了)
2型文法(上下文无关文法是0型文法的一个特例)
- 1型(上下文有关文法,线性界限自动机):
产生式形如: α → β
其中:α ∈ ( V T ∪ V N ) ? α∈ (V_T∪V_N)^*α∈(V T∪V N) ?
且至少含有一个非终结符;β ∈ ( V T ∪ V S ) ?
∣ α ∣ ≤ ∣ β ∣ ,仅 S → ε 例外。
左边一定比右边短
- 2型(上下文无关文法,非确定下推自动机):
产生式形如: A → β A → βA→β
其中:A ∈ V N ; β ∈ ( V T ∪ V N ) ? A∈ V_N;β∈ (V_T ∪ V_N)^*A∈VN;β∈(V T∪V N) ?
左边是一个非终结符,右边是终结符非终结符组成的任意串。
二义性文法是上下文无关文法。
- 3型(正规文法,有限自动机):
右线性文法
产生式形如: A → α B 或 A → α A → αB 或 A → αA→αB或A→α
其中: α ∈ V T ? ; A , B ∈ V N α∈ V_T^*;A,B∈V_Nα∈V T?;A,B∈V N
右边要么没有非终结符
如果有非终结符的话,只能出现在最右边。
左线性文法
产生式形如: A → B α 或 A → α A → Bα 或 A → αA→Bα或A→α
其中: α ∈ V T ? ; A , B ∈ V N α∈ V_T^*;A,B∈V_Nα∈V T? ;A,B∈V N
右边要么没有非终结符
非终结符要出现,只能在定义式的最左边。


4、上下文无关文法与语法树
语法树也称推导树,给定文法G=(VN,VT,P,S),对于文法 G 的任意一个句型都存在一个相应的语法树,它满足:
① 树中每一个结点都有一个标记,此标记是 V = VN ∪ VT 中的一个符号
② 根的标记是S
③ 若树的一结点 A 至少有一个子孙,则 A ∈ VN
④ 如结点 A 的子孙结点从左到右次序为 B1,B2 …… Bn,则必有产生式 A → B1B2…Bn
? 同一语法树可以表示对同一句型不同的推导过程
? 如果每一步 α → β 中,都是对 α 中最左(右)非终结符进行替换,则称之为最左(右)推导。最右推导称为规范推导,由规范推导所得的句型称为规范句型
? 同一语法树最多对应唯一的最左(右)推导
? 一个句型有可能对应着不同的语法树
? 如果一个文法存在某个句子对应着两棵不同的语法树,则称此文法是二义的
? 不存在算法判断一个 2 型文法是否是二义的
? 实际应用中,常找出一组无二义性的充分条件来构造无二义性文法
5、句型的分析
? 句型的分析就是识别一个符号串是否为某文法的一个句型
? 分析算法分为两大类:自顶向下分析和自底向上分析
自顶向下分析:由根向下逐步建立语法树,是一个逐步推导的过程
自底向上分析:自底向上构造语法树,是一个逐步规约的过程
| 名称 | 概念 |
|---|---|
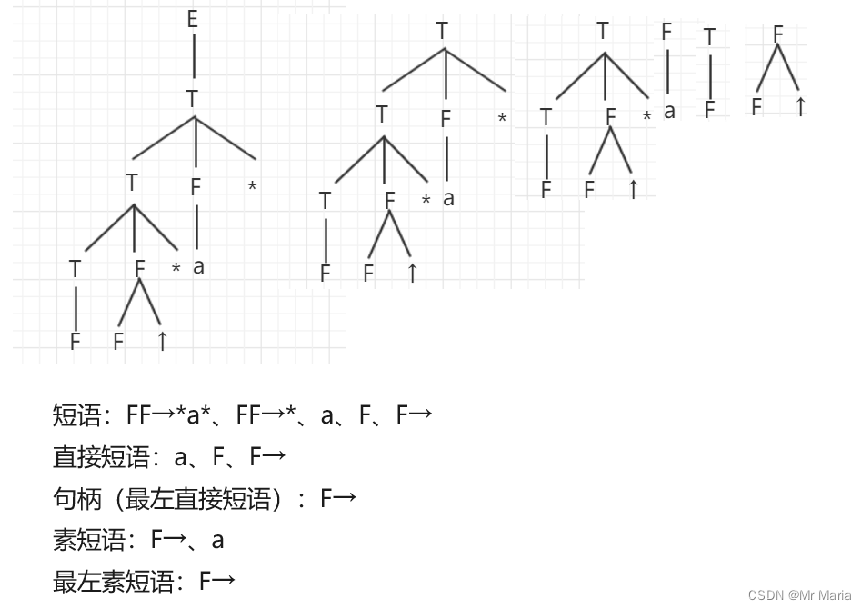
| 短语 | 在语法树中表示所有分支结点对应子树,短语即子树叶子对应的符号 |
| 直接短语 | 在语法树中表示为该短语只有上下相邻父子两代 |
| 句柄 | 句柄表示最左直接短语 |
| 素短语 | 是指一个短语至少包含一个终结符,并且除它自身之外不再包含其他素短语 |
| 最左素短语 | 最左素短语就是句型最左边的素短语,是算符优先分析法的规约对象。语法树: 通过语法树分析时,要注意先判断是否为素短语,再找相对最左端的素短语。 |
例题1:求短语,直接短语,句柄
给定句型:
FF↑a
给定文法:
G[T]:
T → T*F|F
F → F↑P|P
P → (T)|i
解析:
推导步骤为:
T ? TF*
? TFF
? TF↑*\F*
? TF↑a
画出语法树为:
第三章
1、词法分析程序的设计
1、词法分析程序的输出

2、词法分析程序中如何识别单词

2、单词的形式化描述工具

1、正规文法
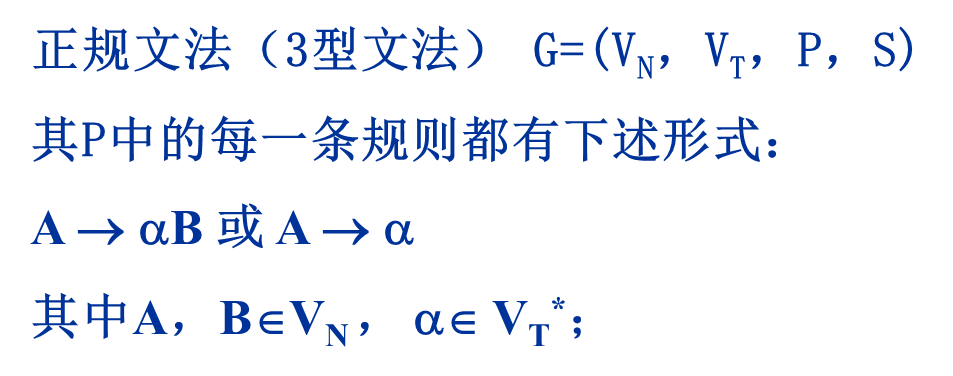
2、正规式

对给定的字母表∑ ∑∑
1)ε εε和Ф ФФ都是∑ ∑∑上的正规式,它们所表示的正规集为{ε εε}和Ф ФФ;
2) 任何a ∈ ∑ a∈ ∑a∈∑,a是∑ ∑∑上的正规式,它所表示的正规集为{a} ;
3) 假定e1和e2都是∑ ∑∑上的正规式,它们所表示的正规集为L(e1)和L(e2),则
- i) (e1|e2)为正规式,它所表示的正规集为L(e1)∪L(e2),(两个正规集的并还是正规集)
- ii) (e1.e2)为正规式,它所表示的正规集为L(e1)L(e2),(两个正规集的连接还是正规集)
- iii) ( e 1 ) ? (e1)^(e1) ?为正规式,它所表示的正规集为( L ( e 1 ) ) ? (L(e1))^(L(e1)) ?,(一个正规集的闭包还是正规集)
仅由有限次使用上述三步骤而定义的表达式才是∑ 上的正规式,仅由这些正规式表示的字集才是∑ 上的正规集



3、正规文法和正规式的等价性


有穷自动机

1、确定有限自动机(DFA)

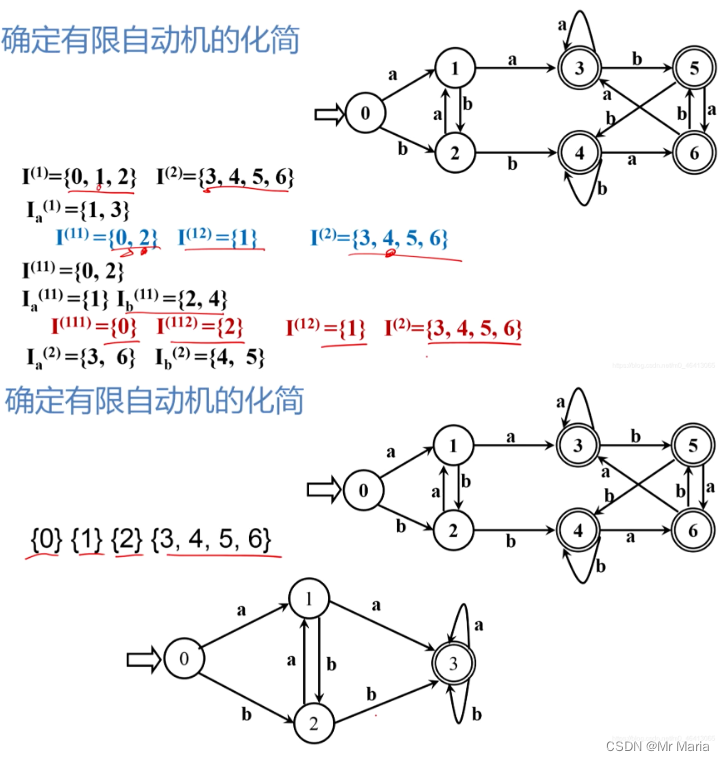
2、不确定的有穷自动机(NFA)

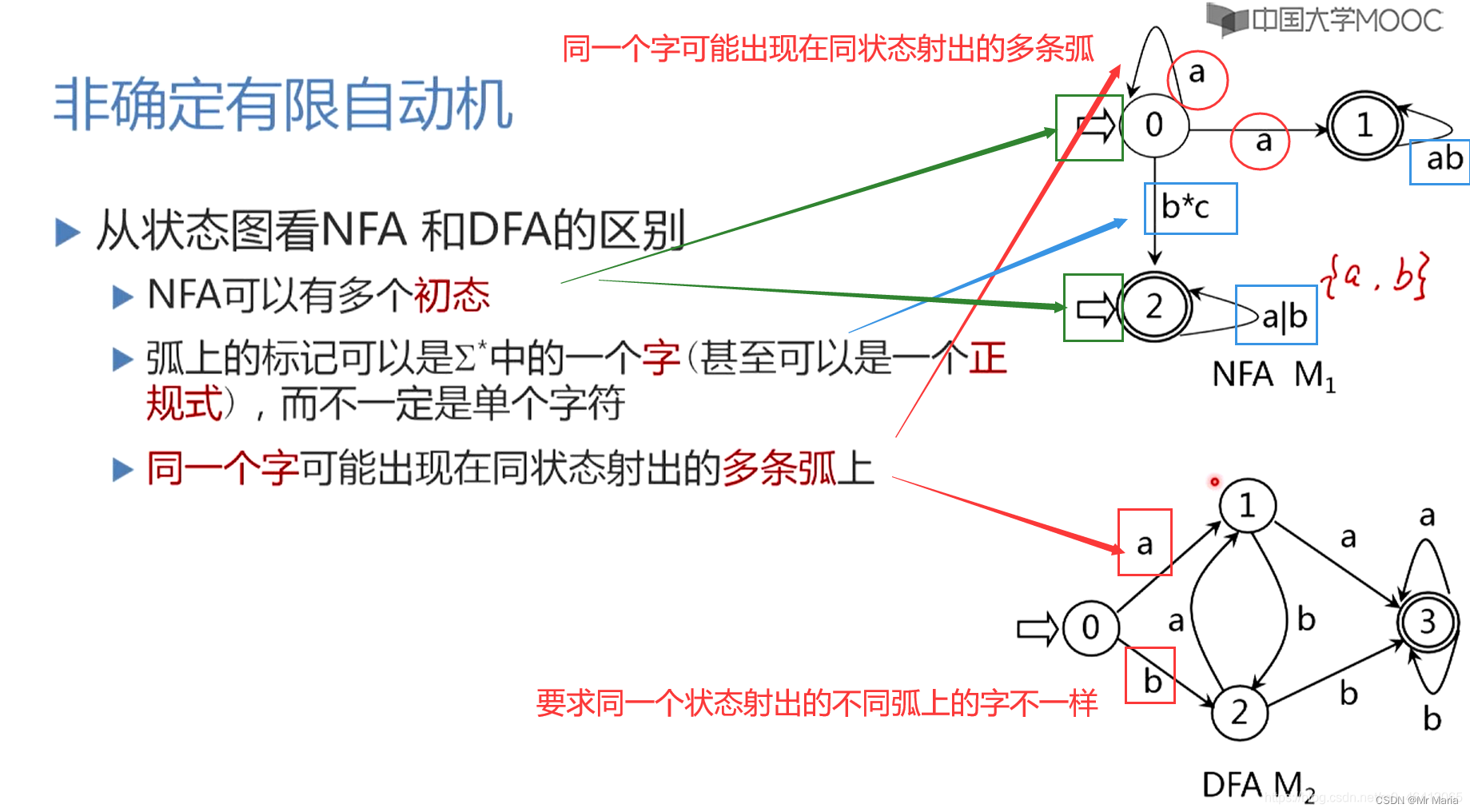
3、NFA转换为等价的DFA

子集算法
步骤:
1、确定列数(有几种弧就有几列),找到起始状态的所有
然后列表,直到出现重复的就停止。
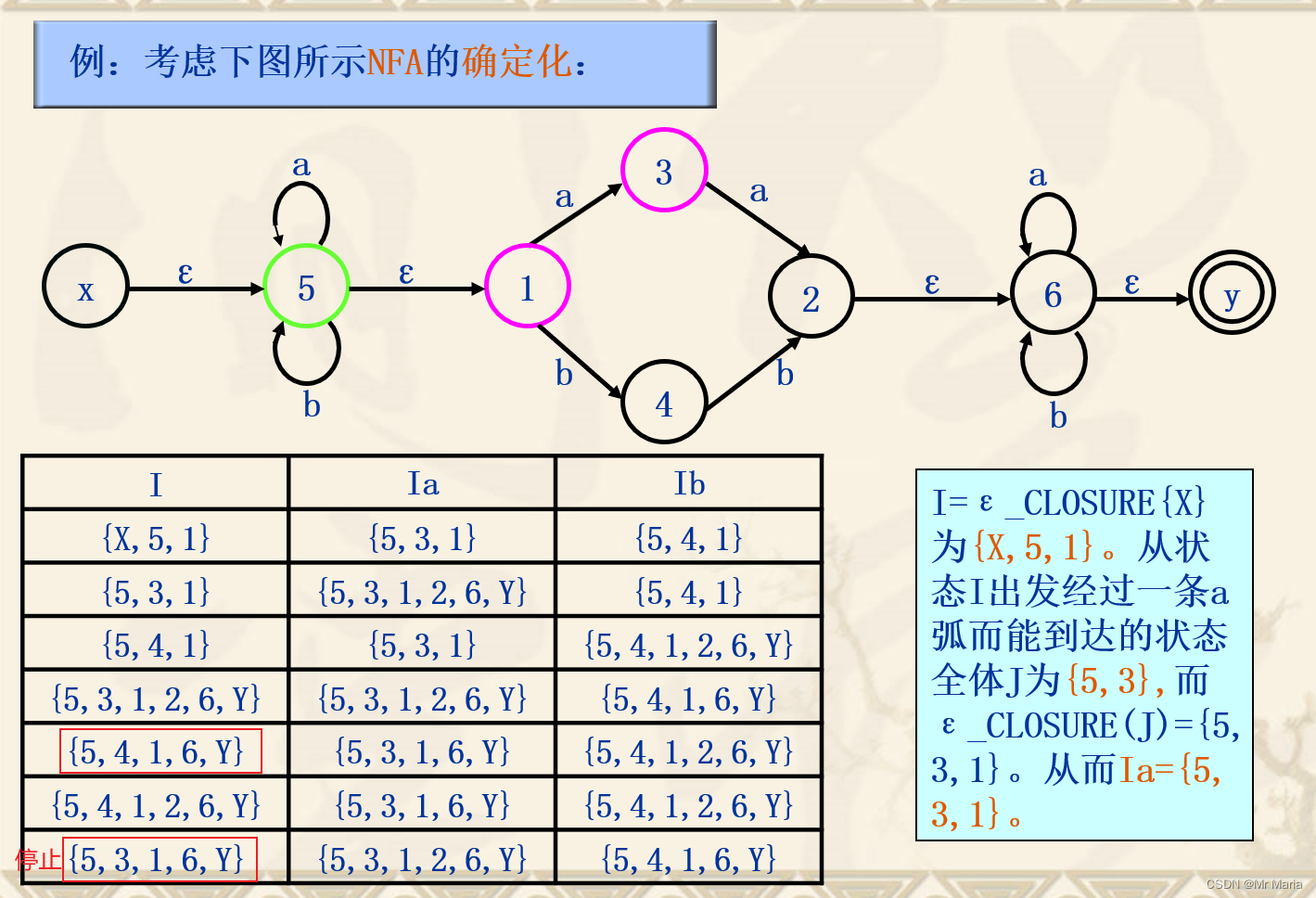
2、重新命名表里的状态,画DFA

状态等价



第四章 自顶向下语法分析方法
1、相关概念
- first集

- Follow集

- Select集

2、LL(1)文法

1、LL(1)文法的判别

2、判断LL(1)文法的步骤

3、对文法进行等价交换

提取左公共因子

消除左递归




LL(1)分析

例题整理
第二章
1、设有文法G[S]:
S?A
A?B|IF A THEN A ELSE A
B?C|B+C|+C
C?D|C*D|*D
D?x|(A)|- D
求文法的非终结符集合和终结符集合
非终结符集合={S, A, B, C, D}
终结符集合={IF, THEN, ELSE, +, *, x, (, ), -}
2、消除文法G[A]中的多余规则。
G[A]:
A?Bcd|dD
B?AB|b
C?c
D?AD|DB
E?Da|Eb|e
由于有关D的规则推导不出终结符号串,有关C和E的规则不可到达,所以化简后的文法为
A?Bcd
B?AB|b
3、设有文法G[S]:
S?aAb
A?BcA|B
B?idt|e
请问下列符号串是否为文法的句子或句型,如果是,请画出语法树。
①aidtcBcAb
②aidtccb
③ab
④abidt
①②③能由文法识别符号S推导出,且②③均由终结符号组成,所以①②③是句型,②③还是句子。对识别符号S仅有一条右部为aAb的规则,推导出的符号串的最右部不可能是t,所以④不可能是句型,也不可能是句子。(语法树略)
4、设有文法G[S]:
S?bTc|a
T?R
R?R/S|S
请问bR/bTc/bSc/ac是否为该文法的句型?若是,请画出该句型的语法树,并分析其短语、直接短语和句柄。


5、已知文法G[Z]:
Z?aZbZ|aZ|a
证明该文法是二义的。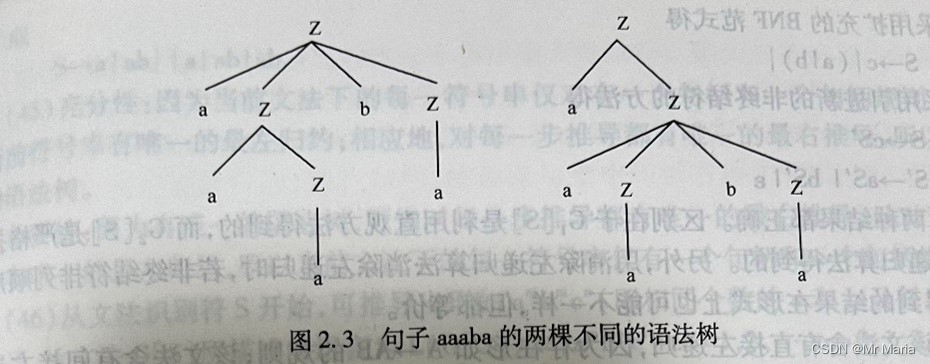
6、给出描述语言L(G)={a2nbn|n31}的2型文法。

7、试给出描述语言L(G)={a2m+1bm+1|m30}è{a2mbm+2|m30}的文法。

第三章


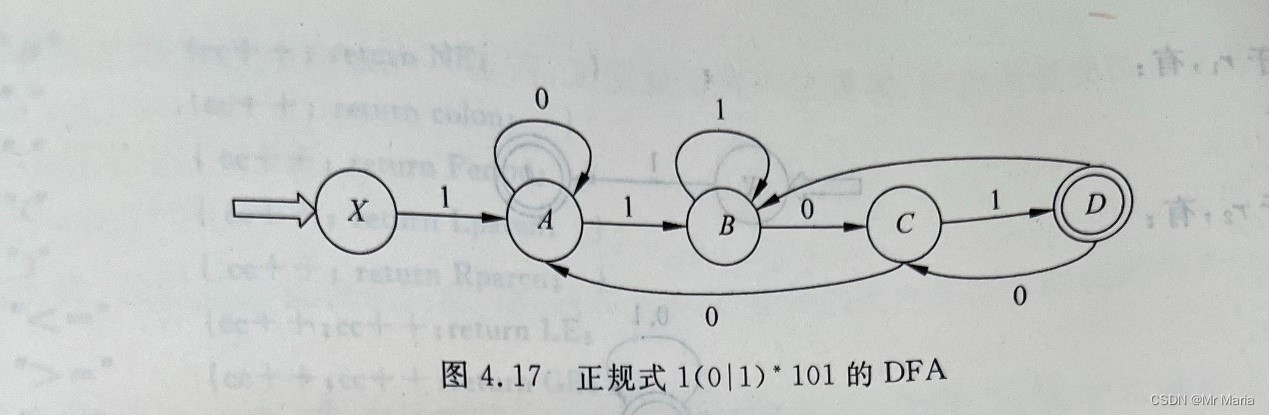
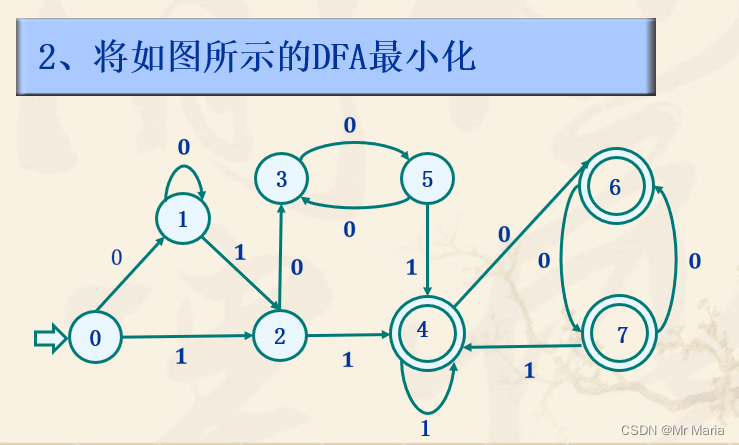


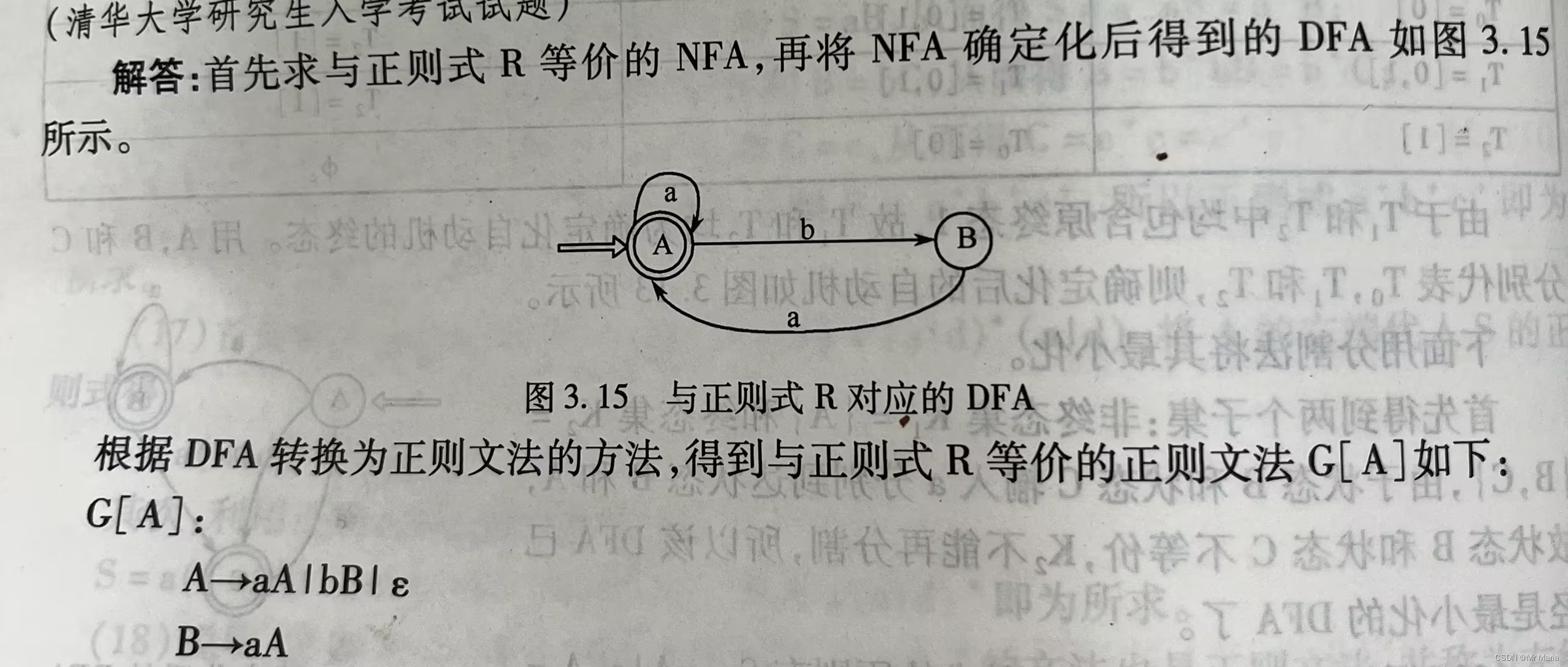
3、字母表∑={a,b}上的正则式R=(ba|a)*,请给出与正则式R等价的正则文法。
思路:1. 求与正则式R等价的NFA;2. 将NFA确定化得到DFA;3. 根据DFA转换为正则文法的方法,得到与正则式等价的正则文法。
至少使用两种不同的形式表示法描述由7/9的一切精度的近似值组成的集合。
提示:
7/9是一个近似值,约等于0.77777…,实际考察如何表示出符号串“0.77777…”。
找出该符号串的特点,可以采用正规文法、正则式及有穷自动机三种方法进行描述。

第四章



第五章
第六章

A4整理
1、正规式转正规文法

2、NFA转DFA(NFA确定化)
1、列表

直到某一行的结果全部在第一列出现时结束
2、重新命名表里的状态,画DFA
3、正规式转NFA
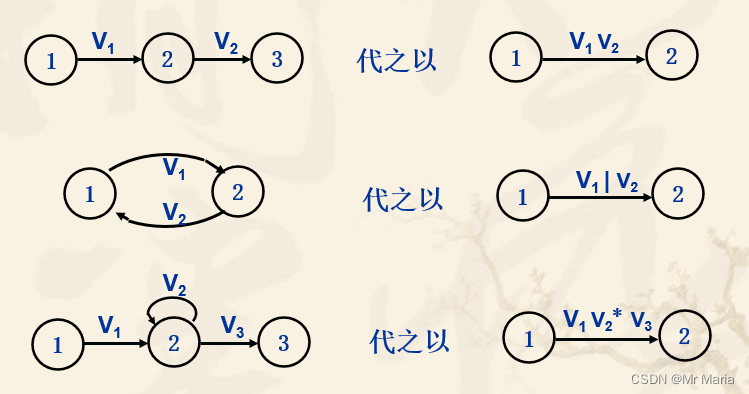
4、正规式转DFA
步骤:
- 正规式转NFA
- NFA确定化
5、DFA最小化
1、
2、找出终态集和初态集,然后分区,去重
3、重新命名表里的状态,画DFA
6、提取左公共因子
7、消除左递归
1、直接左递归

2、间接左递归
通过代入法,变为直接左递归
求first集、follow集、select集
- first集

- follow集

- Select集

判断是不是LL(1)文法
如果交集为空,不是;反之,是LL(1)文法
LL(1)预测分析表



构造语言的文法
文法G[S]=(VN,VT,P,S)
规约推导
最右推导:规范推导
最左规约:规范规约
文法->状态转换图->等价文法
分析语言,画状态转换图
LR(0)分析
项目的分类:
- 移进项目,形如A->a.ab(圆点后面是终结符)
- 待约项目,形如A->a.Bb(圆点后面为非终结符)
- 归约项目,形如A->a. (圆点在最右端的项目)
- 接收项目,形如S’->a.(S’->a为拓广文法)
判断LR(0)文法
识别活前缀中无冲突项目(移进–归约冲突,归约–归约冲突)
LR(0)分析表
- 拓广文法(当S只在产生式左边产生时不用拓广)
- 识别活前缀的DFA
慢慢顺圆点,当圆点后面是非终结符的时候继续往下顺 - 画分析表


SLR(1)文法
判断SLR(1)文法
- DFA中存在冲突(移进–归约,归约–归约)
- 存在冲突的I里面的归约项目左部的FOLLOW集交移进项目的输入符号为空
SLR(1)分析表
对每个归约项目A->a,求FOLLOW(A)得到的输入处填rn,其余同LR(0)分析一样
LR(1)文法
FIRSTVT和LASTVT的求法
FIRSTVT
- S->aB… FIRSTVT(S)={a}
- T->T,S FIRSTVT(S)={,}
- S->Q FIRSTVT(S)=FIRST(Q)
LASTVT - S->Bb… LASTVT(S)={a}
- T->T,S LASTVT(T)={,}
- S->Q LASTVT(S)=LAST(Q)
算符优先分析表的构造方法

特殊的:
- A->bC b<FIRSTVT?
- A->Bc LASTVT(B)>c

算符优先文法
- 如果一个问发的任何产生式右部都不含两个相继(并列)的非终结符,即不含有如下形式的产生式右部:…QR…
- 任意两个算符之间不存在多余一种的优先关系
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 什么是CI/CD?如何在PHP项目中实施CI/CD?
- 深入解析线程安全的Hashtable实现
- java?志体系
- 网络市场中的品牌推广:面向新一代数字原住民的挑战与机遇
- 掌握使用CXF快速开发webservice服务和生成client端技能
- 【源码+数据库】基于SSM的图书管理系统
- 探索音乐创作的新境界——PreSonus Studio One Pro 6
- 查看ios 应用程序性能
- 探索JDK 17:Java世界的最新突破
- 首席技术官CTO的具体职责表述十篇